前言
- 严寒酷暑,晚上进入理发店准备剪头时翻开班群消息。
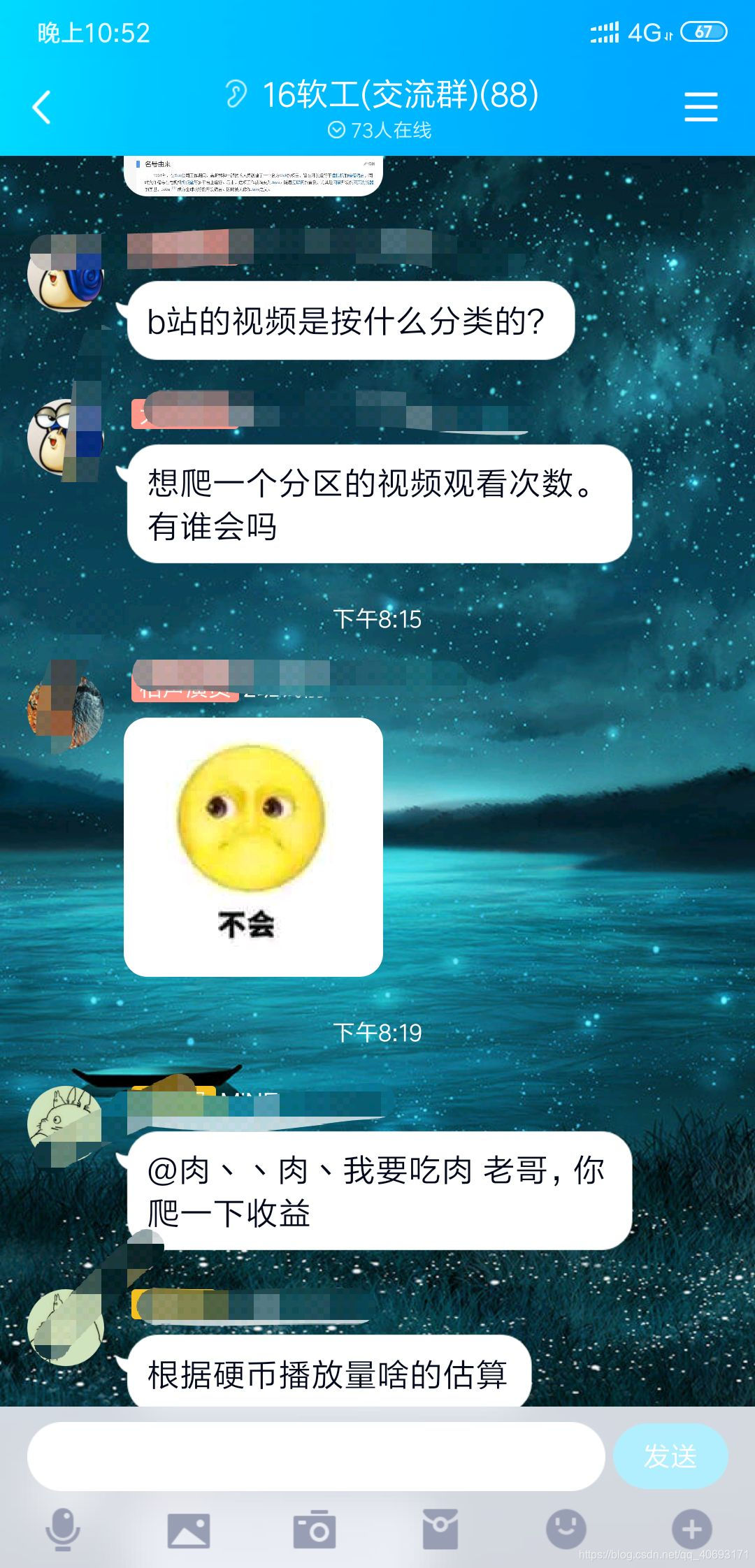
- 勾起了我的兴趣,理发店人有点小多,回去瞅瞅吧。因为知道B站技术还是不错的。可能有难度。
分析
- 抱着看一看,玩一玩的态度,开始B站分析之旅。由于时间精力有限,不做太详细说明。
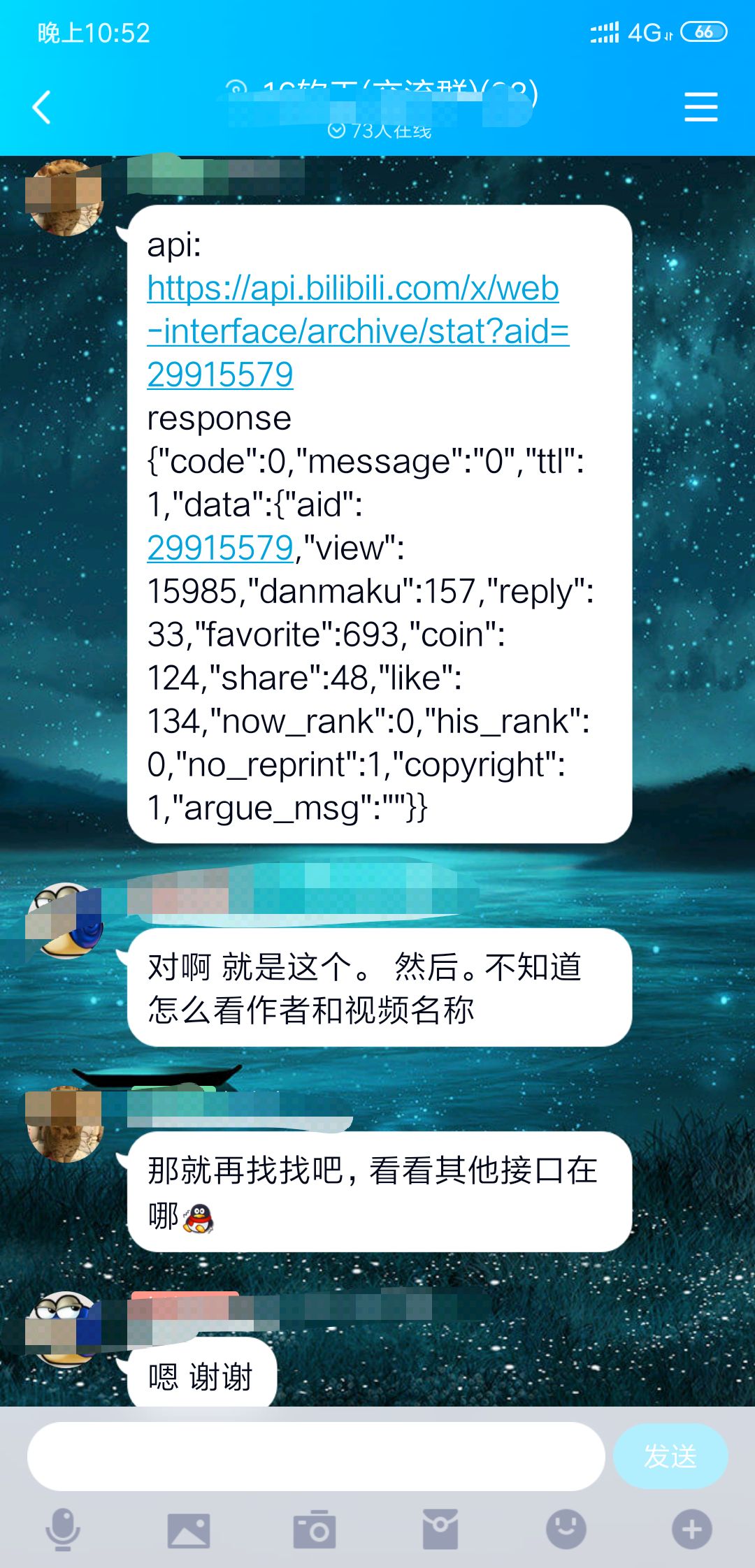
- B站的信息。第一想到肯定
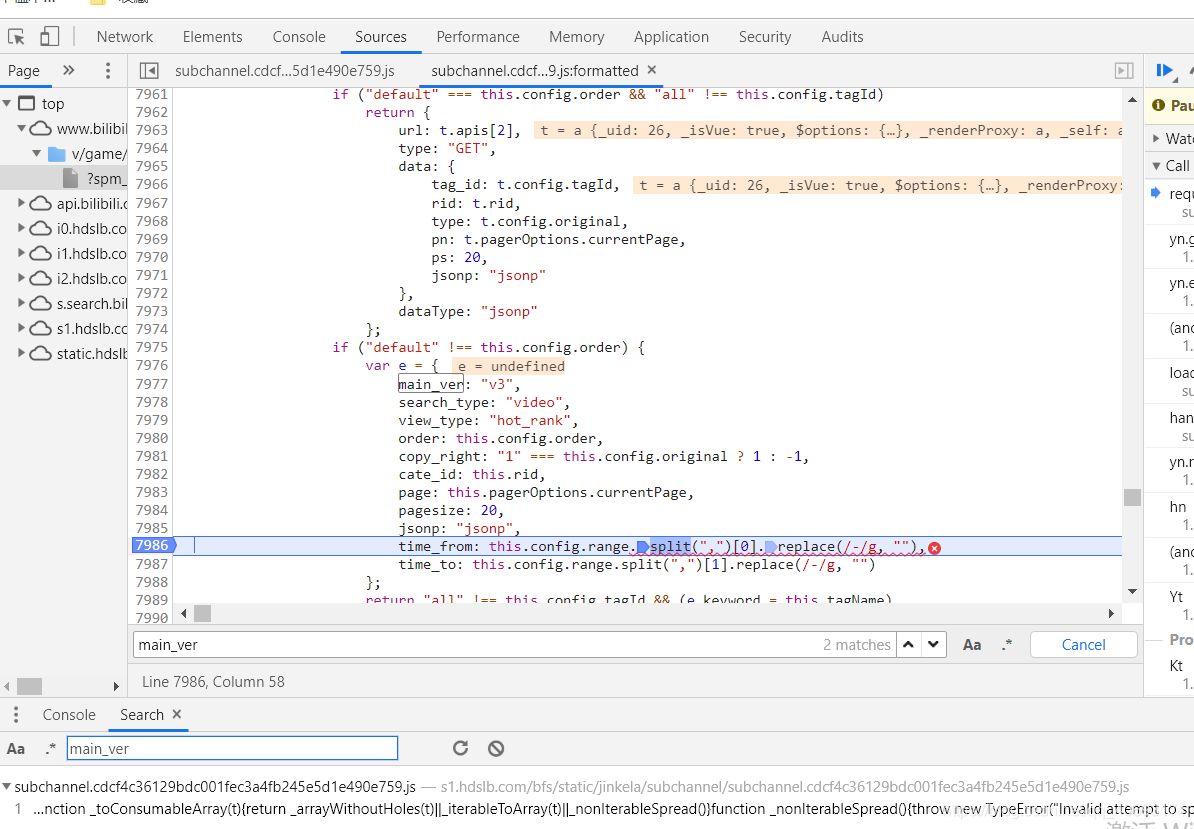
不可能直接渲染,只有比较old的网站现在才会渲染到html。我想他的数据肯定时js渲染或者ajax渲染进去的。然而,换页发现url会变化,并且xhr没有我们想要的数据。虽然url会变化但是查看源码依然找不到想要的数据。
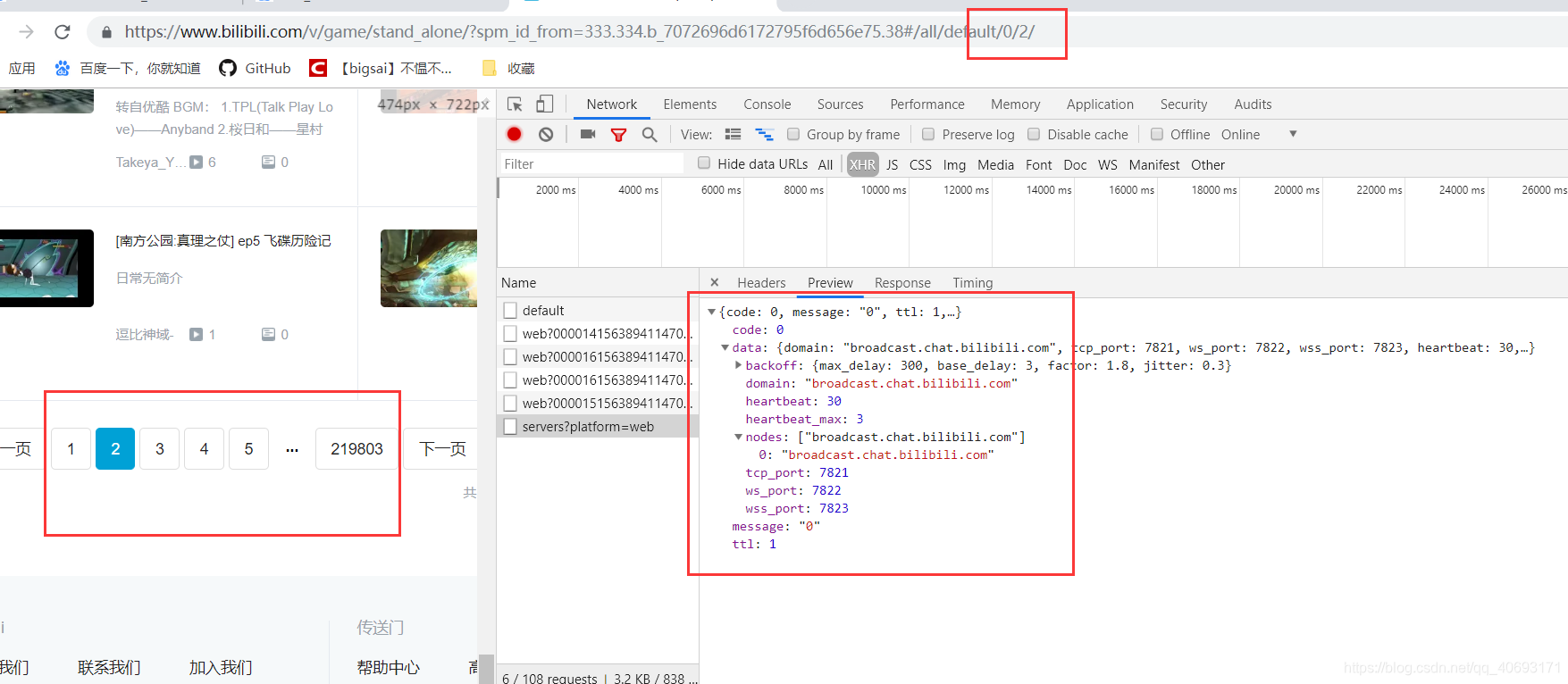
- websocket 也没有传输数据。那么范围就肯定大概率在js里面了。一查找,数据果然藏在js里面。通过
js的文件解析进行渲染。有点骚。
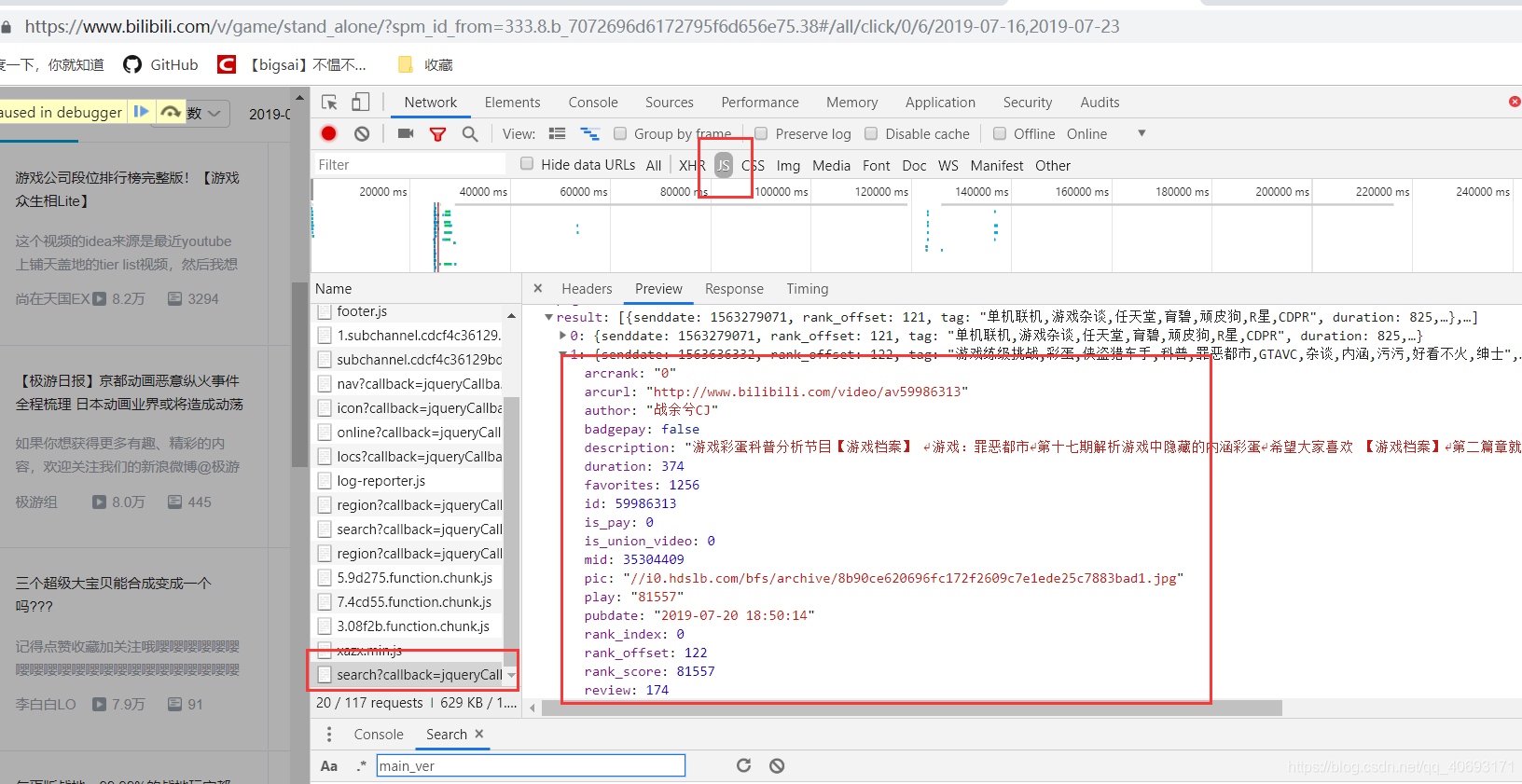
- 想要的数据应有尽有,只需要对文本进行分割即可获得一个json文件。问题来了。js参数那么多,
是否有设置加密呢。点了两个发现有的参数确实会变化。


- 我不知道它是否会对我造成影响。简单搜搜参数,debug一下,发现好像
没有什么特别需要的参数。直接更改页数应该可以。我在浏览器测试了一下,参数删除丝毫不影响,如果影响也没时间研究加密就算了,ok,没问题。
编写爬虫
好了。这个数据来源没加密,无cookie加密验证,很好搞,只需要根据专栏url,修改页数就ok。
import requests
from bs4 import BeautifulSoup
import json
import urllib.parse
## 只需要更改page
url="https://s.search.bilibili.com/cate/search?callback=jqueryCallback_bili_&main_ver=v3&search_type=video&view_type=hot_rank&order=click©_right=-1&cate_id=17&pagesize=20&jsonp=jsonp&time_from=20190716&time_to=20190723&_=1"
data={'page':1}
for page in range(1,10):
data['page']=page
req=requests.get(url,data=data)
res=req.text
res=res.replace("jqueryCallback_bili_","")
res=res[1:(len(res)-1)]
res=json.loads(res)
result=res['result']
for val in result:
print(val['author'],'播放:',val['play'],'喜欢',val['favorites'],'review',val['review'])
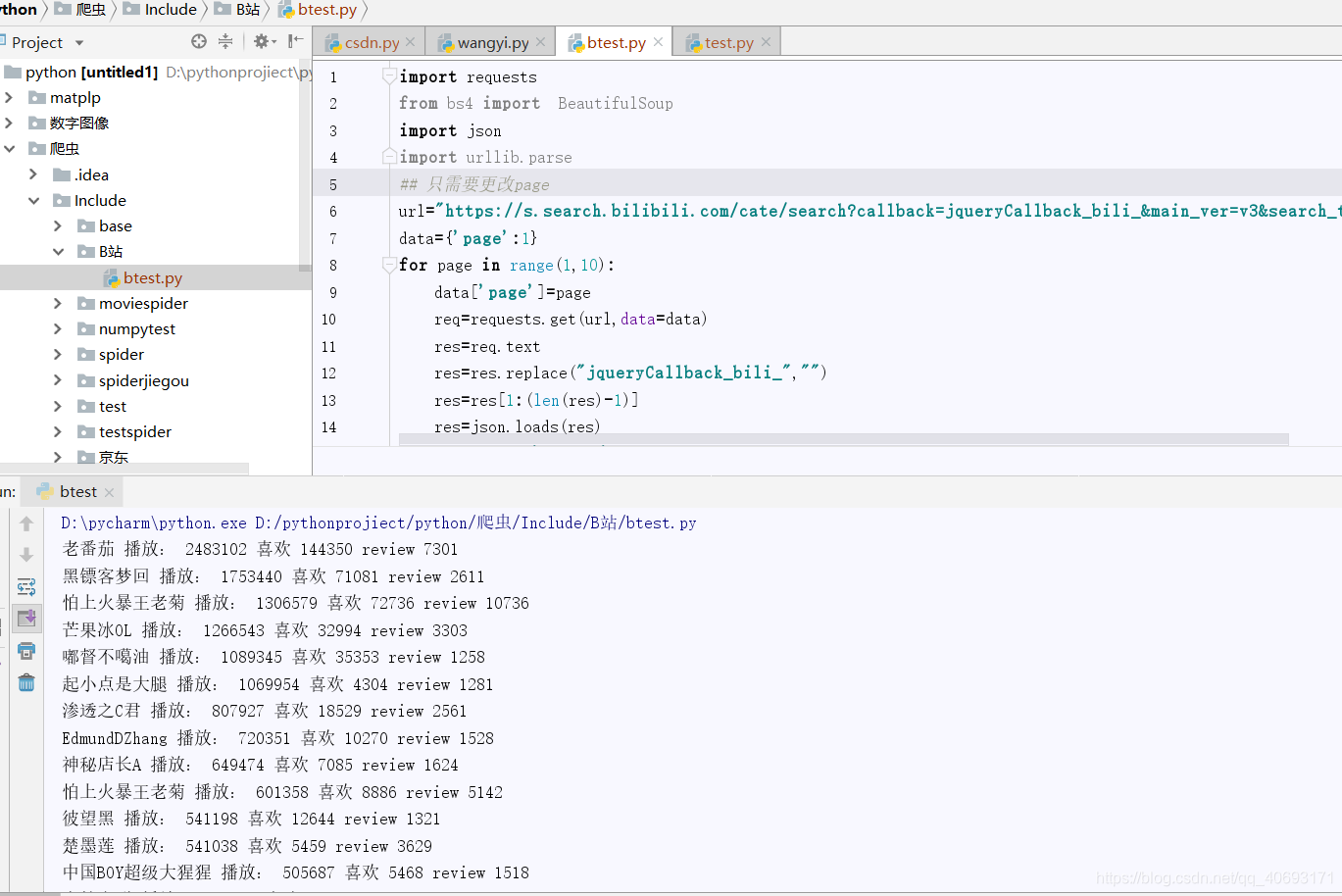
- 好了,存储那些就不是我的事了。大胆分析就ok,不算难,就是挺新的在js藏数据。
- 迎关注我的个人公众号交流:
bigsai

