1、list、ndarray、Series的简单比较
- list列表,列表中的元素可以是不同的数据类型,使用从0开始的整数值作为默认索引;
- ndarray数组,数组中的元素必须是同种数据类型,也是使用从0开始的整数值作为默认索引;
- Series序列,是一种一维的结构,类似于一维列表和ndarray中的一维数组,但是功能比他们要更为强大,Series由两部分组成:索引index和数值values;
- 一维列表和一维数组中都是采用从0开始的整数值作为默认索引,索引值一般不显示的给出,但是我们可以通过索引去获取其中的元素。对于Series来说,默认索引也是从0开始的整数值作为默认索引,但是是显示地给出,更为强大的是,Series中的索引可以随意设置,方便我们取数。
操作如下:
import numpy as np
import pandas as pd
l1 = [1,2,"中国",4.5]
display(l1)
display(l1[2])
a1 = np.array([1,2,5,6,8])
display(a1)
display(a1[4])
s1 = pd.Series([1,3,5,7,9])
display(s1)
display(s1[4])
s2 = pd.Series([1,3,5,7,9],index=["a","b","c","d","e"])
display(s2)
display(s2["d"])
display(s2[3])
s3 = pd.Series([1,3,5,7,9],index=[3,4,5,6,7])
display(s3)
display(s3[6])
结果如下:

通过上述测试,我们可以总结出来这第5条结论:
- 创建Series序列时,当不指定索引的时候,默认使用的从0开始的整数索引;当自己指定了字符串索引,既可以通过这个字符串索引访问元素,也可以通过默认的整数索引访问元素;当自己指定一个整数索引,那么该索引会覆盖掉原有的默认的整数索引,只能通过这个新的整数索引访问元素,默认的整数索引会失效。
2、Series的5种常用创建方式
- 创建Series的语法:pd.Series();
- 常用的几个参数:index,用于指定新的索引;dtype,用于指定元素的数据类型;
- 大前提:要记住Series是一个一维的结构!!!
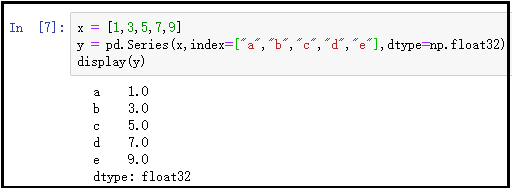
1)通过一维列表创建Series
x = [1,3,5,7,9]
y = pd.Series(x,index=["a","b","c","d","e"],dtype=np.float32)
display(y)
结果如下:
2)通过可迭代对象创建Series
x = range(2,7)
y = pd.Series(x)
display(y)
结果如下:

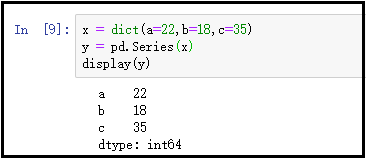
3)通过字典创建Series
x = dict(a=22,b=18,c=35)
y = pd.Series(x)
display(y)
结果如下:
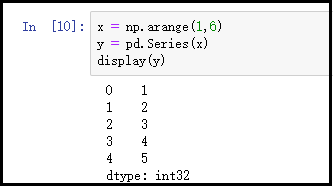
4)通过一维数组创建Series
x = np.arange(1,6)
y = pd.Series(x)
display(y)
结果如下:
5)通过标量(常数)创建Series
x = 22
y1 = pd.Series(x)
display(y1)
y2 = pd.Series(x,index=list(range(5)))
display(y2)
结果如下:
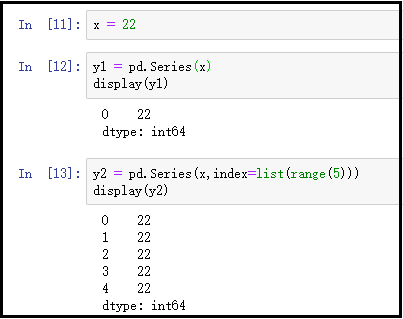
注意:使用标量创建一个含有相同元素的Series,元素的个数取决于我们设置的索引的个数。
3、Series中常用属性说明
1)Series和ndarray中常用属性对比
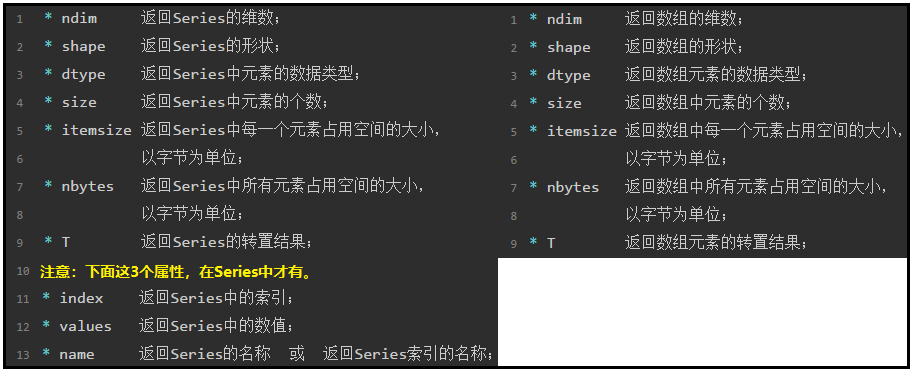
操作如下:
s = pd.Series([1,3,5,7,9])
display(s)
display(s.ndim)
display(s.shape)
display(s.dtype)
display(s.size)
display(s.itemsize)
display(s.nbytes)
display(s.T)
结果如下:

注意:
① 由于Series是一维的结构,因此Series的ndim的值肯定是1;
② 关于itemsize和nbytes这两个属性的具体用法,可以参考我下面这篇文章
https://blog.csdn.net/weixin_41261833/article/details/103847502
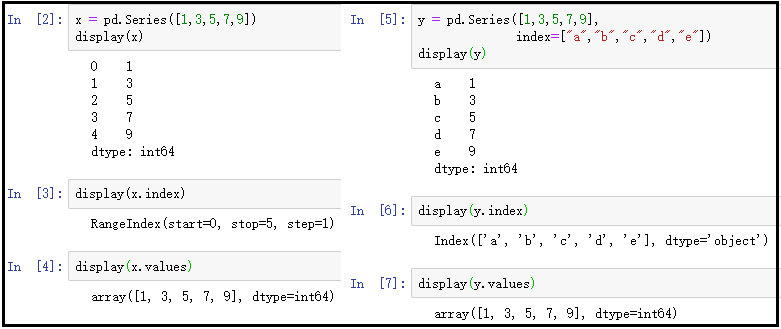
2)Series中特有的几个属性:index、values、name
① index和values属性
x = pd.Series([1,3,5,7,9])
display(x)
display(x.index)
display(x.values)
结果如下:
② name属性:动态创建Serie名称和Series索引名称
x = pd.Series([1,3,5,7,9])
display(x)
x.name = "Series的名称"
x.index.name= "Series索引的名称"
display(x)
display(x.name)
display(x.index.name)
结果如下:

③ 在创建Series的时候,指定Series名称
y = pd.Series([1,3,5,7,9],index=["a","b","c","d","e"],name="Series的名称")
display(y)
display(y.index.name)
display(y.name)
结果如下:
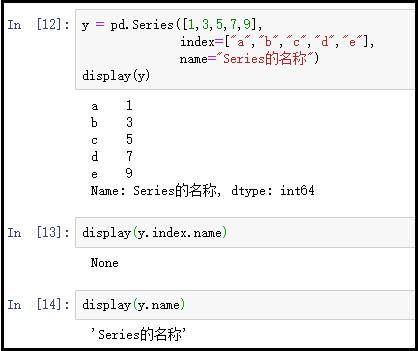
注意:目前可能看不出来,指定这个索引名称的好处在哪里,这个在学习DataFrame的时候,会得到很好的体现。
