HashMap实现的接口
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {...}
Map接口:Map的标准化接口,有(key-value)各种方法的实现,前面有介绍
Cloneable接口:可克隆接口,需要实现clone();
Serializable接口:可序列化
HashMap静态内部类
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } public final K getKey() { return key; } public final V getValue() { return value; } public final String toString() { return key + "=" + value; } public final int hashCode() { return Objects.hashCode(key) ^ Objects.hashCode(value); } public final V setValue(V newValue) { V oldValue = value; value = newValue; return oldValue; } public final boolean equals(Object o) { if (o == this) return true; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true; } return false; } }
Node节点:数组与链表的entry元素节点,key-value的基本操作,初始化,getKey(),getValue(),setValue(),toString(),hashcode(),equals().
红黑树节点元素
代码太多,截张图
留待研究:
HashMap常量与变量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //默认初始化容量大小:16 static final int MAXIMUM_CAPACITY = 1 << 30;//最大容量:2的30次方 static final float DEFAULT_LOAD_FACTOR = 0.75f;//默认加载因子大小:0.75 static final int TREEIFY_THRESHOLD = 8;//链表转红黑树阀值:超过8将链表转为红黑树存储 static final int UNTREEIFY_THRESHOLD = 6;//红黑树转链表阀值:小于6将红黑树转为链表存储 static final int MIN_TREEIFY_CAPACITY = 64;//转化为红黑树的最小容量,避免初期碰撞多导致resize()扩容时,重新转化为链表,导致效率低下 transient Node<K,V>[] table;//hashmap的第一层结构数组 transient Set<Map.Entry<K,V>> entrySet;//节点集合 transient int size;//hashmap大小 transient int modCount;//hashmap改变次数,iterator遍历时会锁定此值,改变后会报错 int threshold;//扩容阀值,超过此值resize()扩容, final float loadFactor;//实际加载因子
上网搜索扩展:为什么链表转红黑树阀值是8.
学过概率论的读者也许知道,理想状态下哈希表的每个箱子中,元素的数量遵守泊松分布:

当负载因子为 0.75 时,上述公式中 λ 约等于 0.5,因此箱子中元素个数和概率的关系如下:
| 数量 | 概率 |
|---|---|
| 0 | 0.60653066 |
| 1 | 0.30326533 |
| 2 | 0.07581633 |
| 3 | 0.01263606 |
| 4 | 0.00157952 |
| 5 | 0.00015795 |
| 6 | 0.00001316 |
| 7 | 0.00000094 |
| 8 | 0.00000006 |
这就是为什么箱子中链表长度超过 8 以后要变成红黑树,因为在正常情况下出现这种现象的几率小到忽略不计。一旦出现,几乎可以认为是哈希函数设计有问题导致的。
Java 对哈希表的设计一定程度上避免了不恰当的哈希函数导致的性能问题,每一个箱子中的链表可以与红黑树切换。
hashMap初始化
public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // 此行可以看出1.8之后,无参数构造方法,并未初始化容量,后面有介绍,第一次调用put方法时才会初始化容量 } public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } public HashMap(int initialCapacity, float loadFactor) {//有参数构造方法时,初始化容量,加载因子,扩容阀值 if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity);//扩容阀值取就近的2的幂值或者最大容量(例:15-->16 17-->32),以下是源码中tableSizeFor有意思的数学实现 } static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
HashMap方法实现
put方法()
自己画了个流程图,可能有许些不对,与后方源代码结合理解。
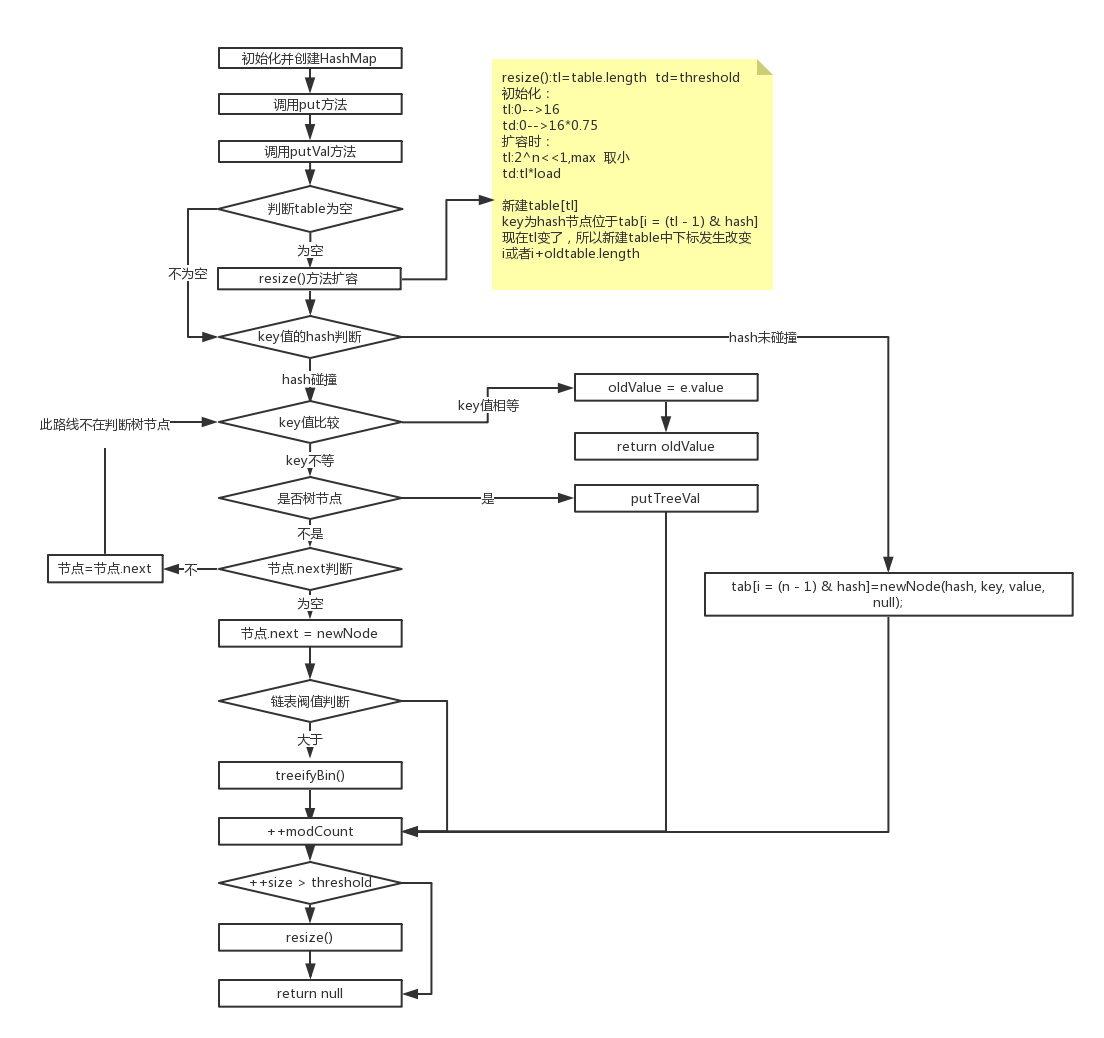
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0)//无参构造方法,resize()初始化容量的参数,具体见上图中的黄色说明 n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null)//hash不存在时,直接存储,元素在数组中的下标法则:(容量-1) & hash,扩容时下标同样符合此条件 tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))//hash相等,key值是否相等,相等覆盖 e = p; else if (p instanceof TreeNode)//hash相等,key不等,判断是否树节点元素 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//塞入红黑树 else {//hash相等,key不等,不是树节点,默认数组,链表节点元素 for (int binCount = 0; ; ++binCount) {//node.next()循环链表节点, if ((e = p.next) == null) {//链表中key不相等,最后一个节点指向新建节点 p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) //判断新链表与树阀值大小,链表转化为红黑树 treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))//判断链表中key是否相等,相等覆盖终止循环,不等循环下一个节点 break; p = e; } } if (e != null) { // 对应上述1 2覆盖 V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount;//每次调用put(),对象修改次数+1 if (++size > threshold)//put成功后比较阀值,是否需要扩容 resize(); afterNodeInsertion(evict);//空方法 return null; }
resize()
resize()方法有两个内容
1.扩容。超过阀值,扩展2倍,不过要注意容量最大值,及默认初始化的情况
2.调整节点在数组中下标位置。hash & (cap - 1) ;cap<<1所以 数组小标多一个高位,可能是1也可能是0.
为1时:newIndex = oldIndex + 1*oldCap;
为0时:newIndex = oldIndex + 0*oldCap;
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) {//正常到阀值扩容,*2 if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) newCap = oldThr; else { // 无参构造时,初始化默认参数 newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) {// (oldCap > 0 & oldThr == 0)||(oldCap == 0 & oldThr > 0) float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null)//单节点直接转换数组下标hash & (oldCap - 1)---->hash &(newCap - 1) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode)//树节点处理 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // 链表节点处理 Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; //扩容之后容量*2 :以16为例扩展成32,数组范围变化:newCap = 2*oldCap: //hash与数组下标关系 :**** = hash & 1111 ----> ***** = hash & 11111 //所以扩容之后节点下标变化 :****--->0****(原位置)或者1****(原位置+oldCap) if ((e.hash & oldCap) == 0) {//0**** if (loTail == null)//记录链表头节点 loHead = e; else //记录链表下个节点位置形成链表loHead-->e1-->e2-->... loTail.next = e; loTail = e; } else {//1**** if (hiTail == null)//记录链表头节点 hiHead = e; else hiTail.next = e;//记录链表下一个节点位置形成链表hiHead-->e1-->e2-->... hiTail = e; } } while ((e = next) != null); if (loTail != null) {//尾节点.next = null loTail.next = null; newTab[j] = loHead;//0**** 数组原位置j不变 } if (hiTail != null) {//尾节点.next = null hiTail.next = null; newTab[j + oldCap] = hiHead;//1**** 数组位置改变 j+oldCap } } } } } return newTab; }
oldCap