我们的原数据可能是json格式
通常我们的数据格式是text格式:如 id,username,age,gender
如果我们遇到是json格式 如 {"id":1,"username":"ruozedata","age",2,"gender":"unknown"}
如下图:
我们的步骤是
json data ==> hive table ==> sql
上传rating.json文件到/home/hadoop中
create table rating_json(json string);
load data local inpath '/home/hadoop/rating.json' into table rating_json;
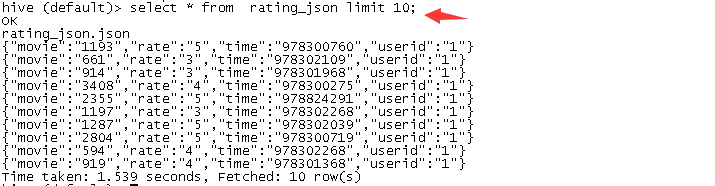
select * from rating_json limit 10;
如何将json数据拆分出来呢?使用json_tuple函数能够简单处理这种事。
select json_tuple(json,'movie','rate','time','userid') from rating_json limit 10;

select json_tuple(json,'movie','rate','time','userid') as (movie_id,rate,time,user_id) from rating_json limit 10;

数据清洗
json ==> 我们所需要的列[也就是取到我们需要的json列],字段的扩充[也就是说需要更多的字段]
raw[原始的数据] ==> width 大宽表 你后续需要的所有的字段我全部给你准备完毕
比如我们还需要下面的字段
userid,movie,rate,time,year,month,day,hour,minute,ts(yyyy-MM-dd HH:mm:ss)
input: time string
int类型 year(string date)
string类型 from_unixtime(bigint unixtime[, string format])
-
hive (temp)> select from_unixtime(1323308943,'yyyyMMdd') from dual; -
20111208
-
hive (temp)> select from_unixtime(1323308943,'yyyy-MM-dd') from dual;
-
2011- 12-08
在Hive中复制表数据,把一个表的查询结果存储起来放到一个完整的表中,用到了
create table table1_name as select filed1[,field2][,field3...] from table2_name;
根据上面的语法,我想直接把一个表的查询结果作为table2_name,看看我的写法:
create table table1_name
select * from (
select substr(login_time,0,10) as day,count(user_name) as empty_user
from table2_name
where user_name='' or user_name is null
group by substr(login_time,0,10));
上面的会报错,应为没加别名,如下加个p1就行了,应为上面的 select * from ()这个时候是需要别名的.
create table table1_name
select * from (
select substr(login_time,0,10) as day,count(user_name) as empty_user
from table2_name
where user_name='' or user_name is null
group by substr(login_time,0,10)) p1;
create table rating_width as
select
movie_id,rate,time,user_id,
year(from_unixtime(cast(time as bigint))) as year,
month(from_unixtime(cast(time as bigint))) as month,
day(from_unixtime(cast(time as bigint))) as day,
hour(from_unixtime(cast(time as bigint))) as hour,
minute(from_unixtime(cast(time as bigint))) as minute,
from_unixtime(cast(time as bigint)) as ts
from
(
select
json_tuple(json,'movie','rate','time','userid') as (movie_id,rate,time,user_id)
from rating_json
) tmp
;

后续的统计分析都是基于这个rating_width表进行
上面的统计在生产中用的比较多
下面来统计网址,在工作中也非常常见
vi /home/hadoop/url.txt
http://www.ruozedata.com/d7/xxx.html?cookieid=1234567&a=b&c=d
hive (default)> select * from url;
OK
url.url
http://www.ruozedata.com/d7/xxx.html?cookieid=1234567&a=b&c=d
Time taken: 0.217 seconds, Fetched: 1 row(s)
hive (default)>
如何将url数据拆分出来呢?使用parse_url_tuple函数能够简单处理这种事。
hive (default)> select parse_url_tuple(url, 'HOST', 'PATH', 'QUERY', 'QUERY:cookieid','QUERY:a') as (host,path,query,cookie_id,a) from url;
OK
host path query cookie_id a
www.ruozedata.com /d7/xxx.html cookieid=1234567&a=b&c=d 1234567 b
Time taken: 0.186 seconds, Fetched: 1 row(s)
统计每种性别中年龄最大的两条数据 ,面试必考
vi /home/hadoop/rownumber
5,30,tianqi,M
2,19,lisi,M
1,18,zhangsan,M
6,26,wangba,F
3,22,wangwu,F
4,16,zhaoliu,F
create table hive_rownumber(
id int,
age int,
name string,
gender string
)
row format delimited fields terminated by ',';
先根据性别分组,然后根据年龄做降序,取前2条
hive (default)> load data local inpath '/home/hadoop/rownumber' overwrite into table hive_rownumber;
hive (default)> select * from hive_rownumber;
OK
hive_rownumber.id hive_rownumber.age hive_rownumber.name hive_rownumber.gender
5 30 tianqi M
2 19 lisi M
1 18 zhangsan M
6 26 wangba F
3 22 wangwu F
4 16 zhaoliu F
Time taken: 0.159 seconds, Fetched: 6 row(s)
select id,age,name,gender,r
from
(
select id,age,name,gender,
ROW_NUMBER() over(PARTITION BY gender order by age desc) as r
from hive_rownumber
) t where t.r<=2;
显示如下:
