Spark代码可读性与性能优化——示例十(项目结构)
其他
2020-01-11 00:13:06
阅读次数: 0
Spark代码可读性与性能优化——示例十(项目结构)
前言
安排好每个包下的类
- 安排好各个包的功能,可以方便查看项目代码结构,明确功能,有利降低开发的混乱度
- 在这里,举一个可供参考的示例,如下
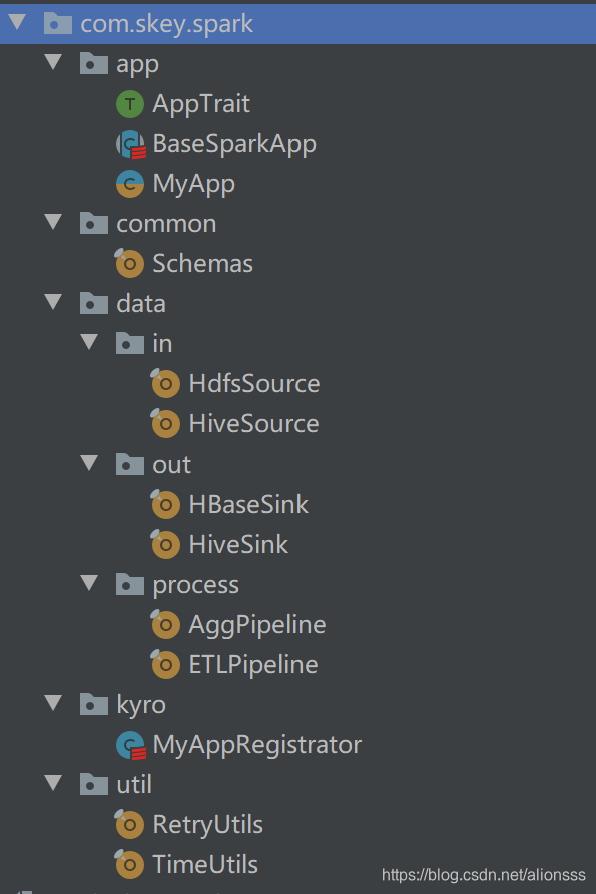
- 解释
- app 用于存放开发的Spark应用
- common 用于存放通用的配置,或者某个功能引擎
- data.in 用于存放数据源获取功能
- data.out 用于存放数据输出功能
- data.process 用于存放数据处理功能
- kyro 用于为每个Spark配置对应的kyro注册
- util 用于工具包
为Spark应用设计一个模板基类
- 设计一个模板基类能够更好的控制代码的运行流程,分清代码结构,提高可读性,有利于项目的后期维护
- 那么, 在这里举一个可供参考的示例,如下
- AppTrait
/**
* Spark应用Trait
* <p>
* Date: 2018/3/2 9:49
* @author ALion
*/
trait AppTrait {
/**
* 初始化,应用运行前
*/
protected def onInit(): Unit
/**
* 应用开始运行
*/
protected def onRun(): Unit
/**
* 应用结束
*/
protected def onStop(): Unit
/**
* 应用销毁后调用
*/
protected def onDestroyed(): Unit
}
- BaseSparkApp
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* Spark应用基类
* <p>
* Date: 2018/1/19 15:06
*
* @author ALion
*/
abstract class BaseSparkApp extends AppTrait {
protected final val appName = getClass.getSimpleName
protected final var spark: SparkSession = _
/**
* 启动应用
*/
final def startApp(): Unit = {
val time1 = System.currentTimeMillis()
println("-------> " + appName + " start ")
onInit()
createSession()
onRun()
onStop()
val time2 = System.currentTimeMillis()
println("-------> " + appName + " end costTime=" + (time2 - time1) / 1000 + "s")
}
/**
* 手动停止应用
*/
final def stopApp(): Unit = {
onStop()
}
/**
* 创建 SparkSession
*/
private def createSession(): Unit = {
spark = SparkSession.builder()
.config(getConf)
.enableHiveSupport()
.getOrCreate()
}
/**
* Spark应用配置
*
* @return SparkConf
*/
protected def getConf: SparkConf = {
new SparkConf()
.setAppName(appName)
.set("spark.network.timeout", "300")
.set("spark.shuffle.io.retryWait", "30s")
.set("spark.shuffle.io.maxRetries", "12")
.set("spark.locality.wait", "9s")
}
/**
* 初始化,应用运行前
*/
override protected def onInit(): Unit = {}
/**
* 应用运行
*/
override protected def onRun(): Unit
/**
* 应用结束
*/
override protected def onStop(): Unit = {
if (spark != null) spark.stop()
}
/**
* 应用销毁后调用
*/
override protected def onDestroyed(): Unit = {}
}
- 解释一下
- 开Spark应用时,需要从BaseSparkApp继承
- AppTrait 用于描述一个应用的基本特征
- BaseSparkApp 是实际的模板类,用于控制应用流程
- startApp 调用该方法即可启动应用
- 控制代码流程,同时该方法为final,防止继承者私自修改代码运行流程
- 附加一些功能,例如此处的时间统计
- onInit 用于在应用启动前调用
- 在创建SparkSession之前调用,需要使用时override即可
- 可以存放初始化代码块,例如从其他源获取数据请在此处初始化。防止程序员偶然写错代码位置,再启动Spark后不用,又花时间去执行其他代码,无意义的浪费集群资源。
- createSession 用于创建SparkSession
- 在onInit之后调用
- 需要修改创建的SparkConf,只需复写getConf方法即可
- onRun 真正的业务处理代码
- 在createSession后调用
- 提供全局变量spark使用,在此处编写你的业务逻辑代码
- onStop 用于自动关闭Spark应用
- 在onRun之后自动调用
- 业务结束后,强制关闭Spark(Spark有时候会因为一些问题卡住,或等一会儿才会关闭,或者你在Spark应用中还有其他一些代码要消耗时间)
- 同时也是防止你忘记调用spark.stop()
- onDestroyed 应用销毁
- 在onStop后调用
- 有的后续业务根本就不需要Spark环境,不要一直占用着集群资源
- 例如,业务开发中,Spark应用运行完后可能会需要对其他服务做一个通知,那么就应该在stop之后做(也就是onDestroyed处)
发布了128 篇原创文章 ·
获赞 45 ·
访问量 15万+
转载自blog.csdn.net/alionsss/article/details/103809483
