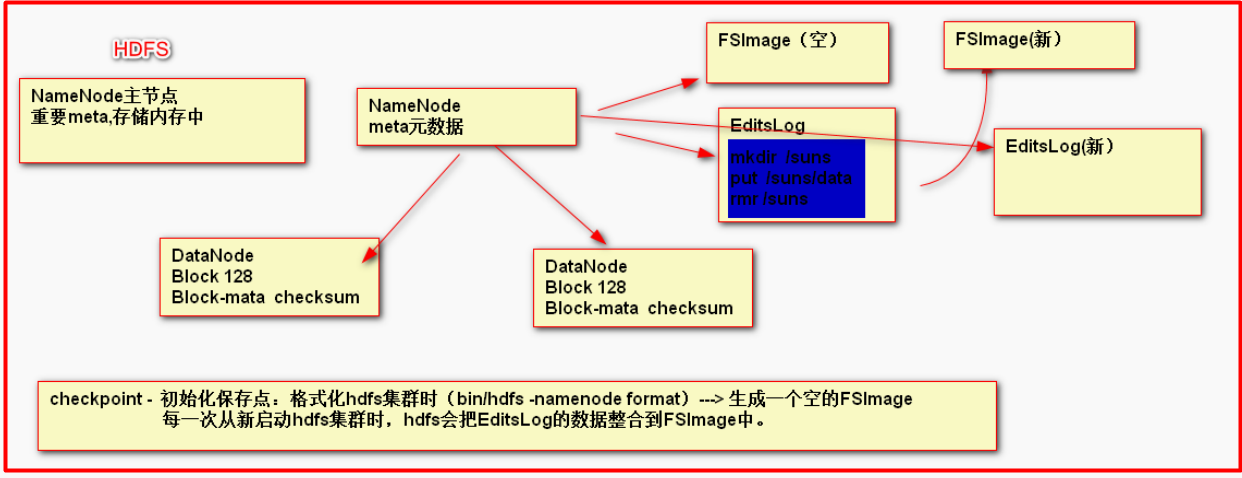
NameNode在运行时,把重要的元数据放置在内存中,如果内存出现问题,则元数据丢失,为了保证元数据安全,NameNode有对应的持久化机制,把元数据持久化到硬盘存储。
1. FSImage和EditsLog存储位置
#fsImage默认存储位置 /opt/install/hadoop-2.5.2/data/tmp/dfs/name
dfs.namenode.name.dir
#editslog默认存储位置
dfs.namenode.edits.dir
2.定制FSImage和EditsLog的存储位置
hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///xxx/xxxx</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///xxx/xxxx</value>
</property>
3. 安全模式(safe mode)
每一次启动namenode时,hdfs都需要进行FSImage和EditsLog的整合,在这个过程中,不允许用户做写操作,把这个过程称之为安全模式(safe mode),默认30秒
1. safe mode相关命令
bin/hdfs dfsadmin -safemode [enter leave get]
2. HDFS集群启动时,完成流程
HDFS集群启动 过程 (安全模式)
1,整合 FSImage和EditsLog 生成新的EditsLog 和 FSImage,由新EditsLog接收用户写操作命令
2, DataNode都需NameNode主动汇报健康情况(心跳)3秒
3, 汇报块列表 通过校验和 检查块是否可用,并定期1小时汇报。

hdfs这时才进行FSImage和EditsLog的整合但是如果服务是第一次启动,并且服务一旦启动就不会停那么FsImage
就会一直是空的,又是怎么解决这个问题。
6. 如果服务是频繁的开启那么日志文件EditsLog会有很多,又怎么处理的这个问题
7. 服务一直不关闭,EditsLog中的内容也会越来越多又是怎么解决的这个问题

自定义SecondaryNameNode 拉取数据的周期
hdfs-site.xml
dfs.namenode.checkpoint.period 3600秒
dfs.namenode.checkpoint.txns 1000000
secondaryNameNode启动方式:sbin/start-dfs.sh 或者
sbin/hadoop-daemon.sh start secondarynamenode
定制secondaryNameNode 启动的节点
hdfs-site.xml
dfs.namenode.secondary.http-address 0.0.0.0:50090
dfs.namenode.secondary.https-address 0.0.0.0:50091
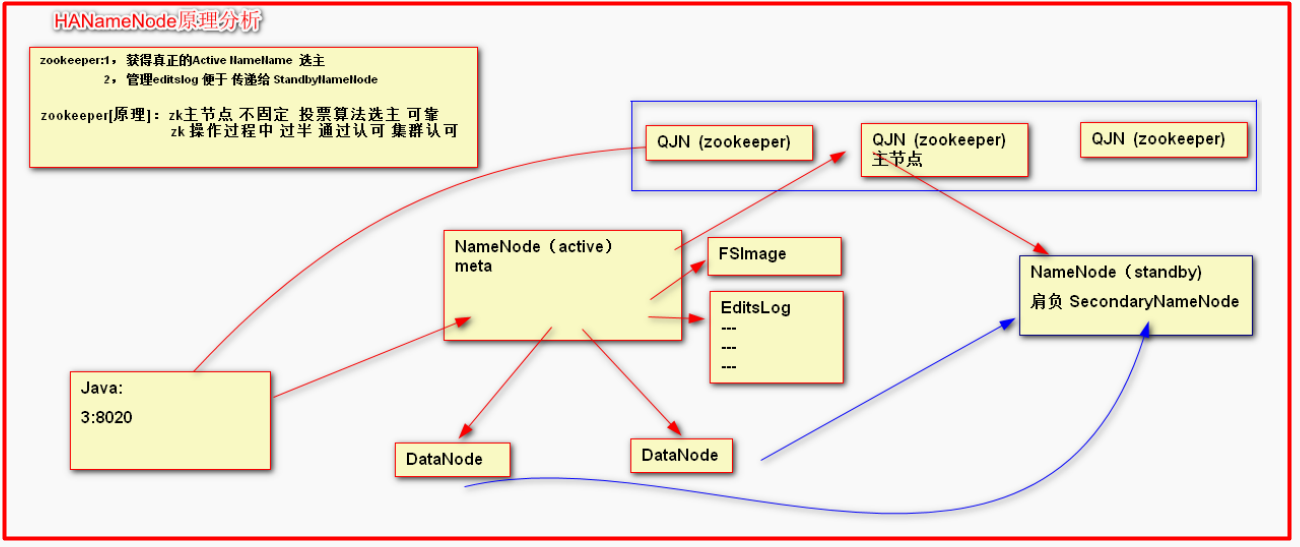
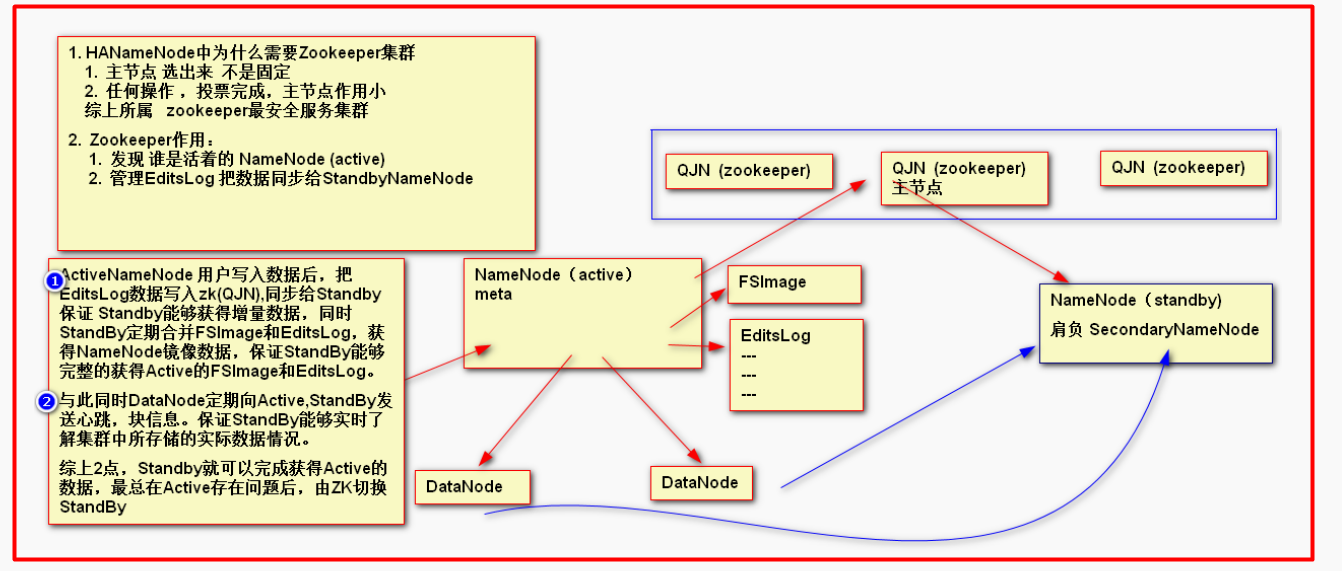
这里standBynamenode起到了两个作用一个是secondarynamenode 定期整合fsimage 和editsLog的内容和备选主节点 的作用
HANameNode集群的搭建
1. zookeeper集群
1.1 解压缩
tar -zxvf zookeeper-xxx-tar.gz -C /opt/install
1.2 创建数据文件夹
mdkir zookeeper_home(zookeeper的安装目录)/data
1.3 conf目录修改zookeeper的配置文件
修改zoo_sample.cfg 为 zoo.cfg
mv zoo_sample.cfg zoo.cfg
编辑内容
dataDir=/opt/install/zookeeper-3.4.5/data
server.0=hadoop2.baizhiedu.com:2888:3888
server.1=hadoop3.baizhiedu.com:2888:3888
server.2=hadoop4.baizhiedu.com:2888:3888
1.4 zookeeper_home/data
在data下建立一个文件myid
第一台服务器:myid文件 输入 0 对应 hadoop2.baizhiedu.com 代表的是hadoop2这个服务
第二台服务器:myid文件 输入 1 对应 hadoop3.baizhiedu.com 代表的是hadoop3这个服务
第三台服务器:myid文件 输入 2 对应 hadoop4.baizhiedu.com 代表的死hadoop4这个服务
1.5 scp -r 命令 同步集群中所有节点 并 修改对应的myid文件
scp -r zookeeper-3.4.5/ [email protected]:/opt/install/
scp -r zookeeper-3.4.5/ [email protected]:/opt/install/
zookeeper 选取主节点的原理:
假设有三台服务:当第一台启动的时候自认为是主节点这时剩下的不给他投票,第二台启动说编号比第一台大给自己投一票第一台认可也投一票
第三台服务启动,编号最大给自己投一票但是现在没有服务为他投票所以第一次充当namenode的往往是中间那一台。
1.6 主节点 ssh 其他节点
1.7 启动zk服务
bin/zkServer.sh start | stop | restart
bin/zkServer.sh status 查看集群状态 【必须集群完整启动完成】
bin/zkCli.sh [leader] 访问必须要在leader这个节点执行
zookeeper是一个树状结构
2. HA-HDFS集群
清空 data/tmp/ 目录下的内容
2.1 core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value> //ns 这个名字可以随便起
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/install/hadoop-2.5.2/data/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop2.baizhiedu.com:2181,hadoop3.baizhiedu.com:2181,hadoop4.baizhiedu.com:2181</value>
</property>
2.2 hdfs-site.xml
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop2.baizhiedu.com:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop2.baizhiedu.com:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop3.baizhiedu.com:8020</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop3.baizhiedu.com:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop2.baizhiedu.com:8485;hadoop3.baizhiedu.com:8485;hadoop4.baizhiedu.com:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/install/hadoop-2.5.2/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,如果ssh是默认22端口,value直接写sshfence即可 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
配置hadoop2这台后不要忘记了还有两台也要配置
scp -r etc/hadoop/ [email protected]:/opt/install/hadoop-2.5.2/etc/
scp -r etc/hadoop/ [email protected]:/opt/install/hadoop-2.5.2/etc/
2.3 yarn-env.sh添加如下内容
export JAVA_HOME=/usr/java/jdk1.7.0_71
首先启动各个节点的Zookeeper,在各个节点上执行以下命令:
bin/zkServer.sh start
在某一个namenode节点执行如下命令,创建命名空间
bin/hdfs zkfc -formatZK (主节点hadoop2)
在每个journalnode节点用如下命令启动journalnode
sbin/hadoop-daemon.sh start journalnode (journalnode同步EditsLog 三个hadoop 都要启动部署在zk中的namenode)
在主namenode节点格式化namenode和journalnode目录
bin/hdfs namenode -format ns
在主namenode节点启动namenode进程
sbin/hadoop-daemon.sh start namenode
在备namenode节点执行第一行命令,这个是把备namenode节点的目录格式化并把元数据从主namenode节点copy过来,并且这个命令不会把journalnode目录再格式化了!然后用第二个命令启动备namenode进程!
bin/hdfs namenode -bootstrapStandby (hadoop3)
sbin/hadoop-daemon.sh start namenode
在两个namenode节点都执行以下命令
sbin/hadoop-daemon.sh start zkfc
在所有datanode节点都执行以下命令启动datanode
sbin/hadoop-daemon.sh start datanode
日常启停命令
sbin/start-dfs.sh
sbin/stop-dfs.sh
apache官方网站上提供的二进制文件,是基于32为操作系统进行编译的,不适合与64位操作系统,自己编译
我在一台纯净版的虚拟机上安装的

2. 把他们解压
安装jdk
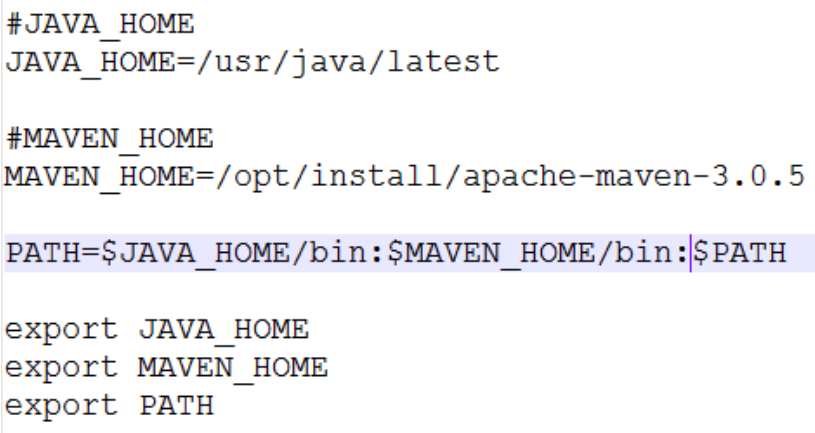
1. 配置JDK环境变量
vi .bash_profile
/etc/profile

- source /etc/profile 或者 source .bash_profile 来生效一下
使用javac -version 或者java -version来检测是否安装成功
2. 安装需要的依赖工具
安装Linux 系统包
yum install wget
yum install autoconf automake libtool cmake
yum install ncurses-devel
yum install openssl-devel
yum install lzo-devel zlib-devel gcc gcc-c++
3. 下载: protobuf-2.5.0.tar.gz
解压:tar -zxvf protobuf-2.5.0.tar.gz
编译安装:
进入安装目录,进行配置,执行命令 ./configure
安装命令:
make
make check
make install
4. 安装Maven
解压:maven
修改环境变量 etc/profile
在maven 的setting.xml 的配置文件中加入镜像操作
<mirror>
<id>alimaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</mirror>
通过mvn 验证maven是否安装成功
5. 安装 findbugs
下载: findbugs-1.3.9.tar.gz
解压: tar –zxvf findbugs-1.3.9.tar.gz
设置环境变量(/etc/profile):
加在文件末尾就行
export FINDBUGS_HOME=/opt/modules/findbugs-1.3.9
export PATH=$PATH:$FINDBUGS_HOME/bin
执行命令:source /etc/profile
验证:findbugs -version
在maven目录下执行:export MAVEN_OPTS="-Xms256m -Xmx512m" 设置maven的内存
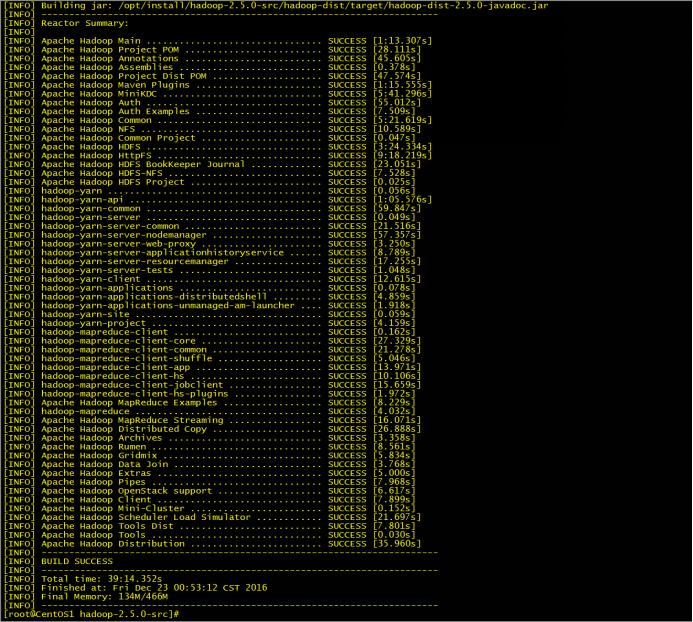
在hadoop的源码包中执行:mvn package -DskipTests -Pdist,native -Dtar 执行在Hadoop2.5.0的源码包中\
获得编译好的hadoop :
hadoop_src_home/hadoop-dist/target
执行成功的截图,如果你没有下载成功那么久多执行几次:mvn package -DskipTests -Pdist,native -Dtar
如果好几次都没有成功那么就把maven重新装一遍 或者换一个低版本的maven
把自己编译的lib包 替换hadoop二进制 lib 包 设置HADOOP_HOME环境变量
当你整个过程结束后在你的/root/.m2 目录下会产生一个repository 里面都是你下载好的依赖

在你的hadoop源码包中会有一个target/hadoop-2.5.2.tar.gz

总结出现的问题:
1. maven版本过高
2. 错误
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-antrun-plugin:1.7:run (dist) on project hadoop-hdfs-httpfs:
An Ant BuildException has occured: exec returned: 2
[ERROR] around Ant part ...<exec dir="/home/pory/workplace/hadoop-2.4.1-src/hadoop-hdfs-project/hadoop-hdfs-httpfs/target"
executable="sh" failonerror="true">... @ 10:134 in /home/pory/workplace/hadoop-2.4.1-src/hadoop-hdfs-project/hadoop-hdfs-httpfs/target/antrun/build-main.xml
[ERROR] -> [Help 1]
这是因为/home/pory/workplace/hadoop-2.4.1-src/hadoop-hdfs-project/hadoop-hdfs-httpfs/downloads目录下的文件没有下载完全,
可以手动下一份匹配版本的文件放在下面,在http://archive.apache.org/dist/tomcat/tomcat-6/v6.0.36/bin/
然后重新执行命令
编译完成后使用:
首先就是要上传hadoop的安装包,解压,
hadoop32位和64位最大的区别就是native这个文件夹的内容不同其他都一样
所以如果想要切换只需要改变native下的内容就可以了。

需要应用64为的hadoop替换32位hadoop /opt/install/hadoop-2.5.2/lib/native 的内容
# 替换一定在linux系统中直接替换。将我们上面编译好的文件内容来一次替换。


1.1 hadoop-env.sh
exportJAVA_HOME=/usr/java/jdk1.7.0_71
1.2 core-site.xml
<!--用于设置namenode并且作为Java程序的访问入口--->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop.baidu.com:8020</value>
</property>
<!--存储NameNode持久化的数据,DataNode块数据——>
<!--手工创建$HADOOP_HOME/data/tmp-->
命令:mkdir -p data/tmp
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/install/hadoop-2.5.2/data/tmp</value>
</property>
1.3 hdfs-site.xml
<!--设置副本数量默认是3但是单节点测试,改成1-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
1.4 mapred-site.xml
<!--yarn与MR相关-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
1.5 yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
1.6slaves 配置自己是告诉虚拟机我本机即做nameNOde 也做dataNode
hadoop2.baizhiedu.com

2. java 编码
1. HDFS shell 命令
2. Java API
Configuration
FileSystem
IOUtils
Path
#后续 Spark完成类似的工作
MapReduce是Hadoop体系下的一种计算模型(计算框架),主要功能是用于操作,处理HDFS上的大数据级数据。
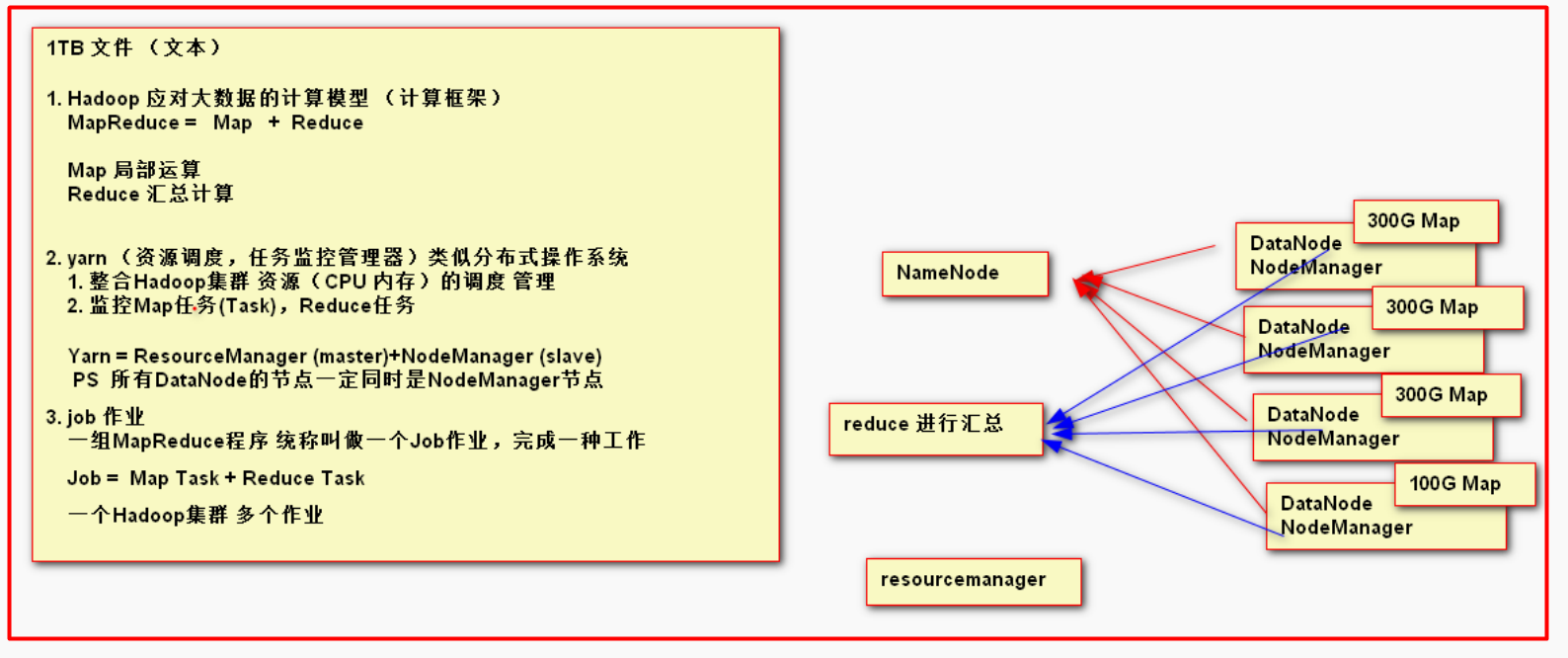
因为数据运算是要加载进内存中进行运算而作为TB级的数量级大数据在大多数情况下是不被普及的尽管有TB级的内存但是仍旧不广泛使用
所以需要小数量级的内存才能进行运算,而每一个datenode 都由自己独立的cpu 所以就很容易想到局部运算在进行汇总的思想 ,所以在mapreduce中,map就是用于局部运算而
reduce就是进行汇总计算。然而下一个问题又出现了,每一个datanode的服务器型号或者大小可能不同,cpu的内核和线程也可能不同为了不造成资源的浪费,或者能够打破物理硬件上的局限性
便采用了逻辑上的整体资源分配数据在实际上的物理上的地址可能不是连续的但是在逻辑上是连续的,而所谓这个资源总体分配的总工程师就是resourcemanager ,他不仅可以负责资源的调度
而且还能顺便负责监控任务的作用,他为什么能够担负起监控map reduce 任务的作用呢,实际上主要是因为作为资源的总工程师是要知道资源的基本信息的,而这些基本信息是有每一个nodeManager
来进行上报的,这样在map 或者reduce在进行计算的时候如果出现了问题 ,nodemanager 上报,和resourcemanager就能够及时的知道。
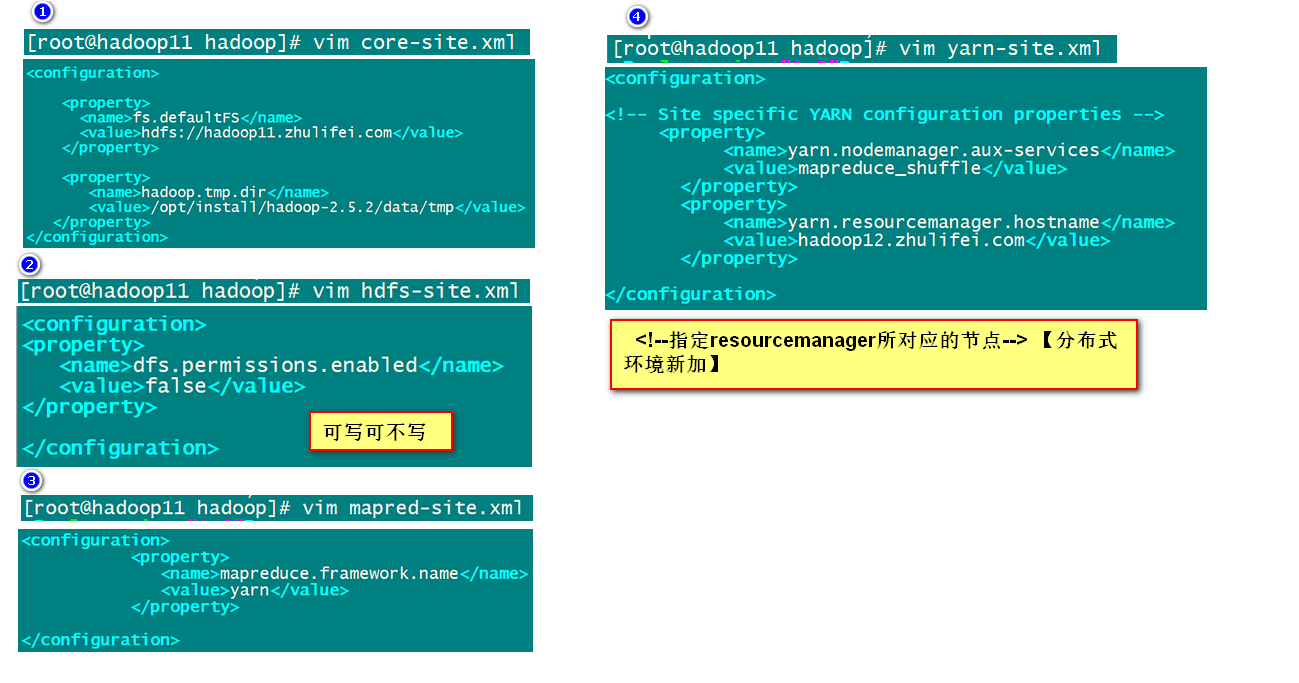
1. 配置相关的配置文件 etc/hadoop
yarn-site.xml mapred-site.xml
2. 启动yarn
2.1 伪分布式
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
2.2 集群方式
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定resourcemanager所对应的节点--> 【分布式环境新加】
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop12.baizhiedu.com</value>
</property>
slaves
datanode同时又是nodemanager
同步集群的每一个节点
scp -r hadoop [email protected]:/opt/install/hadoop-2.5.2/etc/
scp -r hadoop [email protected]:/opt/install/hadoop-2.5.2/etc/
正常启动hdfs
namenode格式化
sbin/start-dfs.sh
集群方式的yarn启动
建议 namenode 不要和 resourcemanager放置在同一个点
# ssh相关的机器,避免yes
在集群环境下,yarn启动的命令,需要在resourcemanager所在的节点执行
sbin/start-yarn.sh
sbin/stop-yarn.sh
验证:
jps看进程
http://hadoop12.baizhiedu.com:8088
Mapreduce 程序开发步骤:

Mapreduce第一个程序分析

MapReduce 第一个程序开发
1. 准备工作上传文件:

2. java代码需要的pom.xml
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.5.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.5.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-yarn-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-common</artifactId>
<version>2.5.2</version>
</dependency>
编码:
# MapReduce编程中 一定会涉及到序列化的操作 ,基本进行了封装
String ---- Text
int ---- IntWritable
Long -----LongWritable
# 打成jar,上传到yarn集群(resourcemanager)
bin/yarn jar hadoop-mr-baizhiedu.jar
hadoop实现一个job作业的的java代码:



/** * Hadoop 自身提供一套可优化网络序列化传输的基本类型 * Integer IntWritable * Long LongWritable * String Text */ public class MyMapreduce { /** * LongWritable 偏移量 long,表示该行在文件中的位置,而不是行号 * Text map阶段的输入数据 一行文本信息 字符串类型 String * Text map阶段的数据字符串类型 String * IntWritable map阶段输出的value类型,对应java中的int型,表示行号 */ // 构建map类 public static class Mymaper extends Mapper<LongWritable,Text,Text,IntWritable>{ /* key = k1 //行首字母偏移量 表示该行在文件中的位置,而不是行号 value = line 行数据 context 上下文对象 */ @Override public void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException { // suns xiaohei String line = v1.toString(); String[] words = line.split("\t"); //分词 for (String word : words) { // suns 1 // xiaohei 1 Text k2 = new Text(word); IntWritable v2 = new IntWritable(1); //写出 context.write(k2,v2); } } } /** * Text 数据类型:字符串类型 String * IntWritable reduce阶段的输入类型 int * Text reduce阶段的输出数据类型 String类型 * IntWritable 输出词频个数 Int型 * reduce函数的输入类型必须匹配map函数的输出类型。 */ public static class MyReduce extends Reducer<Text,IntWritable,Text,IntWritable> { /** * key 输入的 键 * value 输入的 值 * context 上下文对象,用于输出键值对 */ @Override public void reduce(Text k2, Iterable<IntWritable> v2s, Context context) throws IOException, InterruptedException { int result = 0; for (IntWritable v2 : v2s) { result+=v2.get(); } Text k3 = k2; IntWritable v3 = new IntWritable(result); context.write(k3,v3); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "MyFirstJob"); // 作业以jar包形式运行 job.setJarByClass(MyMapreduce.class); // InputFormat Path path = new Path("/src/data"); TextInputFormat.addInputPath(job,path); // map job.setMapperClass(Mymaper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // reduce job.setReducerClass(MyReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 输出目录一定不能存在,有MR动态创建 Path out = new Path("/dest2"); FileSystem fileSystem = FileSystem.get(conf); fileSystem.delete(out,true); TextOutputFormat.setOutputPath(job,out); // 运行job作业 job.waitForCompletion(true); } }
当然,这个只是普通的java代码,如果在这运行那么我们在linux上搭建的环境也就没有意义了。
所以要把项目打成jar包放在linux上的jdk中
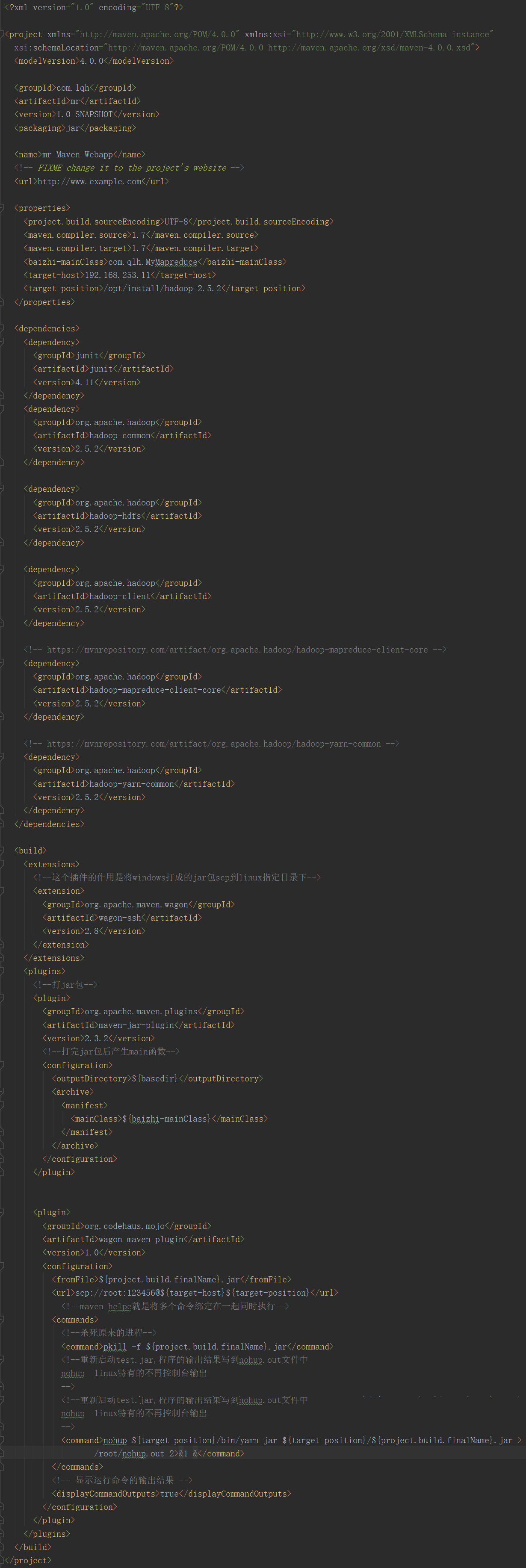
还要下载一个插件


1. 创建一个模板module
1. 引入相关jar的坐标
2. 创建Java代码在本项目的根下:mvn --settings F:\apache-maven-3.3.9\conf\settings.xml archetype:create-from-project
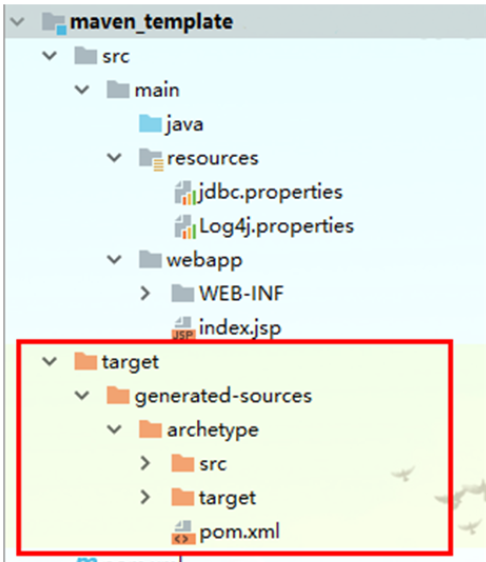
2.复制骨架的坐标(便于后续的安装)
<groupId>com.baizhiedu</groupId>
<artifactId>hadoop-test-archetype</artifactId>
<version>1.0-SNAPSHOT</version>
3.安装骨架
cd target\generated-sources\archetype
mvn clean install
4.创建项目并引入骨架
需要指定骨架的坐标,来源第二步。
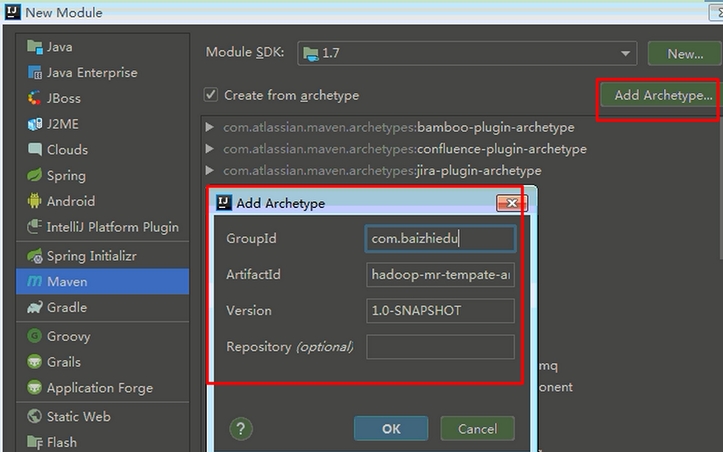
下面是一个简易图:

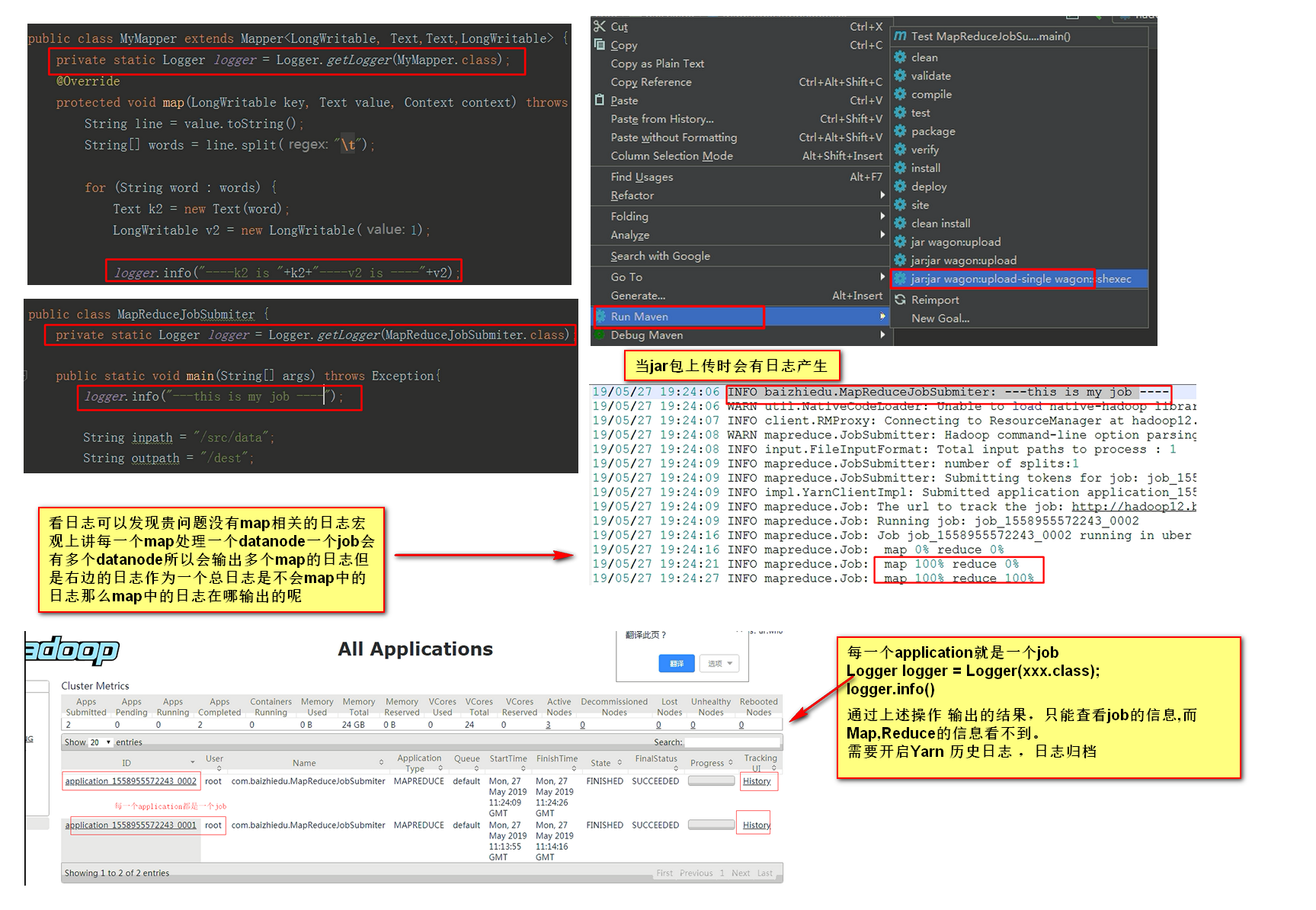
1.建议MR代码中通过Log4进行调试
xxxxxxxxxx Logger logger = Logger(xxx.class);
logger.info()
通过上述操作 输出的结果,只能查看job的信息,而Map,Reduce的信息看不到。需要开启Yarn 历史日志 ,日志归档
2. yarn集群中如何开启历史日志,日志归档
1. 配置文件
mapred-site.xml
指定历史服务器所在的位置及端口
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop11.zhulifei.com:10020</value>
</property>
指定历史服务器所在的外部浏览器交互端口号及机器位置
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop11.zhulifei.com:19888</value>
</property>
yarn-site.xml 日志聚合
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--指日志保存的时间 单位秒-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
要进行同步和其他两台服务器同步到集群的每一个节点
2. 启动进程
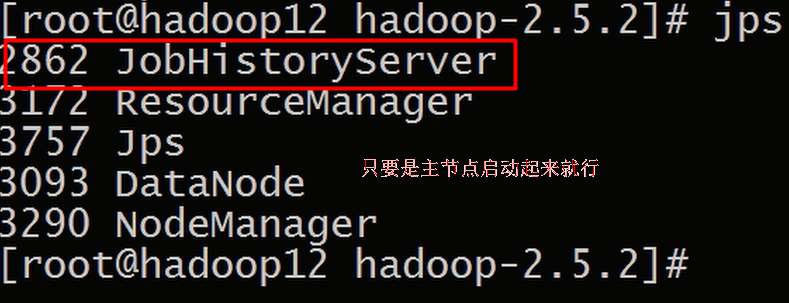
sbin/mr-jobhistory-daemon.sh start historyserver
sbin/mr-jobhistory-daemon.sh stop historyserver
日志聚合:

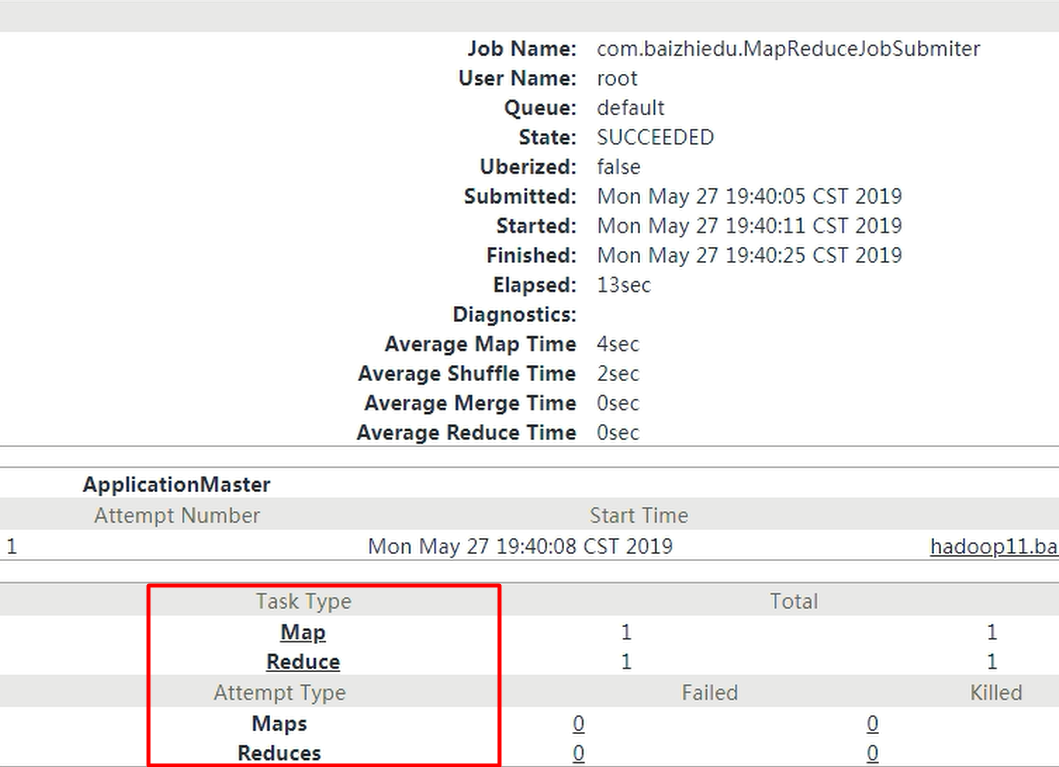
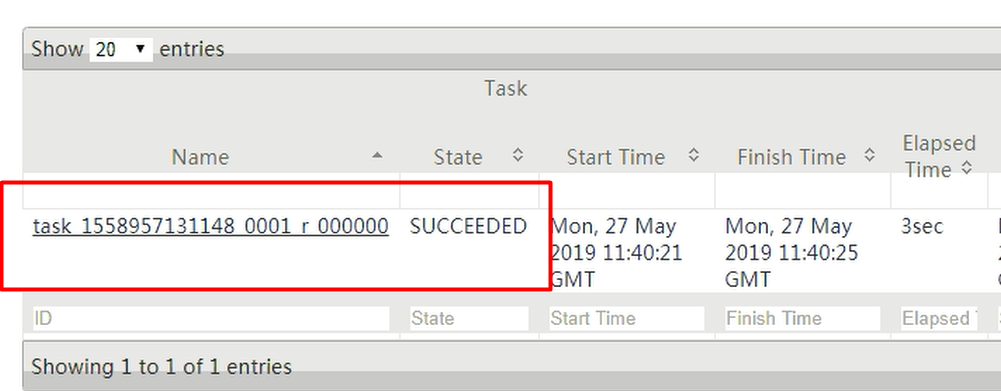
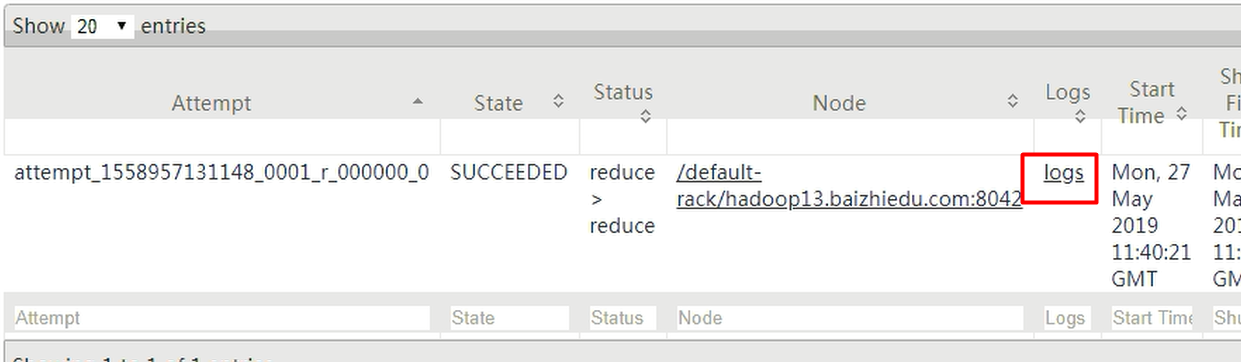

实战:
应用shell脚本 解决
首先关闭日志聚合:
1. etc/hadoop/yarn-env.sh
export YARN_LOG_DIR=~/logs/yarn
export YARN_PID_DIR=~/data/yarn
2 . 创建脚本
if [ $# -le 0 ]
then
echo 缺少参数
exit 1
fi
logtype=out
if [ $# -ge 1 ]
then
logtype=${2}
fi
for n in `cat /opt/install/hadoop-2.5.2/etc/hadoop/slaves`
do
echo ===========查看节点 $n============
ssh $n "cat ~/logs/yarn/userlogs/${1}/container_*/*${logtype}|grep com.baizhiedu"
done
3. 运行脚本:
1. 修改脚本权限
2. ./scanMRLog.sh application_1558968514803_0001
需求:网站经营数据的分析 (pv,uv)值
MapReduce中,Map与Reduce会进行跨JVM,跨服务器的通信,所以需要MapReduce中的数据类型进行序列化
Writable
Compareable
WriableCompareable (既能排序又能序列化)
IntWritable
LongWritable
FloatWritable
Text
NullWritable
#自定义hadoop的数据类型?
程序员自定义的类型 实现Writable Comparable(compareto方法 int 0 1 -1 )
直接实现WritableCompareble
write(DataOutput out)
readFields(DataInput in)
compareto()
equals
hashcode
toString
注意:自定义类型中 toString方法 返回的内容,将会位置输出文件的格式
11111111111111111111111111111111111111
11111111111111111111111111111111111111111111111111