1.摘要:
尽管近来生成图片模型取得了进步,成功生成了高分辨率的图片,但是在复杂的数据集中,样本的多样性仍然是难以捉摸的目标。本文尝试在大规模上训练生成对抗网络,并研究这种规模下的不稳定性。我们发现将正交正则化应用于生成器使其能够适应简单的‘截断处理,允许通过减少生成器输入的方差来精细的控制样本保真度和变化之间的权衡。
2.三个贡献:
1.增大GAN的规模能显著提升建模的效果,模型的参数比之前增大2-4倍,训练的batch尺寸增加了8倍。文章提出了两种简单而又具有一般性的框架改进,可以提高模型的收缩性,并且改进了一种正则化策略来提升条件作用,证明了这些方法能够提升性能。
2.作为这些策略的副产品,本文提出的模型变得更服从截断技巧。截断技巧是一种简单的采样方法,能够在样本的逼真性,多样性之间做显式的,细粒度的控制。
3.发现了使大规模GAN不稳定的原因,对它们进行了经验性的分析,更进一步的,作者发现将已有的和新的技巧的组合使用能够降低这种不稳定性,但是完全的训练只有在巨大的性能代价下才能获得

3.背景
生成对抗网络由一个生成器和一个判别器组成,前者的作用是根据随机噪声数据生成逼真的随机样本,后者的作用是鉴别样本是真实的还是生成器生成的。在最早的版本中,GAN训练时的优化目标为达到极大值-极小值问题的纳什平衡。当用于图像分类任务时,G和D一般都是卷积神经网络。如果不使用一些辅助性的增加稳定性技巧,训练过程非常脆弱,收敛效果差,需要精细设计的超参数和网络结构的选择以保证效果。
近期的研究工作集中修改初始的GAN算法,使它更稳定。其中一种思路是修改训练的目标函数以确保收敛。另外一种思路是通过梯度惩罚或归一化技术对D进行限定,这两种方法都是在抵抗无界的目标函数的使用,确保任意的G,D都能提供梯度。
与我们工作很相关的是谱归一化,它强制D的lipschitz连续性,这通过对他们的最大奇异值进行运行时动态估计,以此对D的参数进行归一化而实现。另外,还包括逆向动力学,对主奇异值方向进行自适应正则化。文献[1]分析了G的的雅克比矩阵的条件数,发现GAN的表现依赖于此条件数。文献[2]发现将谱归一化作用于G能够提高稳定性,使得训练算法每次迭代时能够减少D的迭代次数。本文对这些方法进行了进一步分析,以弄清GAN训练的机理。
另外一些工作聚焦在网络结构的选择上。SA-GAN增加了一种称为self-attention的模块来增强G,D的能力。ProGAN通过使用逐步增加的分辨率的图像训练单个模型。
条件GAN为gan增加了类信息,作为生成器和判别器的输入,类信息可以采用one hot编码,和随机噪声拼接起来,作为G的输入。另外,可以在批量归一化层中加入。在类中也加入了类别信息。
4.评价指标:
生成图片的质量
生成图片的多样性
IS:
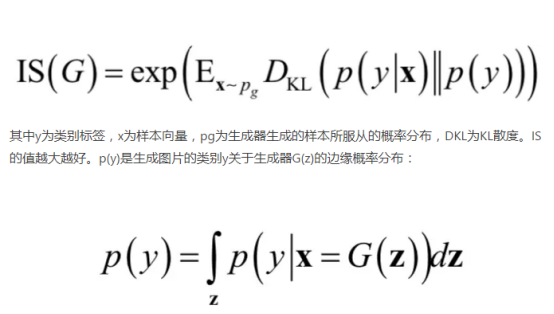
如果生成图片只有一种,那么生成图像的IS依然会很高,这是IS的缺点。而FID相较于IS更适合用于图片生成质量的评价,与IS不同,越小的值意味着更好的生成图片的质量以及更丰富的图片的多样性。在所有生成的图像仅为一种类别时,其取值将会很高。

5.增大GAN的规模
本文重点探讨增大模型的规模,增大batch的尺寸来获得性能上的提升。作为基础模型,选用了SA-GAN,使用hing loss目标函数。通过类条件归一化为G提供类信息,通过Projection为D提供类信息。优化器的设置与文献[4]相同,对G使用了谱归一化。G每迭代一次,D迭代两次。为了进行评估,利用了G的权重移动平均值,利用正交初始化,在所有设备上以G为单位计算bathNorm统计信息,而不是按设备计算。
一开始通过对基线模型增加batch大小,发现这样做有很大的好处。作者推断这是因为batch size增大之后,每个batch中的数据覆盖到的模式更多,能为生成器和判别器提供更好的梯段。但是,单纯的增加batch size带来了非常明显的副作用,迭代次数较少的情况下,效果反而更好,如果继续训练,训练过程不再稳定,并出现梯度塌陷的现象。
接下来,我们每一层增加50%的宽度(通道数),模型的参数大约增加了一倍,导致了IS%21的提升,增加深度,并没有得到改善,解决这一问题采用的是一个不同的残差块结构。
将类嵌入c应用到G的conditional batchnorm层包含大量的权重,本文选择共享的类嵌入,线性投影到各个层的gains和biases,在减少了计算需求和内存需求的情况下,训练速度提升了37%,另外,还使用了层次隐变量空间,具体做法是将噪声向量送入到G的多个层中,而不只是输入层。使用这种方法可以使得不同分辨率不同层级的特征被噪声向量直接影响。
6.使用截断技巧在真实性和多样性之间做折中
(在输入噪声上改进)
生成器的输入一般使用正态分布或者均匀分布的随机数,本文采用了截断技术,对正太分布的随机数进行了截断处理,实验发现这种方法的结果最好。对此直观的解释是,如果网络的随机噪声输入的随机数变动范围越大,生成的样本在标准模板上变动就越大,因此样本的多样性就越强,但真实性可能会降低。首先用截断的正太分布N(0,1)随机数产生噪声向量z,具体做法是如果随机数超出已定义范围,则重新采样,使得其落在这个区间里。这种做法称为截断技巧,将向量z进行截断,模超过某一指定阈值的随机数进行重采样,这样可以提高单个样本的质量,但代价是降低了样本的多样性。一些较大的模型不适合截断,当输入截断噪声时会产生饱和。为了解决这个问题,试图调节G的光滑性来增强对截断的适应性,从而使z的整个空间映射到良好的输出样本。

7.总结
实验结果发现,现有的GAN技巧已经足以训练大规模的,分布式的,大批量的模型。尽管这样,训练时还是容易坍塌,实现时,需要提前终止。
8.分析
8.1生成器的不稳定性
本文着重对小规模时稳定,大规模时不稳定的问题进行分析。在训练的过程中监测一系列权重,梯度和损失,寻找一种可能预示训练崩溃开始的指标,我们发现每个权重矩阵的前三个奇异值信息量是最大的,可以使用Alrnoldi迭代法有效的计算它们,该方法扩展Miyato等人的使用的幂迭代法到附加奇异向量和值的估计。但是在有些层表现不好,其谱规范在训练过程中不断增长,并且在崩溃时爆炸。为了确定这种病理是否是崩溃的原因或仅仅是一种症状,我们研究了对G施加额外条件作用以明确对抗光谱爆炸的效果。首先,我们直接将每一个权重的第一个值奇异值正则化,其次,用部分奇异值分解对最大特征值进行阶段处理,给定权重矩阵w,它的第一个奇异向量u0,v0,σclamp为σ0截断后的值。权重的更新公式:
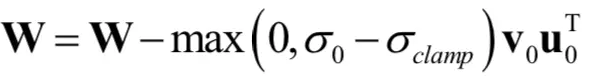
我们发现有没有谱规范都对阻止奇异值的增加和爆炸有影响,但是即使在这种情况下,提升了性能,没有阻止训练倒塌。这个证据表明条件G能提升稳定性,但是不能确保稳定性,还需要分析D。
8.2判别器的不稳定性