本文只是萌新初步了解JVM,本来打算写给自己看的,由于知识有限,写得不好甚至有错,欢迎指正
1. 程序的运行流程
我们coding完后点击IDE的运行,程序就跑起来了,怎么回事?
首先我们写的源文件叫.java文件,然后点击IDE的运行在硬盘会生成.class字节码文件,接着Java虚拟机从硬盘加载.class字节码文件,再者内部操作和解析成电脑能识别的机器码,最后CPU执行
我们要重点关注的下面框框的部分,也就是JVM了
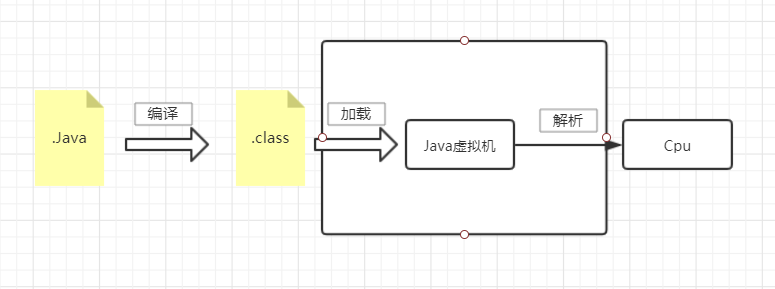
2. JVM
别那么着急,首先得看看JVM的体系结构:
- 类加载器(ClassLoader)用来加载.class文件
- 运行时数据区(方法区、堆、Java栈、本地方法栈、程序计数器),这么复杂先不要管他
- 执行引擎,来执行.class字节码文件或执行本地方法
这时上面框框的内容就可以稍微详细一点了
注意这时的图并不是完整且准确的,为了简便而改名或省略了,最后面会放出完整图的
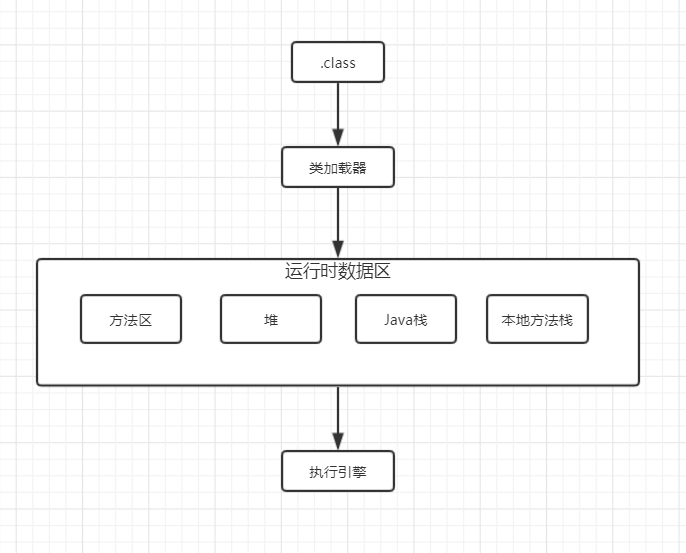
那么,我们从上往下开始认识这些结构
2.1 类加载器
负责加载.class字节码文件到 Java 虚拟机中
什么时候开始加载呢?
当然是动态加载的!即需要用到时才加载,这样节省了很多内存空间,防止内存溢出
用什么来加载.class文件呢?
那就是类的加载器了,类加载器默认有三种,还有一个自定义类加载器这里不讨论:
- Bootstrap ClassLoader,负责加载rt.jar里的所有类,rt.jar就是运行时的核心jar包
- Extension ClassLoader,负责加载java平台中扩展功能的jar包
- App ClassLoader,负责加载classpath中的jar包及目录中class,即自己编写的.class文件和开发jar包
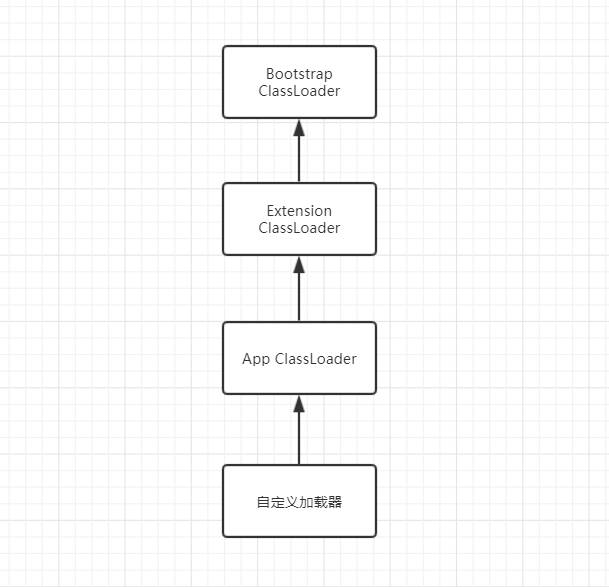
这里就有一个看起来高大尚的名词双亲委派,不用觉得很难,所谓的双亲委派指的是:
- 类加载器收到类加载请求后,首先把请求委派给父加载器,父加载器再向上委派,如此类推
- 如果顶级父类找不到这个要加载的类,则给子类加载器去加载,还是如此类推
为什么要双亲委派不麻烦吗?
为了安全性
- 防止内存中出现多份同样的字节码
- 还有防止覆盖重要类,比如我绕开编译器,在记事本写了一个Object类,加载时首先双亲就加载根类Object了,我写的Object就不会被加载
还有某个类被加载后就会把类的实例放到内存中,下次直接用内存中实例,不用再次加载了
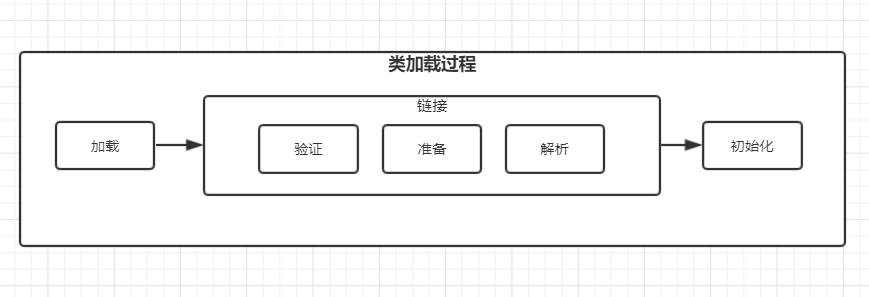
类的加载过程
加载过程分类三步:
- 加载,加载.class文件到JVM,并创建对应类的实例
- 链接,又分三步:
- 验证,文件格式、元数据、字节码、符号引用验证
- 准备,为类的静态变量分配内存,并将其初始化为默认值
- 解析,将类的二进制数据中的符号引用替换成直接引用
- 符号引用,用符号表示引用的目标,比如java.lang.System.out.println()代表了该类,还没有被加载
- 直接引用,直接指向目标的指针,已经加载了
- 初始化,为类的静态变量赋予给定的初始值,原本的初始值是0或null
2.2 运行时数据区
类加载完后就开始给新生对象分配内存了,先来look look 虚拟机的内存结构把
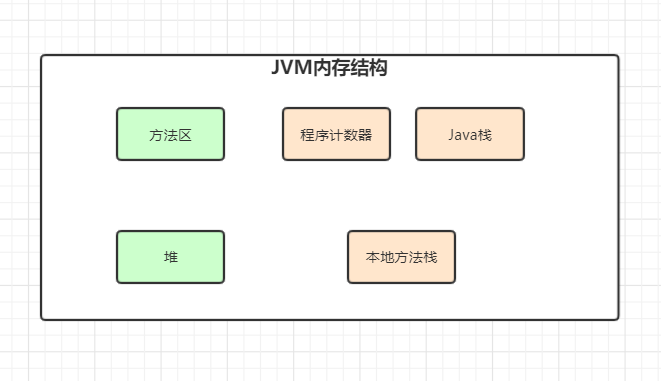
浅绿色为线程共享
浅橙色为线程私有
其中:
- 方法区,存储类的元数据信息,常量,静态变量
- 堆,存放对象实例(太多会内存溢出)
- Java栈,执行方法会被压入一个栈帧(包含了局部变量,方法出口等,递归太多栈空间越大)
- 本地方法栈,执行本地方法的
- 程序计数器,当前线程所执行的字节码的行号指示器
简述一下内存分配
准备了两个类
public class BeanTest {
private int id;
private String name;
//各种Getters/Setters
}public class JVMTest {
public static void main(String[] args) {
BeanTest beanTest = new BeanTest();
beanTest.setName("Howl");
System.out.println(beanTest.getName());
}
}- JVMTest首先被加载到JVM的方法区,存储类的元数据信息,比如类名,类的方法等
- 找到JVMTest方法入口(main),为main创建栈帧压入栈,执行函数
- 执行第一条语句,
BeanTest beanTest = new BeanTest();,方法区没有这个类的元数据,动态加载 - 加载后为BeanTest实例在堆中分配内存,然后调用构造函数初始化该实例(该实例持有指向方法区对应类的元数据,后面有用)
- 执行第二条语句,
beanTest.setName("Howl");,该实例根据指向去方法区找到对应类的元数据(方法表),获取对应函数的字节码地址 - 为该函数创建栈帧,执行函数,执行完退栈,如此类推
2.3 执行引擎
当然是根据调配的指令顺序,依次执行程序指令拉
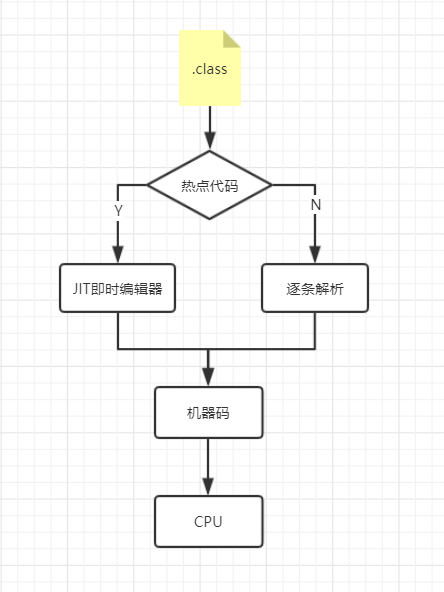
这里面有个技术需要讲一下下,JIT即时编辑器
JVM加载了.class文件后逐条读取并解析成机器码给CPU执行,我们当然不满足于此,有没有方法提高效率呢?
答案是有的,用 JIT即时编辑器
思路是这样的:
- 对于热点代码(经常使用的代码,多次调用的方法,循环体),我们重新编译,优化给CPU执行,这部分优化的代码会提高效率
- 因为重新编译也需要内耗,所以我们只对热点代码重编,对于其他代码就直接解析器解析给CPU执行了
我们Sun公司使用的虚拟机是HotSpot,它采用计数器的方式(方法调用计数器,回边计数器)来判断是否为热点代码,当超过一定的数值时判断为热点代码
3. 整合图
是时候放出稍微标准的图了,顺带提一下没有讲到的内容
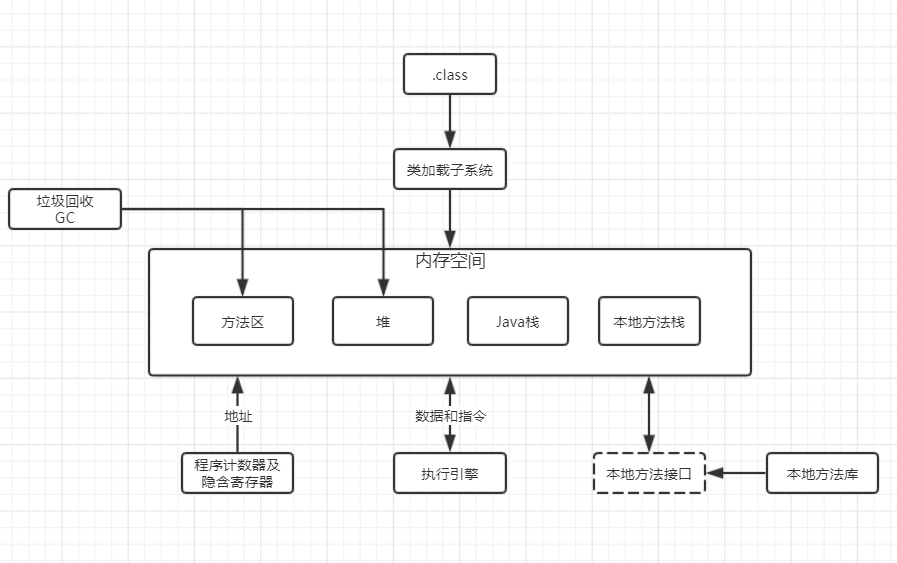
3.1 垃圾回收(GC)
程序在运行过程中,虚拟机会自动帮我们清理程序中不再需要的垃圾,减轻内存负担。
堆是垃圾回收的主战场,里面存放了大量实例
不像C语言,申请空间后需要free()来释放空间,但也不要因为有垃圾回收就不理会内存了
怎么判断是否为垃圾呢?
- 引用计数法(被引用时数量+1,引用失效-1,一直为0即为垃圾,但不能解决循环引用)
- 可达性分析算法(暂时不会,有时间回来填坑)
判断完就到回收垃圾了(回来填坑把)
- 标记-清除算法
- 复制算法
- 标记-整理算法
- 分代收集算法
over over over
3.2 JVM参数与调优
配置元空间的初始值和最大值,设置堆空间的初始值和最大值。
-XX:MetaspaceSize=128M -XX:MaxMetaspaceSize=256M -Xms256m -Xmx256m具体大小设置还得看环境,以及不敢自作聪明,回来填坑
参考
工具