前言
领英搜索的会员列表上,一般会列出当前搜索的会员简易数据列表,如果我们要看某个会员的详细信息时需要进入二级页面进行查看。若是要采集列表上的会员信息,手动操作起来超级费时间,考虑采用自动化的方式进行采集,简化人力。
工具
Google 浏览器
tampermonkey 插件(又名:油猴子)
插件文档地址:https://www.tampermonkey.net/documentation.php?ext=dhdg#_match
实现方案:
1、获取到搜索界面上的所有人员详情地址。


var links =[]; document.querySelectorAll('.search-results__list li').forEach(function (item) { var a, href; if ((a = item.querySelector('a')) && (href = a.getAttribute('href')) && href.indexOf('/in/') != -1) { links.push({ detail: href + 'detail/contact-info/' }); } })
2、根据地址去获取对应的详情信息。这里有两种方案:
A、 使用 iframe 的方式加载详情界面,在 iframe的 load 事件中获取详情界面上的信息。
代码核心如下:
var detail_frame = document.createElement('iframe'),detailObj={},doc = document;
detail_frame.setAttribute('src',"详情地址");
detail_frame.addEventListener('load',function(){
var document = this.contentWindow.document;
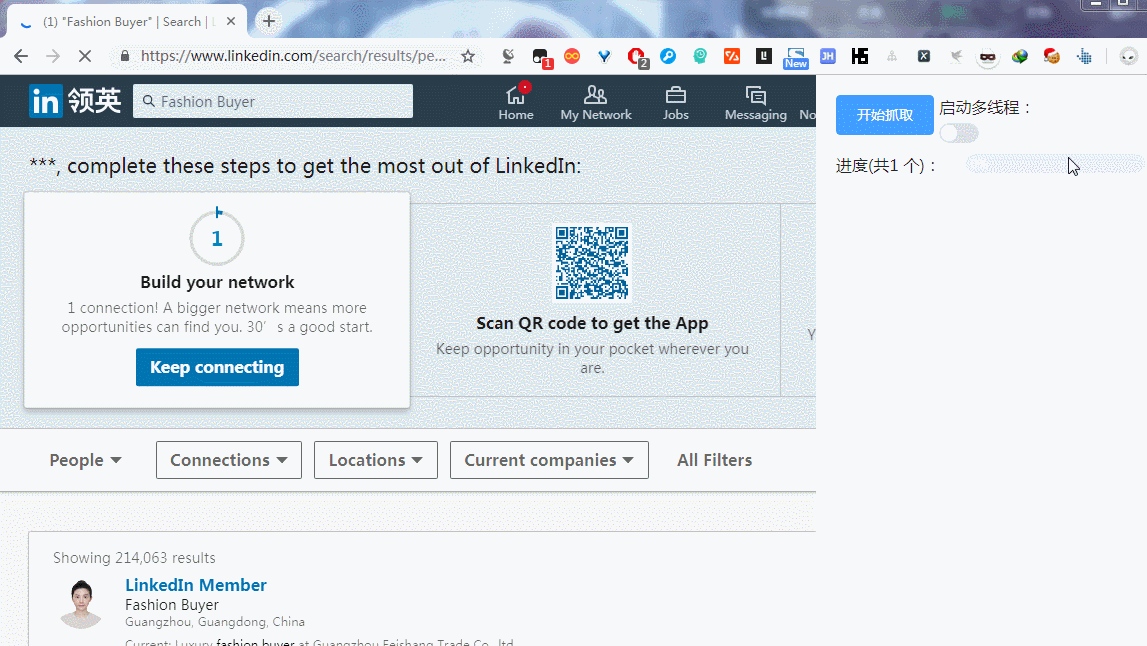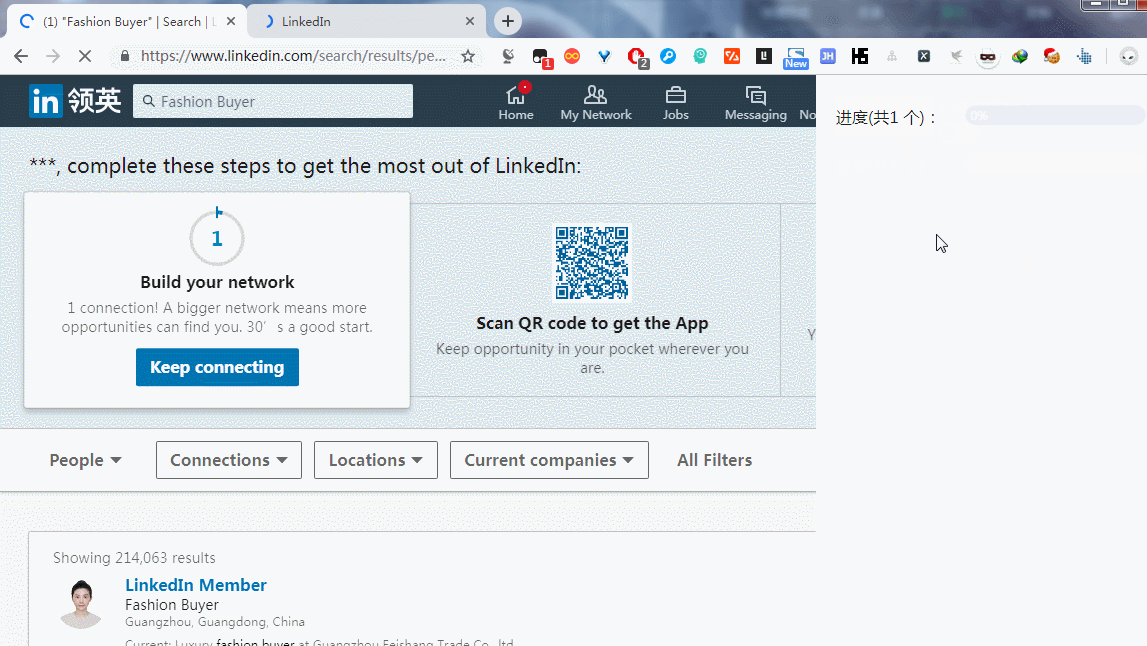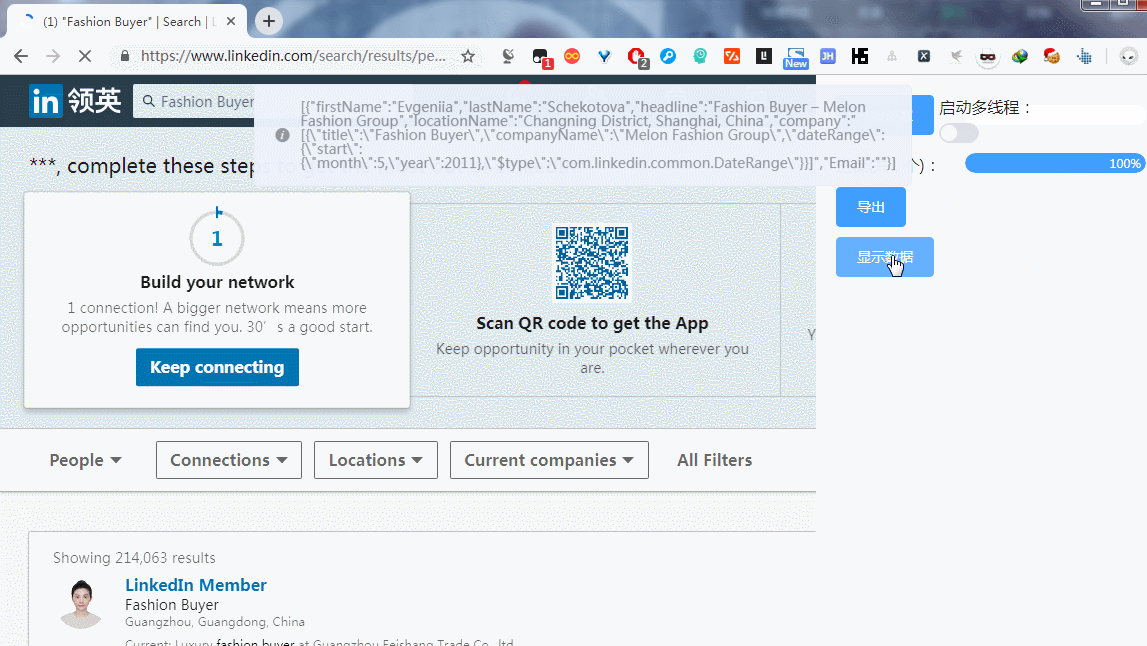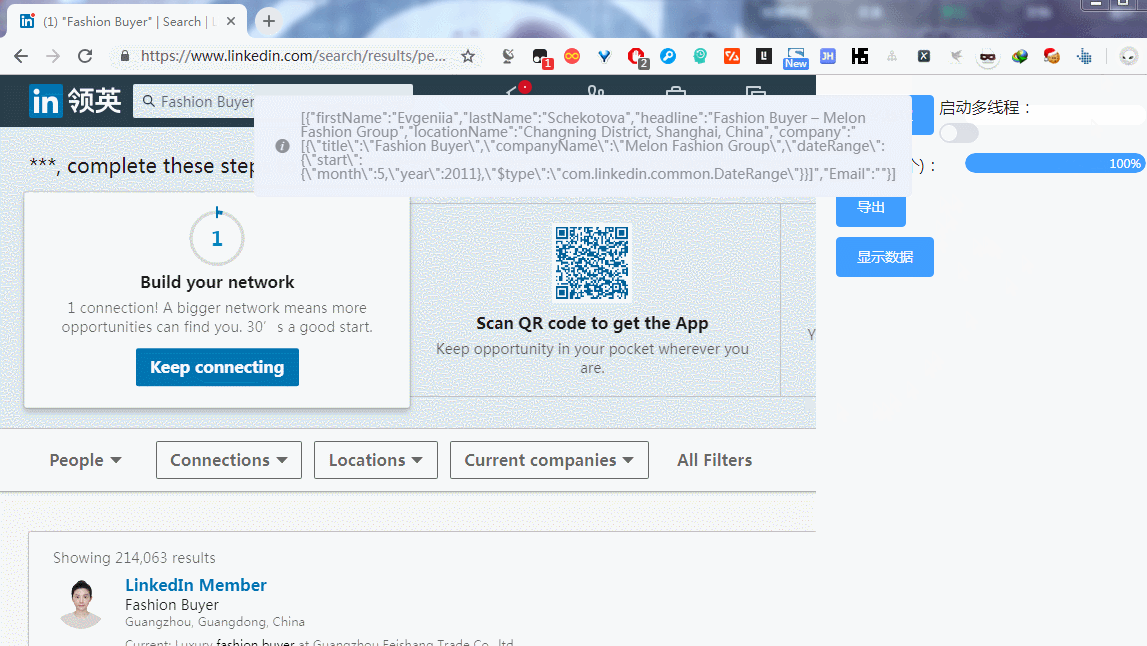
// 这里处理当前详情页上要抓取的数据
// 进行相应的赋值处理
detailObj.data1=‘xxx’;
detailObj.data2=‘xxx’;
// 最后移除事件,删除掉 iframe
this.removeEventListener("load", arguments.call, false);
doc.body.removeChild(thisframe);
},false);
document.body.appendChild(detail_frame );
重复循环。直至链接采集完成!
B、采用 开启新标签页的方式进行采集(比较复杂,需要写两个采集脚本:列表页、详情页)
列表页的脚本 用于获取链接开启详情标签页,并轮询详情页数据采集情况。
具体思路如下:
搜索列表界面利用插件的 GM_openInTab 方法打开详情页。详情页再写一个获取详情信息的采集脚本。
搜索列表页 定时轮询详情页的采集情况。
伪代码:
采用 localStorage 作为两个标签间 数据的桥梁。
搜索列表页:
1、GM_openInTab(“详情地址”),这里会返回一个 flag 对象,用于关闭打开的标签页
2、 setInterval 的方式轮询 localStorage 中的值是否存在。这里统一键名:detail
3、 获取到值,停止定时器,保存值到当前页面变量中,清空 localStorage 中 detail 变量的值。
4、利用 flag 关闭开启的标签页。并执行下个链接的采集。重复 步骤1。直至所有链接采集完为止。
搜索界面:
1、页面加载完后,将数据写入到 localStorage 变量中。这里统一键名:detail
效果如下:
PS:我这个账号是新的,搜索的会员都被隐藏了,只有一个会员显示。由于页面中的会员数据 是懒加载的,所以还要模拟下页面滚动。