堆排序也是一种较为常用的排序算法。它是基于对的优先队列来实现的。要学习堆排序,就要学习优先队列,以及堆的特性。
优先队列
在很多的应用场景中,我们需要数据有序,但不需要它们全部有序,或者是不需要它们一次性有序,有序的数据时慢慢的被需要。
比如:某些事件系统中,事件有优先级。程序在处理事件时,只需要知道当前优先级最高的事件是哪个,而不用去关心排队的所有事件的顺序是什么样的。
优先队列支持两种操作:
- 删除最大(或最小)的元素
- 插入元素
依据上面的特性,我们通过将一列元素放入优先队列,并一个个删除最小的元素,就可以实现一个排序算法。堆排序这个算法就是基于堆的优先队列来实现的。
优先队列是一组接口定义,它的实现可以有很多种。我们简单介绍一下它的接口,然后介绍一下基础的实现和基于堆的实现。
接口
- 插入元素
- 删除并获取最大(最小)元素
- 队列是否为空
实现
各种实现的复杂度对比:
| 实现方式 | 插入复杂度 | 删除复杂度 |
|---|---|---|
| 有序数组 | N | 1 |
| 无需数组 | 1 | N |
| 堆 | lgN | lgN |
| 理想状态 | 1 | 1 |
数组实现
1. 有序实现
- 插入新元素的时候,将比它大的元素向后移动一格(和插入排序一样)。这样每一次插入之后都能保证数组是有序的。
- 删除元素时,删除最后一个即可。
2. 无序实现
- 插入新元素的时候,插在队列的末尾。
- 删除元素是,运行一个循环,从所有的数中找到最大的数并删除。
堆实现
数据结构二叉堆能够很好的实现优先队列的基本操作。
定义
当一颗二叉树,每一个节点的值都大等于(或小等于)它的子节点时,我们称这个二叉树为堆有序。
二叉堆是一组能够用堆有序的完全二叉树。
完全二叉树可以用数组就表示出来,而不用指针链表等结构。将二叉树的节点按照层级顺序放入到数组中即可,如:根节点放在位置1,子节点的位置放在2,3,子节点的子节点放在4、5 和 6、7,以此类推。
用数组存放二叉堆符合一个规则(假设根节点在 1),当节点的位置在 k 时,他的父节点是 k/2,他的子节点时 2k 和 2k+1。
Tips:这里并没有使用数组 0 的位置。当然可以使用,但会让子节点和父节点的计算看起来不那么直观。而且在实际的应用中,0节点可以用作哨兵,解决很多循环中的判断问题。
父节点为: (k-1)/2;子节点:2k+1,2k+2;
以这样的规则,就可以把一颗二叉树放在一个数组当中,像是下图演示的这样:
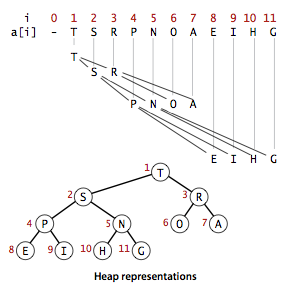 

当根节点是最大值的二叉堆,被称为最大堆;反之,称为最小堆。
在这里,我们讨论最大堆。
堆的算法
在堆的操作中,有两个操作是最底层的操作:
- 如果一个新节点加入了堆底,堆的有序性就被破坏了,我们需要从下到上恢复堆的有序性,这个操作一般叫做 heap_swim(意思是:堆元素上浮)
- 如果根节点的元素被替换成了较小的元素,我们需要从上到下的恢复堆的有序性,这个操作一般叫做 heap_sink(意思是:堆元素下沉)
堆的其他操作都依赖于这两个操作。我们先了解这两个,剩下的就简单多了。
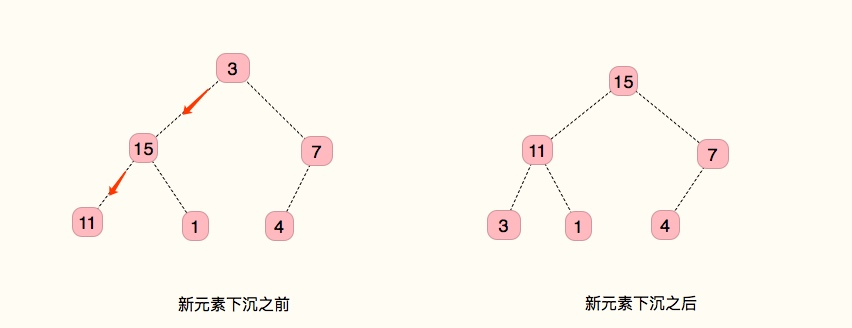
从上到下堆有序化
把要移动的节点称为 k。
算法过程:
- 将 k 同它的两个子节点中较大的比较,如果小于子节点则与子节点交换位置
- 重复上面的步骤,直到 它的子节点都比他小
- 堆有序
如下图:

实现如下:
void _heap_sink(int *a, int len, int k){
while( 2*k <= len){
int j = 2*k;
if (j < len && a[j] < a[j+1]) ++j;
if (a[k] >= a[j]) break;
swap(a, k, j);
k = j;
}
}
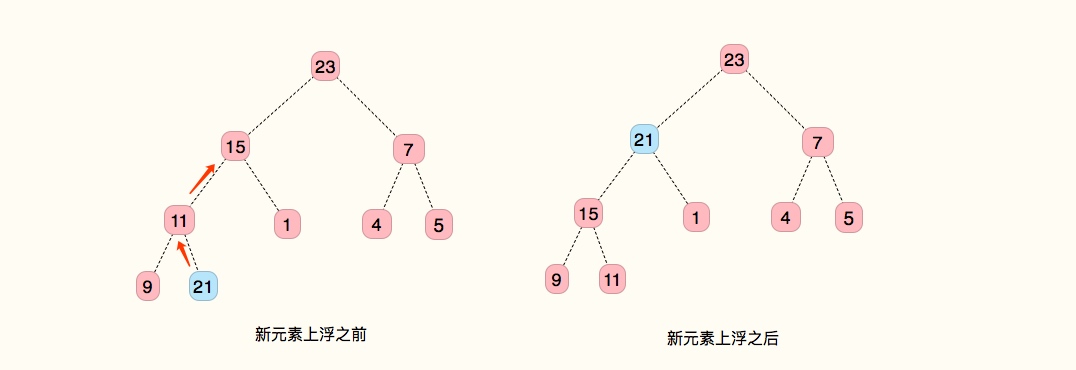
从下到上堆有序化
把要移动的节点称为 k。
算法过程:
- 将 k 同它的父节点比较,如果大于父节点,则和父节点交换位置
- 重复上面的步骤,直到 它的父节点大于它
- 堆有序
如下图:

void _heap_swim(int *a, int len, int k){
while(k > 1 && a[k/2] < a[k]){
swap(a, k/2, k);
k = k/2;
}
}
堆初始化
将一个已有的乱序数组,初始化为堆有序是非常简单的。有两种方法:
第一种使用_heap_swim,从左到右扫描一遍数组即可。将数组的每个数组都做一个上浮堆有序,则当扫描结束时,堆有序就完成了。
第二种可以减少一些操作。使用_heap_sink扫描从右到左一半的元素即可。因为我们可以跳过大小为1的子堆。
Tips: 根据完全二叉树的特性。假设节点总数是 N, 当N为奇数;则叶子节点数为: N/2,如果N为偶数,则叶子节点数为: N/2+1。所以,不管N为奇数或偶数,非叶子节点的个数为 N/2。
实现如下:
```cpp
void heap_init(int *a, int len){
for(int k = len /2; k >= 1; k--){
_heap_sink(a, len, k);
}
}
```
堆插入元素
参数 cap 表明了队列能承载的最多元素个数
参数 len 表明了队列当前的长度
int heap_insert(int *a, int len, int cap, int v){
if (len +1 > cap) {
return len;
};
a[len+1] = v;
_heap_swim(a, len, len+1);
return len+1;
}
堆删除最大的元素
删除并返回了堆中最大的元素值。此时队列的长度应该减一。
int heap_del_max(int *a, int len) {
int tmp = a[1];
swap(a, 1, len);
_heap_sink(a, len-1, 1);
return tmp;
}
堆排序
上面,我们介绍了优先队列的含义及接口。还仔细介绍了堆实现的优先队列。依靠上面的知识,再来做堆排序就非常简单了。
如果我们将一个无序的数组初始化成了一个最大堆,这样,我们每次从堆中去除元素就是有序的了(从大到小)。我们再将取出的元素从右到左放回到数组中,是不是就排好序了呢?
实现起来也非常简单:
void heap_sort(int *a, int len)
heap_init(a, len);
for(int i = len; i > 0; --i){
heap_del_max(a, i);
}
}
这里有一个小技巧:我们并不需要再给原数组赋值,因为在我们的heap_del_max将最大的数交换到了队列的末尾,正好满足我们的需求。
结尾
堆排序其实非常简单。它最难的地方在于理解二叉堆,理解二叉堆又要理解二叉树。篇幅的限制,这里没有展开讲二叉树的特性,在后续的文章中,会详细讲出二叉树的特性。
作者和出处(reposkeeper) 授权分享 By CC-SA 4.0

关注微信公众号,获取新文章的推送!
