RNN(Recurrent Neural Network)循环神经网络。
对于CNN来说,比如图像处理,它逐渐从局部空间抽象到全局空间,有一种空间层次感,通道可以与空间一起卷积,也可以分开卷积。同时由于卷积权重共享,它可以减少参数。
对RNN来说,它擅长处理序列问题,也就是输入中存在依赖的情况,比如预测下一个词语(N对N),情感分类(N对1),encoder-decoder(如seq2seq,N对M)等。
本文力求简洁,仅做概要总结。
1,简单RNN分析

如图,这里以N对N为例,X为输入,y为输出,h为隐藏状态。
假设输入X_t对应权重矩阵为U,隐藏状态h_t-1对应的的权重为W,输出y_t对应的权重为V,这里U,W,V一般对各个时刻t来说是共享的。
对于t时刻,有以下公式:

其中第一个激活函数一般为tanh或relu等,第二个一般为softmax。第一式以矩阵方式运行,提高效率。
TensorFlow调用:
tf.nn.rnn_cell.BasicRNNCell( num_units, activation=None,# type string reuse=None, name=None, dtype=None, **kwargs, )
BPTT(back-propagation through time):反向传播
t时刻的损失为:

求和,求偏导:


如果我们以tanh作为激活函数,则中间项
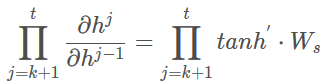
由于tanh函数偏导小于1,多次连乘导致“梯度消失”,如果采用relu激活,导数为1容易导致“梯度爆炸”。
解决梯度爆炸:通过梯度裁剪,容易处理
解决梯度消失:下面将要介绍的LSTM
2,LSTM(长短期记忆)
LSTM通过门的操作来实现信息的选取,遗忘门通过一个sigmoid激活函数对上一个细胞状态c_t-1进行更新,再加上输入门的新信息。
可以看到,上面水平线中,只有与门的2个交换操作,以及一个CEC(常量误差传播子,权值为1的自连接,一个线性激活,保证误差传递而不会发生梯度消失或爆炸)。
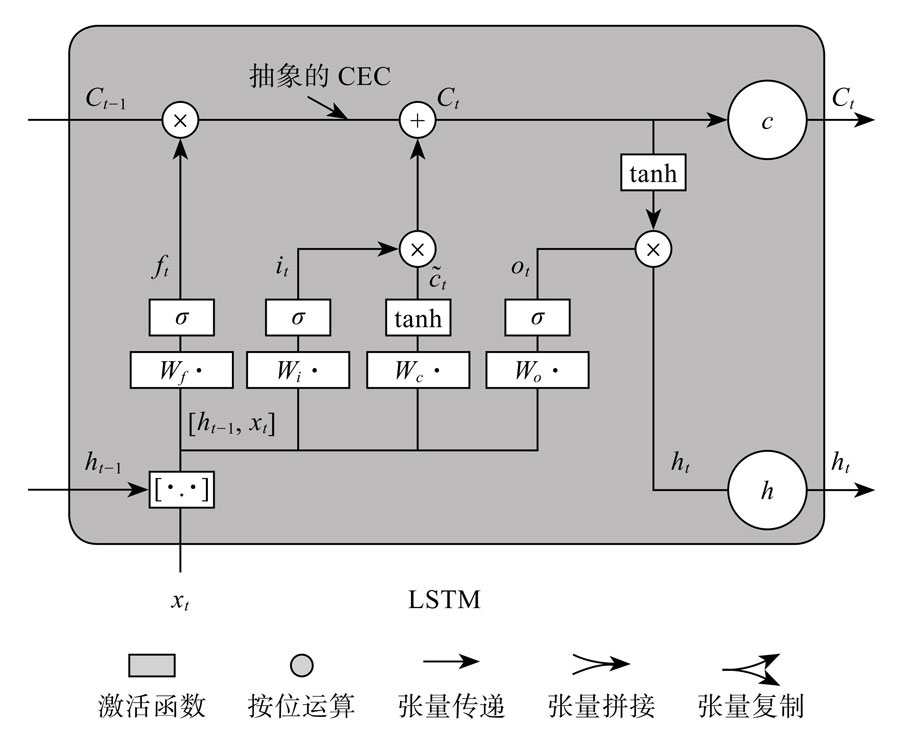
相关公式为:
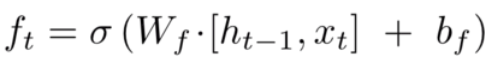
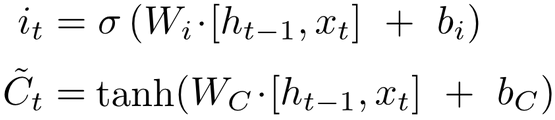


TensorFlow实现:
tf.nn.rnn_cell.BasicLSTMCell( num_units, forget_bias=1.0,#Ger et al等在2000年提出,遗忘门偏置为1使得LSTM更加健壮。 state_is_tuple=True, activation=None, reuse=None, name=None, dtype=None, **kwargs, )
3,LSTM变体
- 变体1:添加图中深色部分连接。个人理解:输入和遗忘部分加入之前的细胞状态学习可以获得更多context信息,输出门添加基于新的细胞状态信息学习。感觉上比基础LSTM要厉害些,也没增加参数。
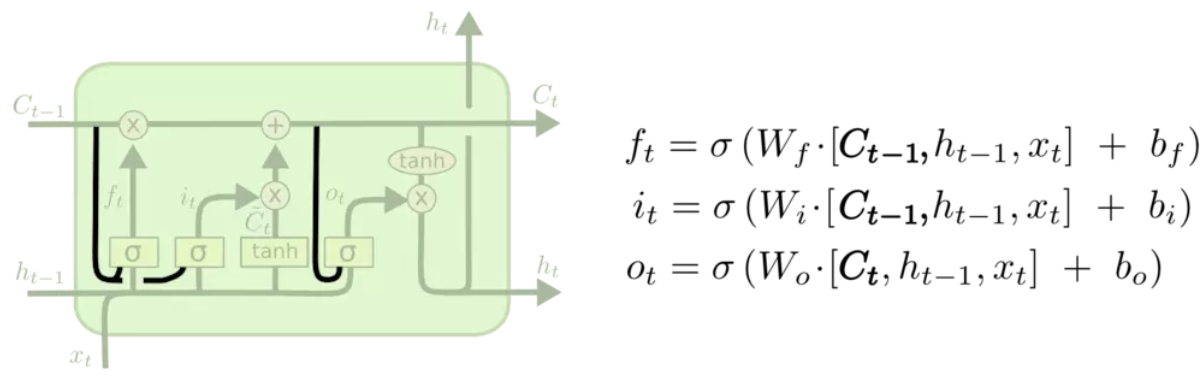
- 变体2:输入i_t直接用1-f_t表示。个人认为这样做不太恰当,需要遗忘的细胞状态信息,以及需要增加的输入信息,它们应该分开学习。共同学习存在一种矛盾:比如遗忘的部分想要降低参数,而增加的部分想要提高参数。好处是参数减少了。

- 变体3:GRU。使用2个门(重置门和更新门)代替LSTM的3个门,计算效率高,内存占用少,效果差不多,实际中比较流行。将细胞状态c与隐藏状态h合并,这个变体思想类似变体1,参数减少了不少。
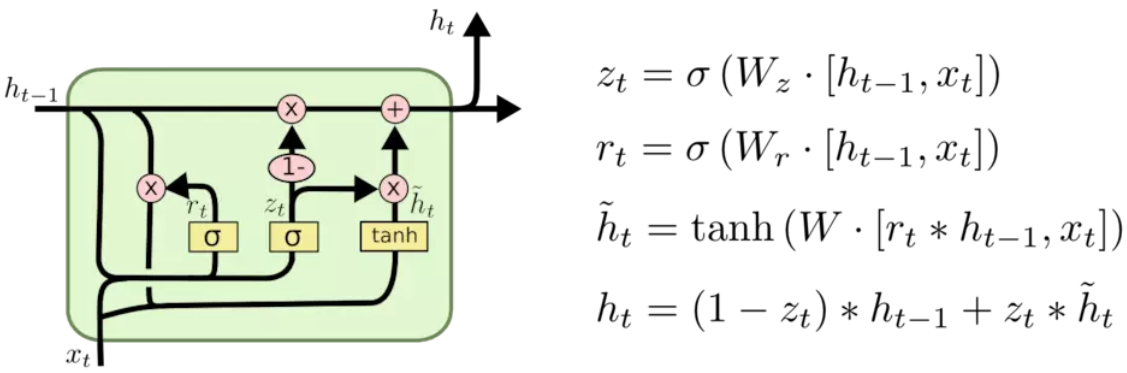
TensorFlow GRU实现
tf.nn.rnn_cell.GRUCell( num_units, activation=None, reuse=None, kernel_initializer=None, bias_initializer=None, name=None, dtype=None, **kwargs, )
参考资料
https://blog.csdn.net/zhaojc1995/article/details/80572098
《python深度学习》