记录一下最近学习的最简单的k-近邻算法入门。
文章和别人的相似甚至神似,为什么会这样呢?因为是踩着前人的肩膀过来的吖。
1. 何为 k-近邻算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
该方法的思路是:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。
2. 实现原理与优缺点
用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
换句话说就是: 样本已知属性、新样本暂未知属性。先求出两点之间的距离,新样本的属性即为 离样本最近的样本属性。
以下关于k-近邻算法的优缺点引自–机器学习–K近邻 (KNN)算法的原理及优缺点。
算法优点:
- 简单,易于理解,易于实现,无需估计参数。
- 训练时间为零。它没有显示的训练,不像其它有监督的算法会用训练集train一个模型(也就是拟合一个函数),然后验证集或测试集用该模型分类。KNN只是把样本保存起来,收到测试数据时再处理,所以KNN训练时间为零。
- KNN可以处理分类问题,同时天然可以处理多分类问题,适合对稀有事件进行分类。
- 特别适合于多分类问题(multi-modal,对象具有多个类别标签), KNN比SVM的表现要好。
- KNN还可以处理回归问题,也就是预测。
- 和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感。
算法缺点:
- 计算量太大,尤其是特征数非常多的时候。每一个待分类文本都要计算它到全体已知样本的距离,才能得到它的第K个最近邻点。
- 可理解性差,无法给出像决策树那样的规则。
- 是慵懒散学习方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢。
- 样本不平衡的时候,对稀有类别的预测准确率低。当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
- 对训练数据依赖度特别大,对训练数据的容错性太差。如果训练数据集中,有一两个数据是错误的,刚刚好又在需要分类的数值的旁边,这样就会直接导致预测的数据的不准确。
3. 代码示例
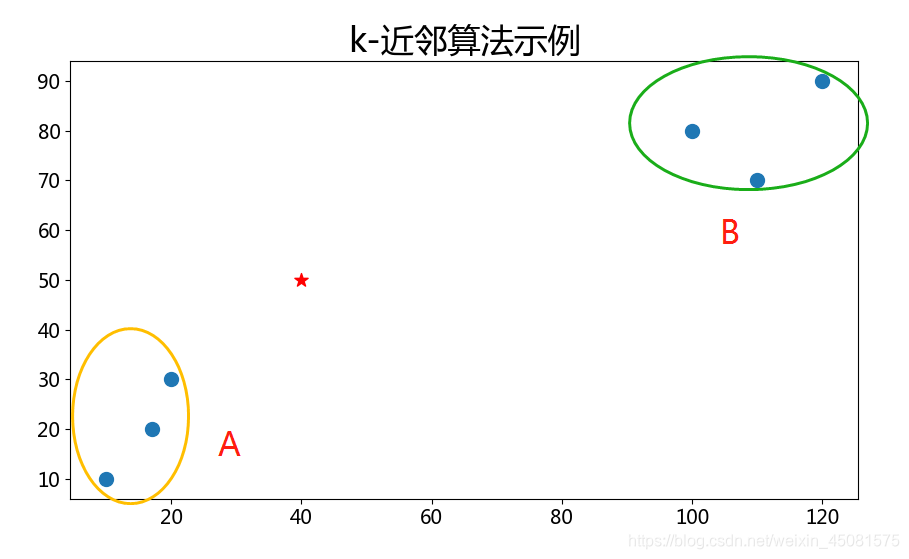
先看下面一个例子,分类主要依据是X轴和Y轴的数值。(不严谨之处,请谅解)

在这里会用到高中时候学习的两点之间的距离公式,当然了,这里的距离是二维坐标。
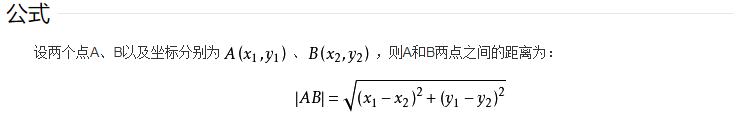
有黄色A和绿色B两类样本数据,现在新增了一个星号数据,那么这个星号数据是从属于哪一类呢?
虽然看上去就是属于A类,但是只要看上去那这篇文章就毫无意义了。
下面用代码来实现一下。
首先是样本数据集。
import numpy as np
# dataset()为训练数据集
def dataset():
"""
:return: 返回样本数据以及标签
"""
# dataset_为训练数据集, lables为数据集对应的标签
dataset_ = np.array([[10, 10], [17, 20], [20, 30], [100, 80], [110, 70], [120, 90]])
lables = ['A', 'A', 'A', 'B', 'B', 'B']
return dataset_, lables
python实现 k-近邻算法。
def classify_knn(new_array, dataset, lables, k):
"""
:param new_array: 新实例
:param dataset: 训练数据集
:param lables: 训练集标签
:param k: 最近的邻居数目
:return: 返回算法处理后的结果
"""
# np.shape是取数据有多少组,然后生成tile生成与训练数据组相同数量的数据
# 然后取平方
# np.sum(axis=1) 取行内值相加,然后开发,求出两点之间的距离
datasetsize = dataset.shape[0]
diffmat = np.tile(new_array, (datasetsize, 1)) - dataset
sqrdiffmat = diffmat ** 2
distance = sqrdiffmat.sum(axis=1) ** 0.5
# np.argsort将数值从小到大排序输出索引
# dict的get返回指定键的值,如果值不在字典中返回默认值。
# 根据排序结果的索引值返回靠近的前k个标签
sortdistance = distance.argsort()
count = {}
for i in range(k):
volelable = lables[sortdistance[i]]
count[volelable] = count.get(volelable, 0) + 1
count_list = sorted(count.items(), key=lambda x: x[1], reverse=True)
return count_list[0][0]
if __name__ == '__main__':
dataset, lables = dataset()
result = classify_knn([40, 50], dataset, lables, 5)
print(result) # A
星号坐标为[10, 50]时候,返回的结果为A,
星号坐标为[100, 10]时候,返回的结果为B。
bingo!!!
4. 总结
三个步骤:
- 准备训练数据集
- 计算新的实例与训练数据集最邻近的K个实例
- 得出结果
因为个人功底太差,这个机器学习入门的k-近邻算法我花了好几个小时才弄明白一丢丢。说出来真是贻笑大方。
文章有错漏之处,恳请各位不吝指正。
完。
