10.1 栈和队列
栈和队列都是动态集合, 栈(stack)是后进先出, 队列(queue)是先进先出;
栈
栈就相当于垒盘子, 盘子可以放到橱柜中,每次想要往外拿盘子的时候只能从最上面开始拿; 即后进先出
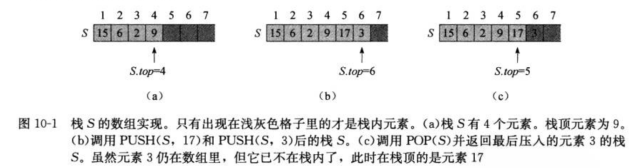
如下图,可以用一个数组 S[1..n]来实现一个最多可容纳n个元素的栈. 该数组有一个属性S.top, 指向最新插入的元素, 栈中包含的元素为S[1..S.top], 其中S[1]是栈底元素, S[S.top]是栈顶元素. 当S.top = 0时, 栈中不包含任何元素, 栈为空. 如果试图对一个空栈执行弹出操作, 则栈下溢(underflow), 如果S.top超过了n, 则栈上溢(overflow);
栈的主要操作有Stack_Empty(查询是否为空) / Push(入栈) / Pop(出栈)
伪代码:
查询是否为空
Stack_Empty(S) if S.top == 0 return True else return False
入栈
Push(S,x) if S.top != n S.top += 1 S[S.top] = x else error "overflow"
出栈 出栈是不用指定元素的, 因为栈只能Pop出最顶端的元素
Pop(S) if Stack_Emypty(S) error "underflow" else S.top -= 1 return S[S.top+1]
队列
队列就像排队等待一样, 按照顺序出入; 可以用queue[n]来实现存储n个元素的队列, 该队列有一个属性queue.head 指向队头元素, queue.tail 指向下一个元素将要插入的位置. 队列中的元素存放在位置 queue.head, queue.head+1, ... , queue.tail-1. 要判断队列是否为空是个重点, 因为当 head == tail 时,可能是空也可能为满. 因此我们可以提前定义一个tag,来帮助我们判断.
队列的主要操作有Queue_Empty(判断队列是否为空) / Enqueue(入队) / Dequeue(出队)

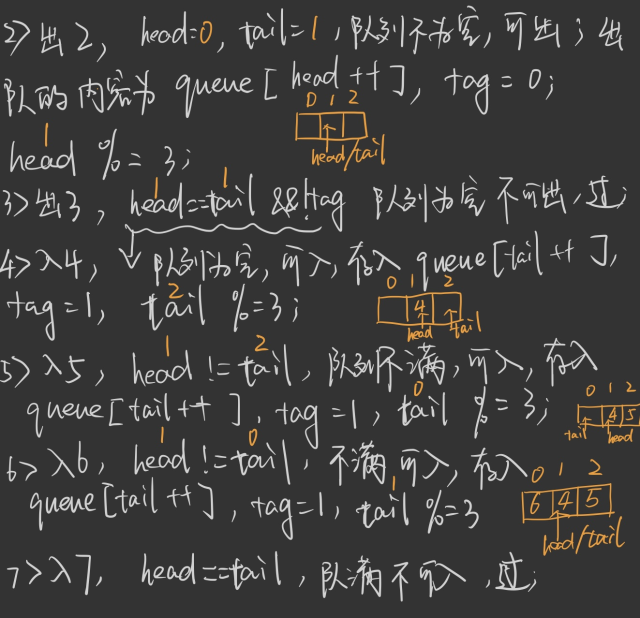
伪代码
判断队列是否为空
Queue_Empty(Q) if head == tail && tag return False else if head == tail && !tag return True
入队
n 为 Q的长度 Enqueue(Q,x) if head == tail && tag return "overflow" else { Q[tail++] = x tail %= n tag = 1 }
出栈
n 为 Q的长度 Dequeue(Q) if head == tail && !tag return "underflow" else { head = (head+1) % n tag = 0 }
10.2链表
链表其实和数组很像, 但是与数组不同的是, 链表的顺序是由各个对象里的指针决定的. 链表中每一个对象都由一个关键字key和两个指针: next 和 prev. 具体说明, 我们假设 x 为链表中的一个元素, 那么x.next 就指向下一个元素, x.prev 指向前一个元素. 如果 x.next指向为空, 说明x为链表的尾(tail); 同理, 如果x.prev指向为空, 那么x为链表的头(head).
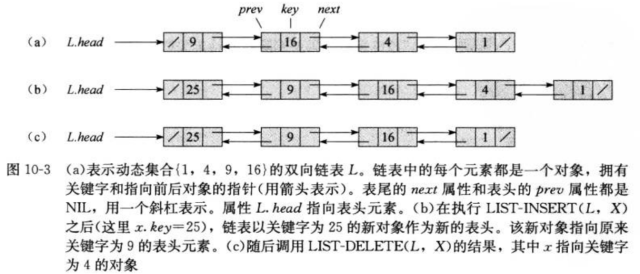
链表的形式有单链接/双链接/已排序/未排序/循环和非循环的. 其中, 单链接的链表省略每个元素中的prev指针; 循环链表表头元素的prev指针指向表尾元素, 而表尾元素的next指针则指向表头元素.
基本操作有List_Search(搜索)/List_Insert(插入)/List_Delete(删除)
搜索, 这里就采用简单的线性搜索方法, 对于List_Search(L, k) , 查找链表L中, 第一个关键字为k的元素, 并返回指向该元素的指针.
List_Search(L, k) x = L.head // 从头开始查找 while x != Null && x.key != k x = x.next // 没有找到且不是最后一个元素就一直往下找 return x
如果链表中有n个对象, 时间复杂度最坏情况下为O(n), 需要遍历所有元素
插入(只考虑插入到前端的情况) 时间复杂度O(1)
List_Insert(L, x) x.next = L.head if L.head != Null L.head.prev = x L.head = x x.prev = Null
删除
将一个元素x 从链表中移除, 需要给定一个指向x的指针, 然后通过修改一些指针, 将x"删除出"该链表. 如果要删除具有给定关键字值的元素, 则必须先调用List_Search 找到该元素. 以下伪代码, 省略了查找的过程.
List_Delete(L, x) if x.prev != Null // 如果x的前驱不为空, 那么就让它指向x的后驱元素 x.prev.next = x.next else L.head = x.next if x.next != null // 如果x的后驱不为空, 那么就让它指向x的前驱元素 x.next.prev = x.prev
如上可以看到在进行插入和删除操作的时候我们都要考虑表头和表尾的边界条件, 代码看起来就会有些繁琐. 下面就引入哨兵(sentinel)的概念, 来简化边界条件的处理.
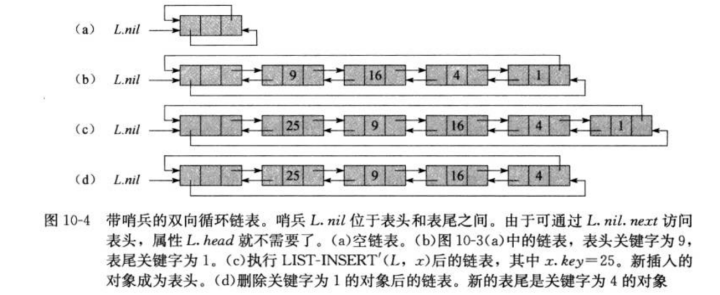
我们在链表L中设置一个对象L.nil, 它代表为Null, 但是也具有和其他对象相同的属性. 对于链表代码中出现的每一处对Null的引用, 都代之以对哨兵L.nil的引用. 这样就可以将常规的双向链表转变为一个有哨兵的双向循环链表, 哨兵位于表头和表尾之间, L.nil.next 指向表头, L.nil.prev指向表尾, 类似的, 表尾的next 属性和表头的prev属性都指向L.nil.
以下为加了哨兵改动过的代码:
搜索
List_Search'(L, k) x = L.nil.next // 从头开始查找 while x != L.nil && x.key != k x = x.next // 没有找到且不是最后一个元素就一直往下找 return x
插入
List_Insert'(L, x) x.next = L.nil.next L.nil.next.prev = x L.nil.next = x x.prev = L.nil
删除
List_Delete'(L, x) x.prev.next = x.next x.next.prev = x.prev
注意:
哨兵基本上不能降低数据结构相关操作的渐近时间界也就是时间复杂度, 它可以降低的是常数因子. 循环语句中使用哨兵的好处在于可以使代码简洁, 而非提高速度.
然而, 我们应当慎用哨兵. 因为如果在很多很短的链表中使用哨兵, 哨兵所占用的额外存储空间会造成严重的存储浪费.