目录
一、业务需求
根据网站或app应用每天生成的用户日志数据放在大数据平台中来统计出PV(访问量)和UV(独立访客)
二、业务实现方案
1.技术栈
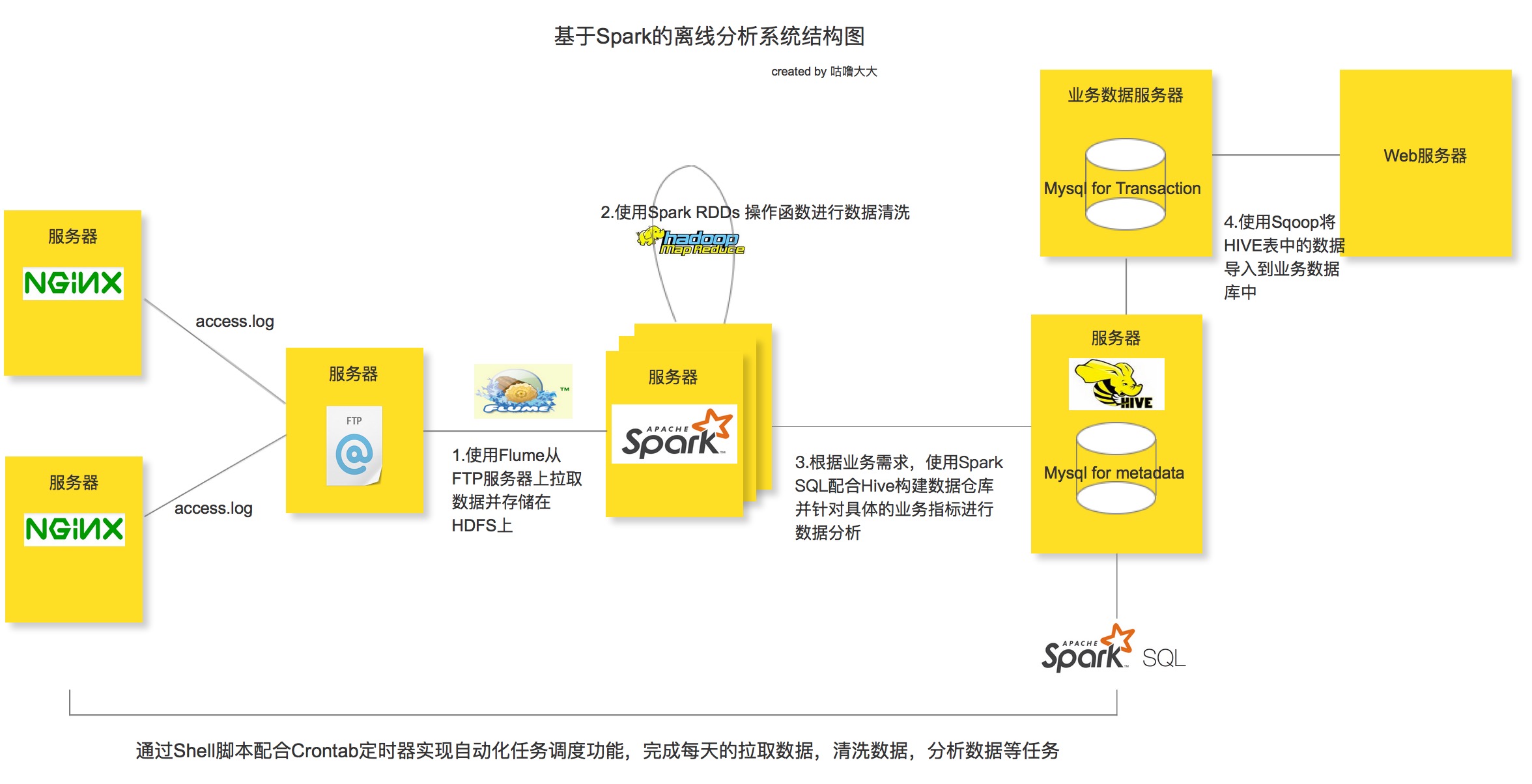
Hadoop CDH(大数据集群管理)+Flume(数据采集)+Spark(数据计算分析)+Hive(数据仓库)+Sqoop(数据同步)+MySQL
2.业务实现流程
- 搭建Hadoop CDH集群管理平台
- Flume将网站日志数据采集到Hadoop中的HDFS分布式存储系统中
- Spark SQL清洗存储在HDFS的网站日志数据,清洗完后将其数据继续存储在HDFS中
- Hive建立数据仓库,建立外部表,将清洗完的日志数据从HDFS中导入到Hive的外部表中,作为基础数据的存储
- 在Hive中新建新的外部表用于存储PV、UV的结果数据
- 用Hive的HQL统计分析日志数据,统计出PV、UV并将结果数据存到新的外部表中
- 将统计完的PV、UV数据使用Sqoop从Hive同步到外部的MySQL中供给WEB前端使用
3.离线分析系统架构图
三、技术实现
1.Hadoop CDH集群管理平台
一般都是运维去搭建,如果想要自己搭建只能查资料采坑跳坑了。
2.Flume采集服务器日志数据到HDFS
cd 执行代码目录
vi hdfs-avro.confhdfs-avro.conf文件内容:
#定义agent名, source、channel、sink的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置Source
a1.sources.r1.type = exec
a1.sources.r1.channels = c1
a1.sources.r1.deserializer.outputCharset = UTF-8
# 配置需要监控的日志输出目录
a1.sources.r1.command = tail -F /home/data/nginx_log/access.log
#设置缓存提交行数
a1.sources.s1.deserializer.maxLineLength =1048576
a1.sources.s1.fileSuffix = .DONE
a1.sources.s1.ignorePattern = access(_\d{4}\-\d{2}\-\d{2}_\d{2})?\.log(\.DONE)?
a1.sources.s1.consumeOrder = oldest
a1.sources.s1.deserializer = org.apache.flume.sink.solr.morphline.BlobDeserializer$Builder
a1.sources.s1.batchsize = 5
#具体定义channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100
#具体定义sink
a1.sinks.k1.type = hdfs
#%y-%m-%d/%H%M/%S
#存储到hdfs的目录
a1.sinks.k1.hdfs.path = hdfs://ip:8020/nginx/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = nginx-%Y-%m-%d_%H
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.fileType = DataStream
#不按照条数生成文件
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollSize=0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#组装source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1设置定时任务,定时执行flume执行命令来采集日志数据
flume执行命令内容:
flume-ng agent \
--name a1 \
--conf-file /代码执行目录/hdfs-avro.conf \
--conf $FLUME_HOME/conf \
-Dflume.root.logger=INFO,console3.Spark SQL清洗数据
我是参考慕课网一个教程做的,感觉还不错;
视频教程:
链接: https://pan.baidu.com/s/1eNWYmM2ZMQAk7F02hunHWA 提取码: sk2u
博客教程记录:
一般的Hadoop CDH装的Spark版本都是1.X,Spark1.X版本的不能满足我们的代码实现要求,所以我们需要升级Spark,升级到2.X才能满足我们的代码需求。
Hadoop CDH 升级Spark教程:
PS:大概流程就是提交spark作业来清洗在HDFS中的数据,清洗完后继续存储到HDFS中。
4.建立Hive仓库并导入清洗完的数据
- 建立hive表用于存储清洗完的数据
hive (count_log)> create table date_clear(
> id string,
> url string,
> guid string,
> date string,
> hour string
> )
> row format delimited fields terminated by '\t';
insert into table date_clear
hive (count_log)> insert into table date_clear
> select id,url,guid ,substring(trackTime,9,2) date,substring(trackTime,12,2) hour from source_log;创建分区表(以日期和时间分区,方便实现每小时进行PV、UV统计)
- 方式一: 创建静态分区表
hive (count_log)> create table part1(
> id string,
> url string,
> guid string
> )
> partitioned by (date string,hour string)
> row format delimited fields terminated by '\t';
hive (count_log)> insert into table part1 partition (data='20150828',hour='18')
> select id,url,guid from date_clear where date;
hive (count_log)> insert into table part1 partition (date='20150828',hour='18')
> select id,url,guid from date_clear where date='28' and hour='18';- 创建动态分区表(会自动的根据与分区列字段名相同的列进行分区)使用动态分区表前,需要设置两个参数值
hive (count_log)> set hive.exec.dynamic.partition=true;
hive (count_log)> set hive.exec.dynamic.partition.mode=nonstrict;
hive (count_log)> create table part2(
> id string,
> url string,
> guid string
> )
> partitioned by (date string,hour string)
> row format delimited fields terminated by '\t';
hive (count_log)> insert into table part2 partition (date,hour)
> select * from date_clear;5.HQL统计分析PV、UV数据
写sql来统计分析出pv、uv并将结果存储到新的表中
统计PV:
select date,hour,count(url) PV from part1 group by date,hour;统计UV:
select date,hour,count(distinct guid) uv from part1 group by date,hour;6.Sqoop同步数据
使用Sqoop将存储在Hive中的PV、UV结果数据同步到外部的MySQL中
sqoop export \
--connect "jdbc:mysql://ip地址:3306/库名?useUnicode=true&characterEncoding=utf-8" \
--username 数据库账号 \
--password "数据库密码" \
--table resource_search2 \
--export-dir /user/hive/warehouse/fiveg.db/resource_search \
--input-null-string '\\N' \
--input-null-non-string '\\N' \
--input-fields-terminated-by '\t' \
--num-mappers 1 字段备注:
connect:数据库连接地址
username:数据库用户名
password:数据库密码
table:数据库表
export-dir:hive表对应的hdfs存储地址
7.代码分享
本博客涉及到的代码分享:
链接: https://pan.baidu.com/s/1G5t_C9K1QnjtB2ySqXFJ3g 提取码: vv9r
