Abstract
现存问题:现有的基于cnn的单幅图像超分辨率(SISR)方法大多假设低分辨率(LR)图像是从高分辨率(HR)图像中双三次下采样的。当真正的退化不遵循这一假设时,不可避免地会导致性能降低。此外,这种只针对单一退化方式的模型很难处理多种退化的问题。
解决方法:提出了一个具有维数拉伸策略的通用框架,使单个卷积超分辨率网络能够获得SISR退化过程中的两个关键因素:模糊内核和噪声等级,并将这两个因素作为输入。因此,该框架能够处理多个甚至空间变异退化,大大提高了其实用性。
在典型的SISR框架中,LR图像y通常以以下方式产生:
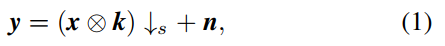
其中x⊗k表示HR图像x与模糊核k进行卷积,↓s 表示随后进行的以s为比例系数的下采样操作。n通常是标准差(噪声等级)为σ的高斯白噪声(AWGN)。
SISR方法大致可分为三类:
-
基于插值的方法:如最近邻法、双线性插值法和双三次插值法,简单有效,但性能有限。
-
基于模型的优化方法:通过利用强大的图像先验(如非局部自相似先验、稀疏先验和去噪先验),基于模型的优化方法可以灵活地重构相对高质量的HR图像,但通常涉及到耗时的优化过程。基于模型优化方法的典型缺点就是非端到端的学习方式,涉及手工设计参数。
-
判别学习方法:性能较好,在本篇论文中我们主要研究了用于SISR的判别CNN方法。
本篇论文的主要贡献
-
我们为SISR提出了一个简单有效且可扩展的深度CNN框架。该模型不局限于双三次退化假设,可以适用于多种甚至空间变异退化。
-
我们提出了一种新的维度拉伸策略来解决LR输入图像、模糊核和噪声之间的维度不匹配问题。虽然该策略是为SISR提出的,但它是通用的,可以扩展到其他任务,如去模糊。
-
我们证明了从合成训练数据中学习的卷积超分辨率网络不仅可以在合成LR图像上产生与目前最先进的SISR方法相竞争的结果,而且可以在真实LR图像上产生视觉上可信的结果。
Method
退化模型
在解决SISR问题之前,我们需要知道退化模型并不只有上文的公式(1)。另一个实用的退化模型为
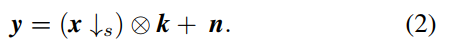
其中↓为双三次下采样器。公式(2)对应的是去模糊问题,其次是一个双三次退化的SISR问题。因此,它可以受益于现有的去模糊方法和基于双三次退化的SISR方法。但由于空间有限,我们只考虑更广泛的退化模型,即公式(1)。然而我们的方法是通用的,可以很容易地扩展到处理公式(2)。
下面详细讨论模糊核k、噪声n和下采样器↓
模糊核:与图像去模糊不同,SISR的模糊核设置通常比较简单。最常见的选择是用标准差或核宽度参数化的各向同性高斯模糊核。在实践中,更复杂的模糊内核模型用于去模糊任务,如运动模糊。经验和理论分析表明,精确模糊核的影响远远大于复杂图像先验的影响。具体来说,当假定的模糊核比真实的模糊核更平滑时,恢复的图像会过度平滑。大多数SISR方法都会出现这种情况。另一方面,当假定的内核比真正的内核尖锐时,会出现高频振铃现象。
振铃效应:图像复原中损失高频信息的话会产生振铃效应。图像处理中,对一幅图像进行滤波处理,若选用的频域滤波器具有陡峭的变化,则会使滤波图像产生“振铃”,所谓“振铃”,就是指输出图像的灰度剧烈变化处产生的震荡,就好像钟被敲击后产生的空气震荡。
噪声:由于低分辨率,LR图像通常带有噪声。直接对带有噪声的输入进行超分辨率会放大不需要的噪声,会使视觉效果变差。为了解决这个问题,最直接的方法是先去噪,然后提高分辨率。然而,去噪预处理步骤往往会丢失细节信息,从而影响后续的超分辨率性能。因此,联合进行去噪和超分辨率是非常必要的。
下采样器:现有文献考虑了两种下采样器,包括直接下采样器和双三次下采样器。在本文中,我们考虑了双三次下降采样器,因为当k为模糊核且噪声水平为0时,公式(1)转化为广泛使用的双三次退化模型。需要指出的是,与一般退化模型中变化的模糊核和噪声不同,下采样器是固定的。
从最大后验(maximum a posteriori)框架的角度
虽然现有的基于cnn的SISR方法不一定是在传统最大后验框架下派生出来的,但它们有着相同的目标。我们重新审视和分析了SISR的总体最大后验框架,旨在找出最大后验原理与CNN工作机制之间的内在联系。从而对CNN结构设计有更多的了解。
由于SISR的多解性质,需要使用正则化来约束解决方案。从数学上讲,通过解决下面的最大后验问题,可以估算出LR图像y的HR对应值
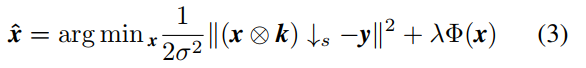
其中![]() 是数据保真项,
是数据保真项,![]() 是正则项(或先验项),λ是权衡参数。
是正则项(或先验项),λ是权衡参数。
公式(3)主要说明两点:
-
估计方案不仅要符合退化过程,还要具有清晰HR图像所具有的性质。
-
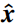 是一个关于LR图像y,模糊核k,噪声等级σ ,权衡参数λ的方程。
是一个关于LR图像y,模糊核k,噪声等级σ ,权衡参数λ的方程。
因此,SISR的最大后验方案(非盲目的)可以表述为
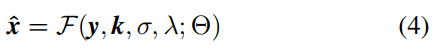
其中Θ 表示最大后验推测的参数
将CNN作为方程4的判别学习解,我们可以得到以下几点启示:
-
由于数据保真项对应退化过程,因此退化过程的准确建模对SISR的成功起着关键作用。然而,现有的基于cnn的双三次退化SISR方法实际上是为了解决以下问题
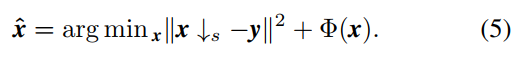
可以看出公式(5)的实用性比较局限
-
为了设计更实用的SISR模型,最好是学习像公式(4)这样的映射函数,因为它覆盖了更广泛的退化。需要注意的是,由于权衡参数λ可以归进于σ中,公式(4)可以重新表述为
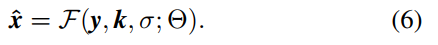
-
考虑到最大后验框架(公式(3))可以在相同的先验图像下实现一般图像的超分辨率,在统一的CNN框架下联合进行去噪和SISR是很直观的。此外,最大后验推理的参数主要对先验进行建模;因此,CNN有能力通过一个模型处理多个退化。
从最大后验框架的角度,可以看到SISR的目的是学会一个映射函数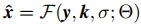 而不是
而不是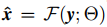 。然而通过cnn对
。然而通过cnn对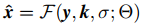 直接建模并不容易。原因在于三个输入y, k和σ有不同的维度,我们将提出一个简单的维度拉伸策略来解决这个问题。
直接建模并不容易。原因在于三个输入y, k和σ有不同的维度,我们将提出一个简单的维度拉伸策略来解决这个问题。
维度拉伸
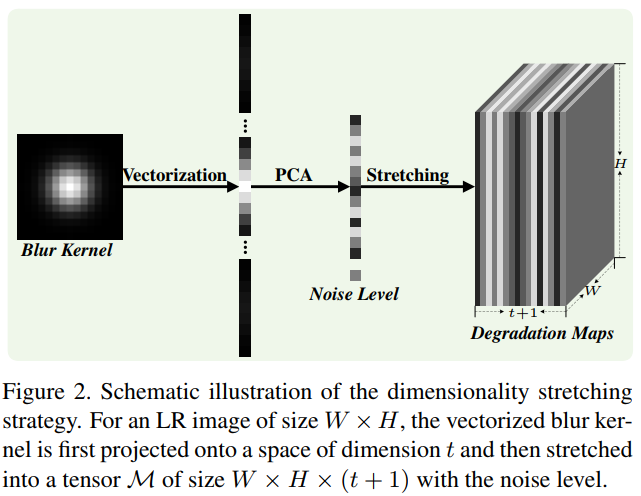
假设输入包含一个p×p尺寸的模糊核,等级为σ的噪声,以及大小为WxHxC(C为通道数)的LR图像。首先将模糊核向量化为p^2×1的向量,然后通过主成分分析(PCA)技术投影到t维线性空间中,再连接低维向量和噪声水平(用v表示),最后拉伸到大小为W×H×(t + 1)的退化映射M, 其中第i个映射的所有元素就是vi。通过这些处理,退化映射就可以与LR图片连接了,这就使CNN处理三个输入成为可能。考虑到退化映射可能是不均匀的,这种简单的策略可以很容易地用于处理空间变异退化。
提出的网络
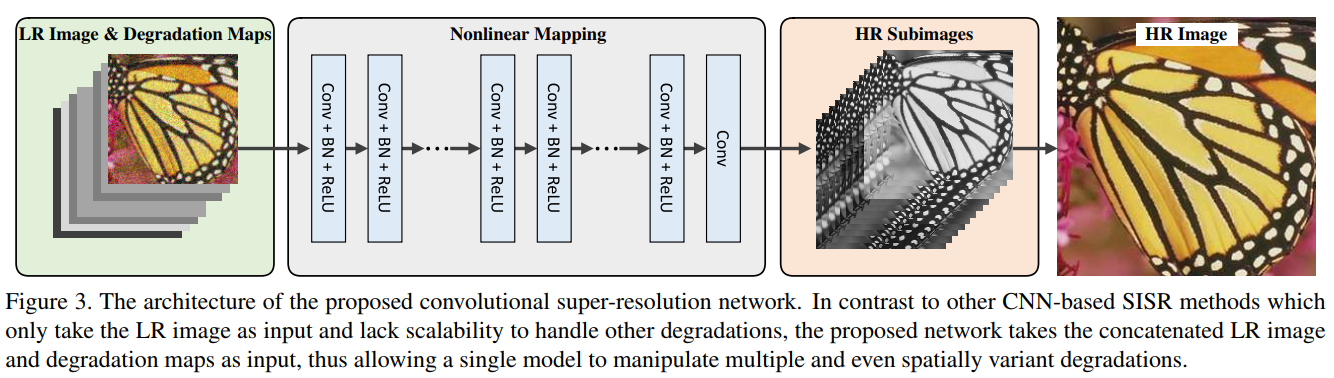
我们提出了多重退化超分辨率网络SRMD。SRMD的独特之处在于它将LR图像和退化映射连接起来作为输入。为了证明维度拉伸策略的有效性,我们使用了没有复杂结构的简单CNN。
网络如下:
-
对于一张比例系数为s的LR图像,SRMD首先将LR图像和尺寸为W×H×(C + t + 1)的退化映射拼接后作为输入。
-
然后使用3×3级联的卷积层进行非线性映射。每一层由Conv,BN,ReLU三种操作组成。具体来说,除了最后一个卷积层只包含一个“Conv”操作外,其余每个卷积层都采用“Conv + BN + ReLU”。
-
在最后一个卷积层后添加子像素卷积层,其作用是将大小为W×H×s^2C的多个HR子图像转换为大小为sW×sH×C的单张HR图像
对于比例系数2、3、4,我们都设置卷积层数为12,每层的feature map数为128。我们分别学习每个比例系数的模型。我们还通过去除第一个卷积核中噪声等级映射的连接和使用新的训练数据进行微调的方式学习了无噪声退化模型(即SRMDNF)。
另需指出的两点:
-
因为CNN训练中有ReLU,BN,Adam这些先进方法,可以很容易的训练网络。因此没有使用残差学习策略。
-
因为退化涉及到噪声,双三次插值的LR图像会加剧噪声的复杂性,从而增加训练难度。因此没有使用双三次插值的LR图像。
盲模型
为了增强CNN对SISR的实用性,最直接的方法似乎是学习一个综合了不同退化的训练数据的盲模型。然而这样的盲模型并没有达到预期的效果。
-
当模糊核模型比较复杂时(如运动模糊),性能会严重下降。例如:给定一个HR图像,一个模糊核和对应的LR图像,将HR图像向左移动一个像素,将模糊核向右移动一个像素,将得到相同的LR图像。因此,一个LR图像可能对应于具有像素位移的不同HR图像。这反过来又会加重像素平均问题,通常会导致过度平滑的结果(个人解释:在不知道模糊核信息的情况下,一个LR图像可以对应多个像素平移的HR图像。而盲模型只从LR图像中学习,不学习模糊核,噪声这些参数,这就导致盲模型只能通过像素平均的方式来解决这个问题,因此性能会严重下降)
-
没有专门设计体系结构的盲模型泛化能力较差,在实际应用中表现较差。
相比之下,多重退化的非盲模型几乎没有像素平均问题,具有更好的泛化能力。
-
退化映射包含了warping information ,因此可以使网络具有空间转换能力。可以将模糊核和噪声等级导致的退化映射作为空间转换器的输出。
-
通过使用退化映射对模型进行锚定,非盲模型可以很容易地泛化到不可见的退化,并且能够控制数据保真项和正则化项之间的权衡。
Experiments
训练数据生成和网络训练
具体的细节设置看原文吧。这里只放一下损失函数
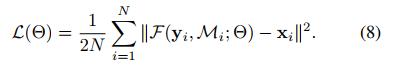
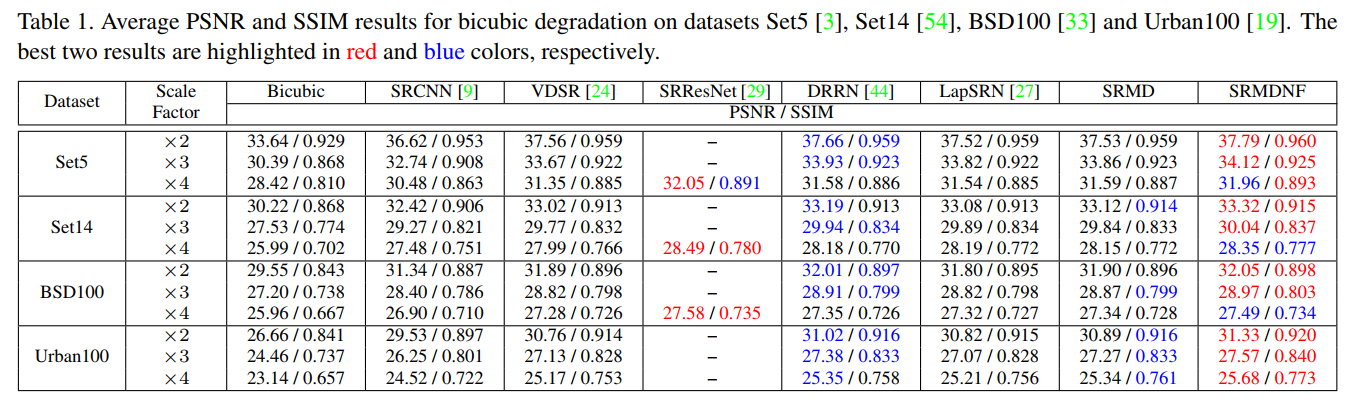
双三次退化上的实验
虽然我们的目标不是仅仅处理双三次退化,而是学习单个网络来处理多个退化。然而,为了显示维度拉伸策略的优点,我们也将所提出的方法与其他专门针对双三次退化的基于cnn的方法进行了比较。

总结:
-
从图中可以看出在双三次退化、不考虑噪声的情况下SRMDNF总体成绩最好。
-
能取得最好成绩的原因可能是因为在最大后验框架中,多种退化的SRMDNF共享了最大后验框架中相同的先验,从而促进了隐式先验学习,有利于PSNR的改进。这也可以解释为什么具有多个尺度的VDSR可以提高性能。
-
SRMD因为综合考虑了多种退化和噪声的情况,在图中的实验设置中性能稍比SRMDNF差。
一般退化上的实验
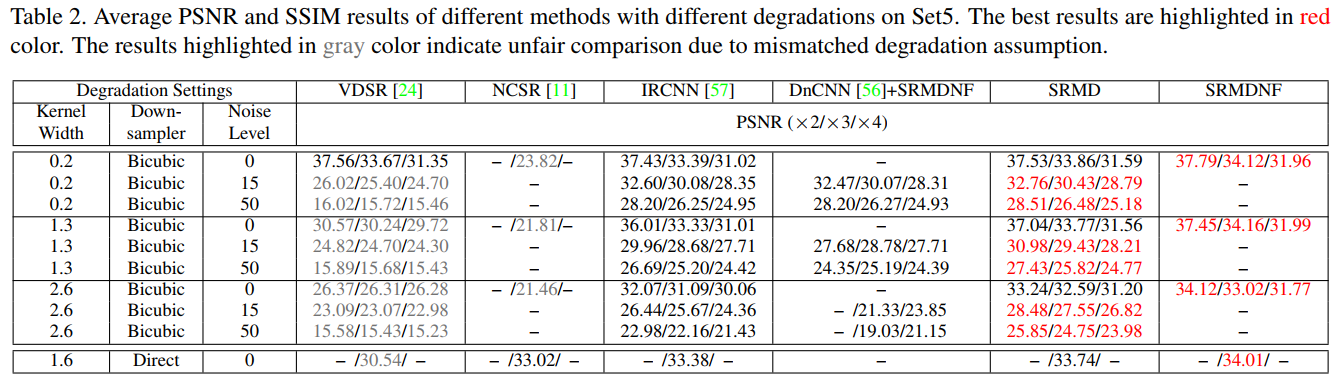

总结:
-
当假定的双三次退化与真实的双三次退化相背离时,VDSR的性能严重恶化。
-
SRMD比NCSR和IRCNN产生更好的结果,并且优于DnCNN+SRMDNF。其中,SRMD相对DnCNN+SRMDNF的PSNR增益随着核宽度的增大而增大,验证了联合去噪和超分辨率的优点。
-
通过设置适当的模糊核,该方法在处理直接下采样器的退化时具有良好的性能。
-
从图6可以看出,NCSR和IRCNN产生的视觉效果比VDSR更好,因为它们假定的性能下降与实际情况相符。然而,它们无法恢复SRMD和SRMDNF那样锐利的边缘。
空间变异退化的实验
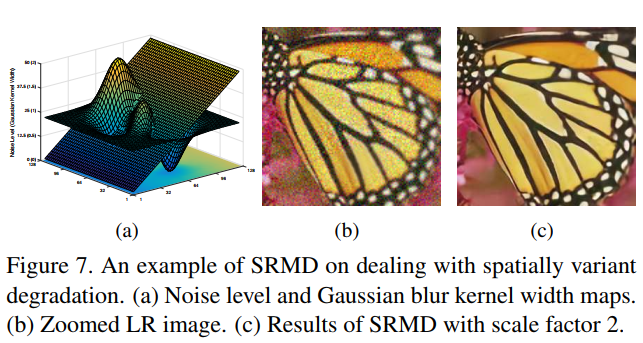
为了证明SRMD对空间变异退化的有效性,我们合成了一个空间变异模糊核和噪声水平的LR图像。图7显示了空间变异退化的SRMD的可视化结果。可以看出,所提出的SRMD对于恢复潜在的HR图像是有效的。注意,模糊核假设是各向同性高斯分布。
真实图像上的实验
由于没有ground-truth HR图像,我们只提供可视化比较。


总结:
-
从可视化结果可以看出,SRMD比其他方法生成的HR图像更具有视觉上的合理。
-
从图8可以看出,VDSR的性能受到压缩效应的严重影响。Waifu2x虽然可以成功地去除压缩效应,但无法恢复锐利的边缘。相比之下,SRMD不仅可以去除不满意的压缩效应,还可以产生尖锐的边缘。
-
从图9可以看出,VDSR和SelfEx都倾向于产生过于平滑的结果,而SRMD可以恢复有着更好亮度和gradient statistics of clean images的清晰图像。
Conclusion
-
在本文中,我们提出了一种有效的超分辨率网络,该网络具有较高的可扩展性,可以通过单一模型处理多种退化。
-
与现有的基于cnn的SISR方法不同,本文提出的模型以LR图像及其退化映射作为输入。具体来说,退化映射是通过对退化参数(即模糊内核和噪声等级)进行简单的维度拉伸得到的。
-
在合成LR图像上的结果表明,所提出的模型不仅能在双三次退化方面产生最先进的结果,而且在其他退化甚至空间变异退化方面也有良好的表现。
-
对真实LR图像的重构结果表明,该方法能较好地重构出视觉上可信的HR图像。
参考资料