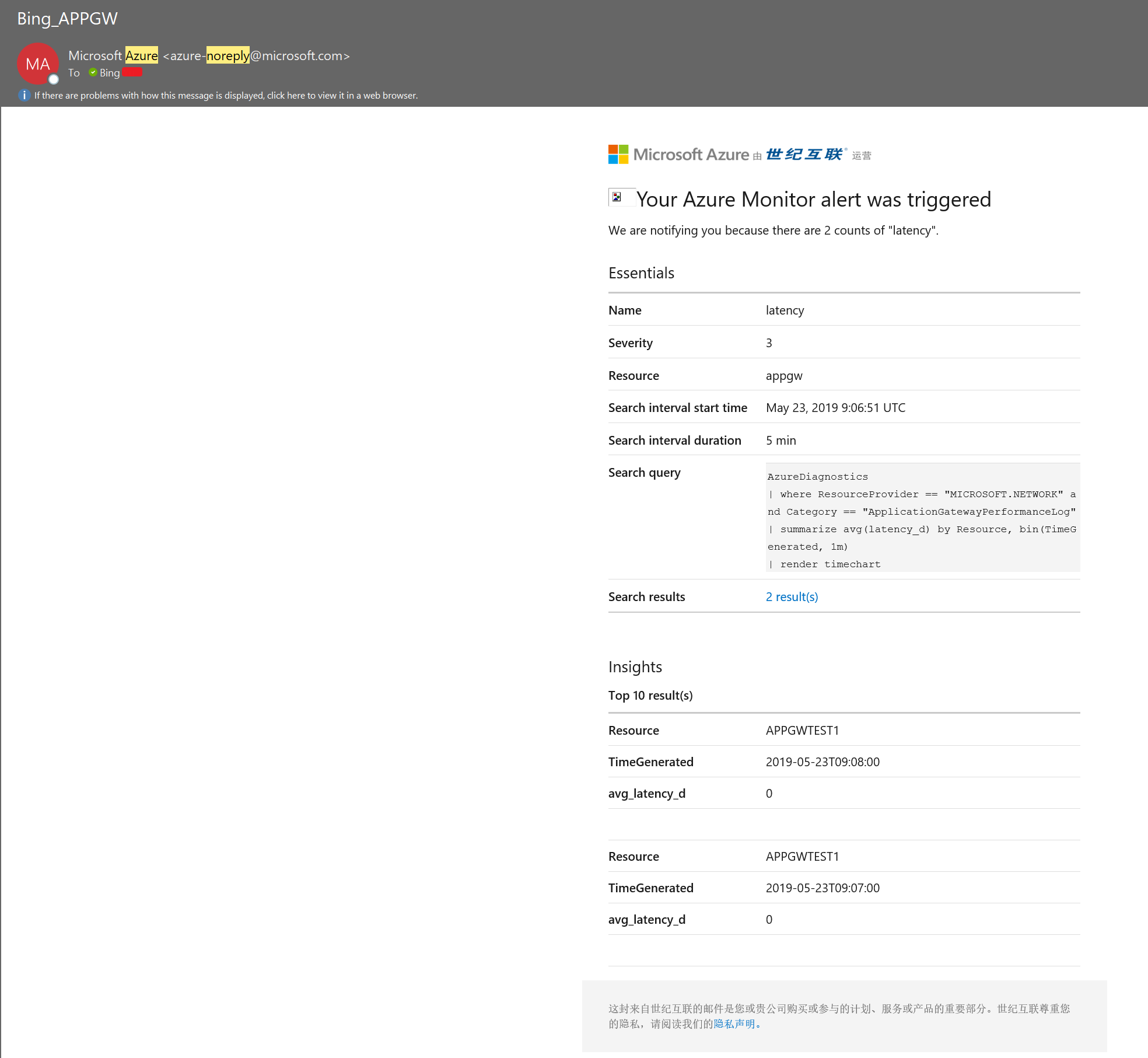
如何简单实现对AppGW日志的自动监控和告警
我们经常遇到这样的场景:Azure应用程序网关的“指标”功能不支持设置报警,平常想常规监控AppGW的运行情况,要么只能登陆到Portal查看,要么只能配置获取Access Log, Performance Log, WAF log三种日志 —— 人工分析这些日志太费时费力,用户体验也不够友好。
本文旨在结合使用Monitor,Log Analytics workspace(下文简称LA)服务,通过简单的步骤实现对AppGW诊断日志的自动分析、监控和告警。
一、 AppGW的诊断有什么?
如官方文档(https://docs.azure.cn/zh-cn/application-gateway/application-gateway-diagnostics#metrics)所述,您可以通过三种方式监视资源:后端运行状况、日志、指标。
如果您已经对以上三种的适用场景和查询方法非常熟悉,可以直接看文章第二部分“如何配置诊断日志自动分析及监控告警”。
- 后端运行状况:应用程序网关提供通过 Azure 门户和 PowerShell 监视后端池中的服务器运行状况的功能。 也可通过性能诊断日志找到后端池的运行状况。
- 日志:通过日志记录,可出于监视目的从资源保存或使用性能、访问及其他数据。
本文第二部分会介绍如何使用LA分析日志并设置告警。
- 指标:应用程序网关当前有七个指标可用来查看性能计数器。
应用程序网关的指标您需要在监视器(Monitor)服务界面的Metrics中看到,如下图。
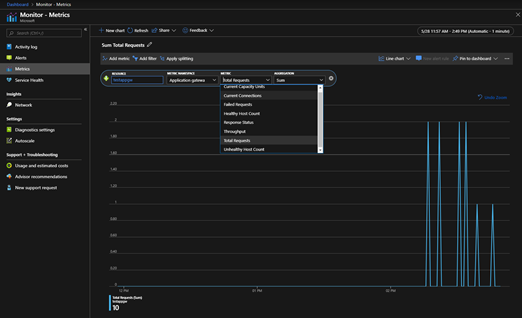
如官方文档(https://docs.azure.cn/zh-cn/azure-monitor/platform/metrics-supported#microsoftnetworkapplicationgateways)所示,目前Mooncake支持7种指标:吞吐量、UnhealthyHostCount、HealthyHostCount、TotalRequests、FailedRequests、ResponseStatus、CurrentConnections。在Metrics界面您可能还可以看到 “Current Capacity Units” ,这个属于在Mooncake还未正式落地的功能,仅供参考。
截取官网上对于Mooncake应用程序网关支持的指标描述:

二、 如何配置诊断日志自动分析及监控告警
以下测试环境为AppGW + VM (Nginx) 的架构。示例希望分析AppGW每个访问的耗时,对AppGW的日志做分析并在它大于100秒时告警发送邮件给固定邮箱。
- 1. 确认后端服务正常运行,可以通过AppGW访问

- 2. 在Azure Portal上,为AppGW诊断开启LA
点击应用程序网关界面Diagnostic settings上的 “Add Diagnostic setting” 或 “Edit setting”
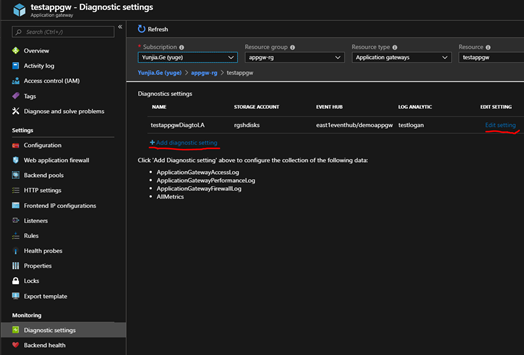
勾选“Send to Log Analytics” (需要您创建了至少一个LA Workspace)
目前LA Workspace只能创建在China East 2,但任何region的AppGW都可以选择位于China East 2的LA Workspace来分析日志。
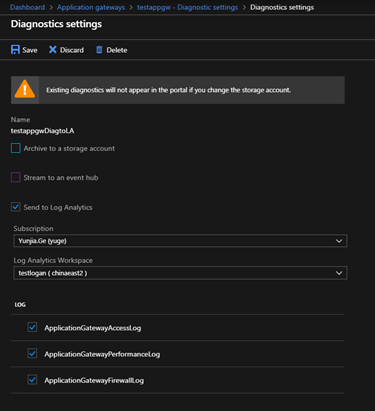
如果您没有创建过LA workspace,可以在“All Service”中找到 “Log Analytics workspaces”服务,创建一个workspace。
如果您从未接触过LA workspace,您可以参考这里做简单了解:https://docs.azure.cn/zh-cn/azure-monitor/log-query/get-started-portal。
- 3. 在LA workspace中分析日志结果
在AppGW侧勾选配置后,日志会自动发布到LA workspace中,用户不需要在LA侧做更多配置。
请注意:如果您的AppGW配置了NSG,可能导致日志无法同步到LA。更多解释及办法您可以参考这里:https://docs.microsoft.com/en-us/azure/azure-monitor/platform/log-analytics-agent#network-firewall-requirements。
接下来我们就可以自定义Query来分析AppGW的诊断日志了。
请注意:第一次配置AppGW诊断发送到LA,LA可能需要花较长的时间(在我们的测试中花了几个小时),我们推测LA需要这些时间在后台构建对应数据库的表等等,建议预留大约一天的时间开启。之后,正常情况下日志延迟大约在2-4分钟以内。
这里我查询了针对每个URI的time_taken,Query如下:
Avg timeTaken per minute by API
AzureDiagnostics
| where ResourceProvider == "MICROSOFT.NETWORK" and Category == "ApplicationGatewayAccessLog"
| where TimeGenerated >= ago(2h)
| summarize avg(timeTaken_d) by Resource,requestUri_s, bin(TimeGenerated, 1m)
| project avg_timeTaken_d, requestUri_s, TimeGenerated
查询结果如下图:
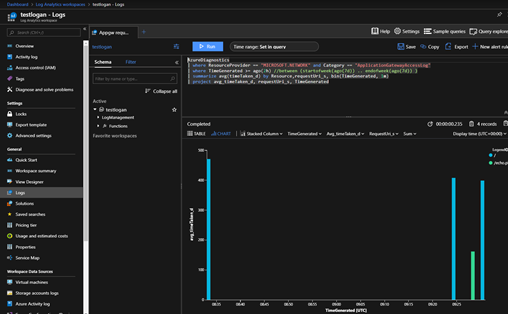
Query语句属于Azure Monitor的功能,它使用了Kusto查询语言的一个版本以各种方式检索和分析日志数据。
您可以参考这里:https://docs.azure.cn/zh-cn/azure-monitor/log-query/log-query-overview 了解更多查询语句说明和示例。
Global文档(仅供参考):https://docs.microsoft.com/en-us/azure/azure-monitor/log-query/log-query-overview
这里列举了一些AppGW相关的常用查询,您可以根据实际需要编写更多复杂的语句:
Avg throughput per second (Mb)
AzureDiagnostics
| where ResourceProvider == "MICROSOFT.NETWORK" and Category == "ApplicationGatewayPerformanceLog"
| summarize avg(throughput_d) by Resource, bin(TimeGenerated, 1m)
| extend ThroughputMb = (avg_throughput_d/1000)/1000
| project Resource, TimeGenerated, ThroughputMb
| render timechart
Avg Requests per min
AzureDiagnostics
| where ResourceProvider == "MICROSOFT.NETWORK" and Category == "ApplicationGatewayPerformanceLog"
| summarize avg(requestCount_d) by Resource, bin(TimeGenerated, 1m)
| render timechart
Unhealthy backend VM count
AzureDiagnostics
| where ResourceProvider == "MICROSOFT.NETWORK" and Category == "ApplicationGatewayPerformanceLog"
| summarize max(unHealthyHostCount_d) by Resource, bin(TimeGenerated, 1m)
| render timechart
Avg Latency (ms) by AppGW
AzureDiagnostics
| where ResourceProvider == "MICROSOFT.NETWORK" and Category == "ApplicationGatewayPerformanceLog"
| summarize avg(latency_d) by Resource, bin(TimeGenerated, 1m)
| render timechart
Error count past hour by AppGW
AzureDiagnostics
| where ResourceProvider == "MICROSOFT.NETWORK" and Category == "ApplicationGatewayAccessLog"
| where httpStatus_d >= 400
| summarize count() by httpStatus_d, Resource
| project httpStatus_d, Resource, count_
HTTP Error count per hour by API
AzureDiagnostics
| where ResourceProvider == "MICROSOFT.NETWORK" and Category == "ApplicationGatewayAccessLog"
| where httpStatus_d >= 400
| summarize count(httpStatus_d) by httpStatus_d,requestUri_s, bin(TimeGenerated, 1h)
| order by count_httpStatus_d desc
| project httpStatus_d, requestUri_s, TimeGenerated, count_httpStatus_d
Failed requests by backend VM
AzureDiagnostics
| where ResourceProvider == "MICROSOFT.NETWORK" and Category == "ApplicationGatewayAccessLog"
| where httpStatus_d >= 400
| parse requestQuery_s with * "SERVER-ROUTED=" serverRouted "&" *
| extend httpStatus = tostring(httpStatus_d)
| summarize count() by serverRouted, bin(TimeGenerated, 5m)
| render timechart
- 4. 对分析结果设置自动告警
到这里,我们可以在Portal上图形化地看到AppGW日志的分析结果。
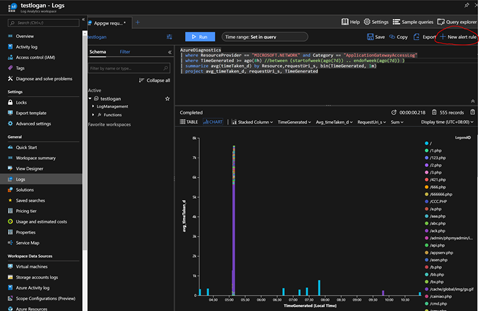
为了自动化监控AppGW,接下来我们使用Azure Monitor对这个分析结果设置告警。您可以在Logs的右上角(下图红圈部分),找到“New Alert Rule”
在新的界面配置告警规则,共包含三部分:

(1) Condition
触发告警的条件,点击感叹号部分,弹出配置框。如何配置的官方说明您可以参考这里:https://docs.azure.cn/zh-cn/azure-monitor/platform/alerts-unified-log。
- 日志查询 Search Query
这是每次触发预警规则时都会运行的查询。 此查询返回的记录用于确定是否将触发某个警报。有关更详细的视图,请参阅 Azure Monitor 中的日志警报查询(https://docs.azure.cn/zh-cn/azure-monitor/platform/alerts-log-query)。
默认这里会使用3中配置的查询语句,您也可以适当地修改。
- Alert Logic
针对 Azure Monitor 的日志查询规则可以分为两种类型。
“结果数”警报规则始终创建单个警报,而“指标度量”预警规则将为超出阈值的每个对象创建一个警报;
“结果数”预警规则会在超出阈值一次时创建一个警报。 当阈值在特定的时间间隔内超出特定的次数时,“指标度量”警报规则即可创建一个警报。
- Evaluated based on
频率:指定应运行查询的频率。 可以是介于 5 分钟到 24 小时之间的任何值。 应等于或小于时间段。 如果该值大于时间段,则会有记录缺失的风险。
阈值:对日志搜索的结果进行评估,确定是否应创建警报。 不同类型的日志搜索警报规则的阈值不同。
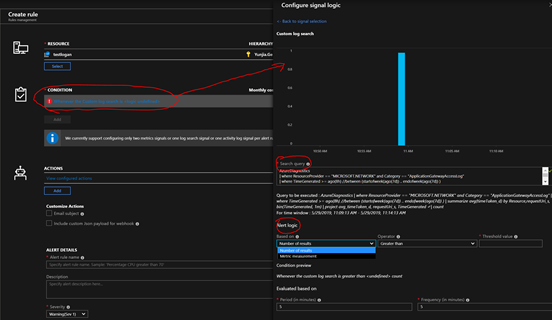
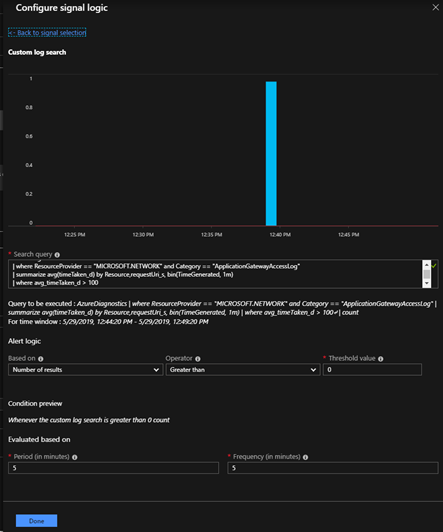
一个成功创建的Condition如下图所示:这里选择了“结果数”作为日志查询规则,查询返回timeTaken大于一定阈值(100)的请求数。
AzureDiagnostics
| where ResourceProvider == "MICROSOFT.NETWORK" and Category == "ApplicationGatewayAccessLog"
| summarize avg(timeTaken_d) by Resource,requestUri_s, bin(TimeGenerated, 1m)
| where avg_timeTaken_d > 100
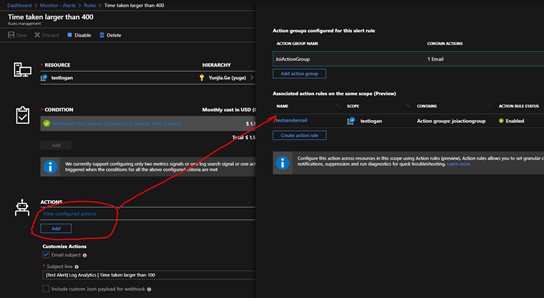
(2) Actions
Azure Monitor 和服务运行状况警报使用操作组来通知用户某个警报已触发。 各种警报可以使用相同的操作组或不同的操作组,具体取决于用户的要求。
您可以选择添加现有的操作组或/和操作规则(操作规则目前还是Preview状态,这个功能还未正式落地),并配置特定于操作的信息(比如发邮件/短信,或调用Runbook + Webhook 实现更多自定义功能)。
如果您还没有创建过操作组,可以参考这里:https://docs.microsoft.com/en-us/azure/azure-monitor/platform/action-groups。
当操作配置为通过电子邮件或短信来通知某个人员时,该人员的邮箱或手机将收到确认,指出他 / 她已被添加到操作组。
在下图红圈下方,您可以指定邮件的标题,以及是否包含Webhook的相关Json。
(3) Alert Details
指定Alert的名称、描述和严重性(警报规则中指定的条件符合后确定的警报严重性。 严重性的范围为 0 到 4)。
创建之后您可以在“Monitor-Alerts”界面查看历史警报,如下图。
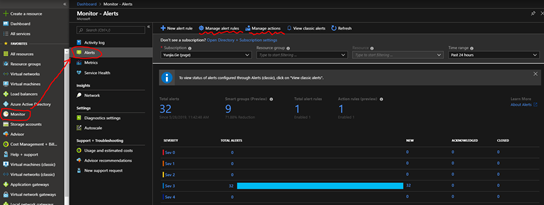
您也可以在这个界面管理前面两步创建的警报规则(Manage Alert Rules)和操作组/操作(Manage actions)。
至此我们已经配置完毕日志分析(Log analytics Workspace)和自动监控告警(Monitor)。示例中配置了对AppGW的访问耗时的日志分析,当大于100秒时告警发送邮件。这里具体阈值建议根据实际业务配置,以避免收到大量误报警对被通知的人造成影响。