深入理解TCP协议及其源代码
TCP close分析
close背后的连接终止过程
TCP协议作为一个可靠的、基于连接的流协议,要通过IP层的不可靠传输来,给上层协议提供"可靠"的数据流。
- 可靠:TCP要保证用户数据完整以及数据的顺序。
- 基于连接:启动前要建立连接,结束后要断开连接。
- 流协议:TCP的数据是以字节为单位的,而没有进行分包。
其中TCP协议的使用有建立连接和断开连接是TCP与UDP的区别之一,本文主要对TCP的close进行源码分析和运行跟踪。
首先TCP断开连接的过程是4次挥手:
- 主机1发送完自己要发送的所有数据,决定断开连接
- 主机1使用
close发送fin|ack(附带对主机2前面数据的ack),断开连接的过程开始,此时主机1的发送窗口关闭,接受窗口还在工作; - 主机2接受到主机1的
fin后,发送ack告知主机1对方的fin已收到; - 主机2继续发送数据,直到主机2发送完所有数据
- 主机2使用
close发送fin,表示自己的数据也发送完毕 - 主机1接受
fin,发送ack,告知主机2对方的fin已收到
也就是主机1和主机2连接断开的过程中,某一主机已经表示断开连接了时另一主机还可能继续发数据,当然也存在两者同时发送完毕,那就成了第3次挥手主机2的fin和第2次对主机1ack一起发送。
因为TCP是可靠的协议,所以需要Ack来保证发送的fin已到达对方,且存在两者不同时发送完数据的情况,所以通常情况下需要4次挥手。
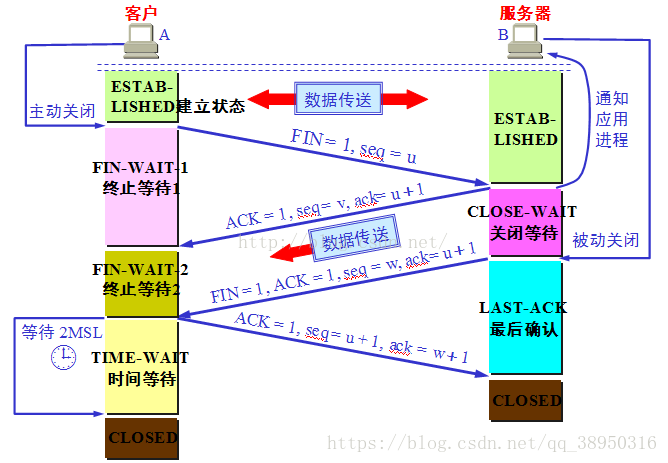
所以TCP的close分为先后两个情况,同时关闭的情况不做描述。
TCP close源码
- [ ] Linux TCP close过程源代码阅读
C语言中使用close来关闭对应的TCPSocket套接字,比如
int socket_fp = socket(AF_INET, SOCK_STREAM, 0);
close(socket_fp);close函数通过系统调用sys_close来执行,代码位于fs/open.c中
/* fs/open.c:1191 */
SYSCALL_DEFINE1(close, unsigned int, fd)
{
int retval = __close_fd(current->files, fd);
//...
return retval;
}系统调用又sys_close又通过fs/file.c中的__close_fd函数来释放文件指针,最终调用flip_close方法
/* fs/file.c */
int __close_fd(struct files_struct *files, unsigned fd)
{
struct file *file;
struct fdtable *fdt;
// 获得访问锁
spin_lock(&files->file_lock);
fdt = files_fdtable(files);
if (fd >= fdt->max_fds)
goto out_unlock;
file = fdt->fd[fd];
if (!file)
goto out_unlock;
rcu_assign_pointer(fdt->fd[fd], NULL);
// 释放文件描述符
__put_unused_fd(files, fd);
// 释放访问锁
spin_unlock(&files->file_lock);
// 调用flip_close方法
return filp_close(file, files);
out_unlock:
spin_unlock(&files->file_lock);
return -EBADF;
}flip_close位于fs/open.c中。
/* fs/open.c */
int filp_close(struct file *filp, fl_owner_t id)
{
int retval = 0;
// 检测文件描述符引用数目
if (!file_count(filp)) {
printk(KERN_ERR "VFS: Close: file count is 0\n");
return 0;
}
// 调用flush方法
if (filp->f_op->flush)
retval = filp->f_op->flush(filp, id);
if (likely(!(filp->f_mode & FMODE_PATH))) {
dnotify_flush(filp, id);
locks_remove_posix(filp, id);
}
// 调用fput方法
fput(filp);
return retval;
}位于fs/file_table.c中的fput调用fput_many,接着启动task____fput调用__fput,最终跟踪到指针函数f_op->release
/* fs/file_table.c */
static void __fput(struct file *file)
{
// ...
// 调用指针函数file->f_op->release
if (file->f_op->release)
file->f_op->release(inode, file);
// ...
}
void fput_many(struct file *file, unsigned int refs)
{
if (atomic_long_sub_and_test(refs, &file->f_count)) {
struct task_struct *task = current;
if (likely(!in_interrupt() && !(task->flags & PF_KTHREAD))) {
// 这里启动了____fput
init_task_work(&file->f_u.fu_rcuhead, ____fput);
if (!task_work_add(task, &file->f_u.fu_rcuhead, true))
return;
}
if (llist_add(&file->f_u.fu_llist, &delayed_fput_list))
schedule_delayed_work(&delayed_fput_work, 1);
}
}
void fput(struct file *file)
{
// 调用fput_many
fput_many(file, 1);
}fp_ops->release
fp_ops->release这个指针函数在套接字初始化的时候被赋值,可以定位到函数sock_close
/* net/socket.c */
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.read_iter = sock_read_iter,
.write_iter = sock_write_iter,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = compat_sock_ioctl,
#endif
.mmap = sock_mmap,
.release = sock_close,
.fasync = sock_fasync,
.sendpage = sock_sendpage,
.splice_write = generic_splice_sendpage,
.splice_read = sock_splice_read,
};通过socket_close调用__sock_release中的sock->ops->release函数
/* net/socket.c */
static void __sock_release(struct socket *sock, struct inode *inode)
{
if (sock->ops) {
struct module *owner = sock->ops->owner;
if (inode)
inode_lock(inode);
sock->ops->release(sock);
sock->sk = NULL;
if (inode)
inode_unlock(inode);
sock->ops = NULL;
module_put(owner);
}
if (sock->wq.fasync_list)
pr_err("%s: fasync list not empty!\n", __func__);
if (!sock->file) {
iput(SOCK_INODE(sock));
return;
}
sock->file = NULL;
}
static int sock_close(struct inode *inode, struct file *filp)
{
__sock_release(SOCKET_I(inode), inode);
return 0;
}这里的sock->ops->release指针函数就根据传输层的协议不同,指向不同的函数,由于我们这里是TCP,所以最后调用inet_stream_ops->release
TCP关闭调用过程
close(socket_fd)
|
f_op->release
|---sock_close
|---sock->ops->release
|--- inet_stream_ops->release(tcp_close)tcp_close
/* net/ipv4/tcp.c */
void tcp_close(struct sock *sk, long timeout)
{
struct sk_buff *skb;
int data_was_unread = 0;
int state;
lock_sock(sk);
sk->sk_shutdown = SHUTDOWN_MASK;
if (sk->sk_state == TCP_LISTEN) {
// 套接字处于Listen状态,将状态调整未close
tcp_set_state(sk, TCP_CLOSE);
inet_csk_listen_stop(sk);
goto adjudge_to_death;
}
// 清空buffer
while ((skb = __skb_dequeue(&sk->sk_receive_queue)) != NULL) {
u32 len = TCP_SKB_CB(skb)->end_seq - TCP_SKB_CB(skb)->seq;
if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN)
len--;
data_was_unread += len;
__kfree_skb(skb);
}
sk_mem_reclaim(sk);
if (sk->sk_state == TCP_CLOSE)
goto adjudge_to_death;
// ...
} else if (tcp_close_state(sk)) { // 将状态设为fin_wait
tcp_send_fin(sk); // 调用tcp_send_fin(sk)
}
sk_stream_wait_close(sk, timeout);
adjudge_to_death:
// ...
}
EXPORT_SYMBOL(tcp_close);现在进入了tcp关闭连接的关键部分,先关闭者将套接字状态由listen设为close,然后清空发送区缓存,接着通过tcp_send_fin来发送fin请求,自身进入fin_wait1状态。
第一次挥手
/* net/ipv4/tcp_output.c */
void tcp_send_fin(struct sock *sk)
{
......
// 设置flags为ack|fin
TCP_SKB_CB(skb)->flags = (TCPCB_FLAG_ACK | TCPCB_FLAG_FIN);
......
// 发送fin包
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_OFF);
}接着等待另一方回应,处理TCP不同状态码的函数为net\ipv4\tcp_input.c中的tcp_rcv_state_process
case TCP_FIN_WAIT1: {
int tmo;
if (req)
tcp_rcv_synrecv_state_fastopen(sk);
if (tp->snd_una != tp->write_seq)
break;
tcp_set_state(sk, TCP_FIN_WAIT2);
sk->sk_shutdown |= SEND_SHUTDOWN;
sk_dst_confirm(sk);
if (!sock_flag(sk, SOCK_DEAD)) {
/* Wake up lingering close() */
sk->sk_state_change(sk);
break;
}
if (tp->linger2 < 0) {
tcp_done(sk);
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA);
return 1;
}
if (TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq &&
after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt)) {
/* Receive out of order FIN after close() */
if (tp->syn_fastopen && th->fin)
tcp_fastopen_active_disable(sk);
tcp_done(sk);
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA);
return 1;
tmo = tcp_fin_time(sk);
if (tmo > TCP_TIMEWAIT_LEN) {
inet_csk_reset_keepalive_timer(sk, tmo - TCP_TIMEWAIT_LEN);
} else if (th->fin || sock_owned_by_user(sk)) {
inet_csk_reset_keepalive_timer(sk, tmo);
} else {
tcp_time_wait(sk, TCP_FIN_WAIT2, tmo);
goto discard;
}
break;
}MenuOS运行跟踪
- [ ] MenuOS 运行跟踪
Qmenu中启动MenuOS,进入调试
上上次实验编译了一个带调试功能,且带有TCP服务器和客户端的MenuOS系统
同样打开一个终端,进入LinuxKernel目录,启动之前编译好的带调试的MenuOS
~$ cd LinuxKernel
~/LinuxKernel$ qemu-system-i386 -kernel linux-5.4.2/arch/x86/boot/bzImage -initrd rootfs.img -append "root=/dev/sda init=/init nokaslr" -s -S进入调试
这时候虚拟机进入停止在一个黑屏界面,等待gdb的接入和下一步指令。
新开一个终端窗口,进入gdb调试。
接着分别
- 导入符号表
- 连接调试服务器
- 设置断点
jett@ubuntu:~/LinuxKernel$ gdb
(gdb) file ~/LinuxKernel/linux-5.4.2/vmlinux
Reading symbols from ~/LinuxKernel/linux-5.4.2/vmlinux...done.
(gdb) target remote:1234
Remote debugging using :1234
0x0000fff0 in ?? ()
(gdb) break start_kernel
Breakpoint 1 at 0xc1db5885: file init/main.c, line 576.然后输入c让系统继续执行,执行到断点start_kernel ()则说明成功。
(gdb) c
Continuing.
Breakpoint 1, start_kernel () at init/main.c:576
576 {添加新断点sys_close
(gdb) b sys_close
Breakpoint 3 at 0xc119fe60: file fs/open.c, line 1191.
(gdb) info b # 查看设置的断点
Num Type Disp Enb Address What
1 breakpoint keep y 0xc1db5885 in start_kernel at init/main.c:576
2 breakpoint keep y 0xc179ce00 in __se_sys_socketcall at net/socket.c:2818
3 breakpoint keep y 0xc119fe60 in __se_sys_close at fs/open.c:1191c让系统继续执行
作者:SA19225176,万有引力丶