爬虫的爬取步骤:
- 准备好我们所需要的代理IP(代理IP的获取方法见:https://blog.csdn.net/qq_38251616/article/details/79544753)
- 首先url是必要的
- 利用url进行爬取
- 将爬取爬取到的信息进行整合
- 保存到本地
具体的步骤:
- 利用代理IP和requests.get()语句获取网页
- BeautifulSoup()解析网页(BeautilfulSoup的功能可以参照这个https://www.jianshu.com/p/41d06a4ed896)
- find_all()找到相应的标签
- 用.get_text()获取标签中的内容
- urlretrieve()将图片下载到本地(如果是文字直接保存到本地文件中即可)
代码示例:
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
#获取随机ip
proxies = get_random_ip(ip_list)
req = requests.get(url=url,headers=headers,proxies=proxies)
soup = BeautifulSoup(req.text,'lxml')
targets_url_1 = soup.find('figure')
targets_url = soup.find_all('noscript')
完整代码:
'''
这是一份爬取知乎图片的教程代码,其中涉及的代理ip文件(IP.txt)可以在下面留言向我索取
'''
import requests,random,os,time
from bs4 import BeautifulSoup
from urllib.request import urlretrieve
#获取IP列表并检验IP的有效性
def get_ip_list():
f=open('IP.txt','r')
ip_list=f.readlines()
f.close()
return ip_list
#从IP列表中获取随机IP
def get_random_ip(ip_list):
proxy_ip = random.choice(ip_list)
proxy_ip=proxy_ip.strip('\n')
proxies = {'https': proxy_ip}
return proxies
def get_picture(url,ip_list):
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
#获取随机ip
proxies = get_random_ip(ip_list)
req = requests.get(url=url,headers=headers,proxies=proxies)
soup = BeautifulSoup(req.text,'lxml')
targets_url_1 = soup.find('figure')
targets_url = soup.find_all('noscript')
#保存图片链接
list_url = []
for each in targets_url:
list_url.append(each.img.get('src'))
for each_img in list_url:
#判断文件夹(图库)是否存在,若不存在则创建文件夹
if '图库' not in os.listdir():
os.makedirs('图库')
#下载图片
proxies = get_random_ip(ip_list)
picture = '%s.jpg' % time.time()
req = requests.get(url=each_img,headers=headers,proxies=proxies)
with open('图库/{}.jpg'.format(picture),'wb') as f:
f.write(req.content)
#每爬取一张图片暂停一秒防止ip被封
time.sleep(1)
print('{}下载完成!'.format(picture))
def main():
ip_list = get_ip_list()
url = 'https://www.zhihu.com/question/22918070'
get_picture(url,ip_list)
if __name__ == '__main__':
main()
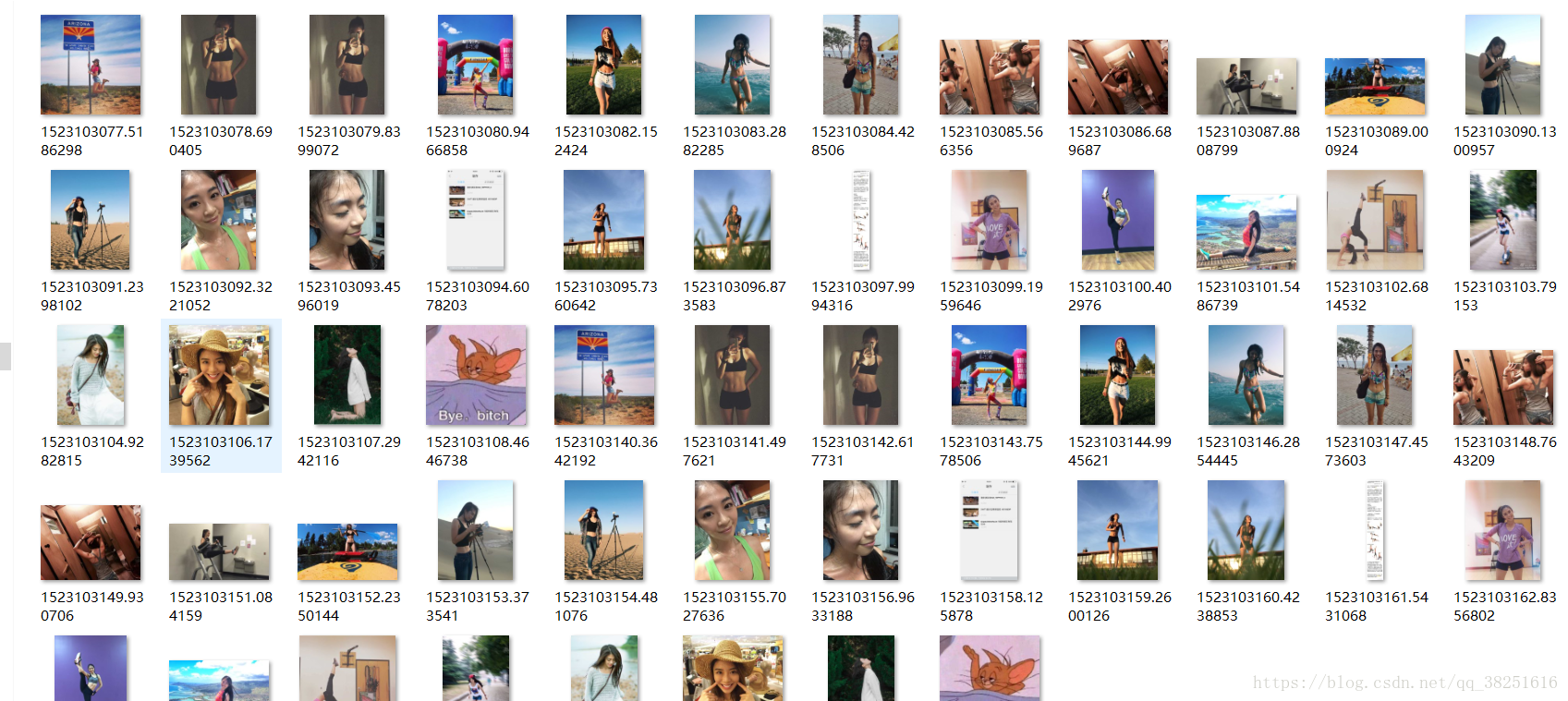
成功后的截图: