上传文件、异步、初始化脚本
面试题:
项目中的静态文件处理(JS/CSS/image) 自己在机房内优化的方法:
1. Nginx/lighttpd(lighty-douban):Nginx 处理静态资源速度非常快,并且自身还带有缓存。
2. 80: Nginx -> {server config} -> django:8080 -> Static : folders -> 云存储
你了解CDN吗?能讲讲原理么?
扩展:如何更换CDN上的图片?改名大法
1. 请求加参数:
1. abc.jpg
2. abc.jpg?20191011111042asdflj2
3. abc.jpg?20191011111043
2. 改名
1. abc_201910111042.jpg
2. abc_md5.jpg
七牛云接入
- 注册七牛云账号
- 创建存储空间:Bucket -> 有独立的域名,可以访问
- 获取相关配置
- AccessKey:从个人中心-密钥管理里获得
- SecretKey:从个人中心-密钥管理里获得
- Bucket_name:我们自己新建的存储空间的名字
- Bucket_URL:建好的新存储空间的访问url
- 安装 qiniu SDK:
pip install qiniu - 根据接口文档进行接口封装
- 按照需要将上传、下载接口封装成异步任务
- 程序处理流程
- 服务端上传方式
- 用户图片先上传到我们的服务器上
- 然后,我们的程序再调用七牛云的api,将图片上传到七牛云
- 上传成功后,拼接 avatar 的图片 url 地址:
- 七牛云的Bucket_URL/filename,将 avatar 的图片 url 存入数据库
- 客户端直传
- 客户端图片直接上传到云服务
- 客户端将图片地址告诉服务端,服务端更新数据库
- 其实存在一个安全隐患
- 客户端先从服务端获取token,再上传
- 服务端上传方式
代码示例 使用了celery
#上传图片
def user_avatar(request):
#1.存下来
# 定义上传后保存的文件名
file_name =f'avatar-{request.user.id}.jpg'
# 上传后保存的路径
file_path = f'{settings.BASE_DIR}/static/{file_name}'
#接收上传文件内容
f = request.FILES['avatar']
with open(file_path,'wb+') as destination:
for chunk in f.chunks():
destination.write(chunk)
print('save local ok.')
user_id = request.user.id
#delay很重要!!!
upload_qiniu.delay(file_name, file_path, user_id)
return render_json('已经放入celery-redis队列中')
#这一步用异步celery
@celery_app.task
def upload_qiniu(file_name, file_path, user_id):
# 2.调用七牛云sdk上传
# 需要填写你的 Access Key 和 Secret Key 需要修改
access_key = 'KXfx2ZiBP311HkZZ8l8JHCmqlqPTJCK2sraihexx'
secret_key = 'pe5svTTUAJQoUPhppsf0Gg9wbEJiYahnRMAy1rxx'
# 要上传的空间
bucket_name = 'liu'
# 要上传的域名
bucket_domain = ' liu.s3-cn-south-1.qiniucs.com'
# 构建鉴权对象
q = Auth(access_key, secret_key, )
token = q.upload_token(bucket_name, file_name, 3600)
ret, info = put_file(token, file_name, file_path)
print(info)
#断言
assert ret['key'] == file_name
assert ret['hash'] == etag(file_path)
print('save qiniu ok.')
avatar_url = f'{bucket_domain}/{file_name}'
# 3.更新用户的avatar
user = User.objects.get(id=user_id)
# user = request.user # request 无法传 所以改为user_id
user.avatar = avatar_url
user.save()
return True
异步任务
Celery 及异步任务的处理
-
通用的异步框架的原理
-
核心队列:消息队列
-
客户端:异步端
-
生产者:消费者
-
发布者:订阅者
-
发送者:接收者
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YFOxnBJs-1577967577874)(/Users/zebin/Pictures/markdown_assets/image-20200102152154116.png)]
-
任务模块 Task:包含异步任务和定时任务. 其中, 异步任务通常在业务逻辑中被触发并发往任务队列, 而定时任务由 Celery Beat 进程周期性地将任务发往任务队列.
-
消息中间件 Broker:代理Broker, 即为任务调度队列, 接收任务生产者发来的消息(即任务)更重要的智能是把海量的的消息缓冲住, 将任务存入队列。Celery 本身不提供队列服务, 官方推荐使用 RabbitMQ 和 Redis 等,或者干脆用云服务的消息队列服务:SQS
-
任务执行单元 Worker:Worker 是执行任务的处理单元, 它实时监控消息队列, 获取队列中调度的任务, 并执行它.
-
任务结果存储 Backend:Backend 用于存储任务的执行结果, 以供查询. 同消息中间件一样, 存储也可使用 RabbitMQ, Redis 和 MongoDB 等.
-
-
消息队列:
- MQ:Message Queue,(与服务器、存储、缓存、数据库同等重要,是现代互联网后台架构的基础组件)
- 作用:
- 异步:把没必要同步执行的程序,用消息队列暂存,然后用其他程序去异步执行,做到跨机器分散任务
- 解耦:有依赖关系的应用之间,用消息队列解除耦合
- A 和 B 两个业务有强耦合
- A
B
- 削峰:把互联网的高峰请求,先缓冲下来,然后再慢慢的逐个处理
- 秒杀、团购的场景,用这种方式降低峰值请求
- 限流:
- 1000,每进来一个人 -1,每离开一个人 +1,
- 减到 0 ,就告诉后来者:人满了。
- 常见的消息队列:
- Redis,最简单
- Kafka,最适合做日志处理,单机几十万并发(每秒钟的请求)
- RabbitMQ,符合 MQ 标准的消息队列(每秒钟几万)
- RocketMQ,符合 MQ 标准的消息队列(每秒钟十几万)
-
安装 注意win10不支持celery4.3!!!!!!!!!!
所以需要额外安装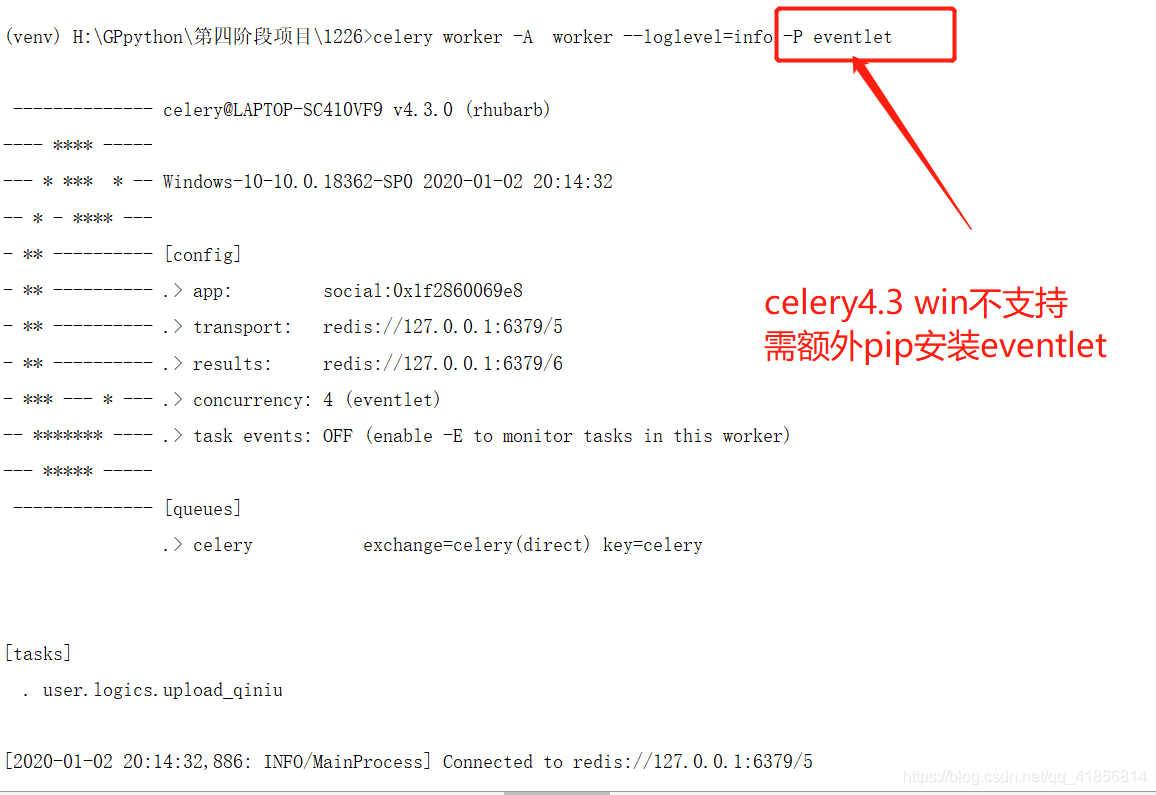
pip install celery[redis] -
创建实例
import os from celery import Celery from social import settings from worker import config os.environ.setdefault("DJANGO_SETTINGS_MODULE", "social.settings") celery_app = Celery('social') celery_app.config_from_object(config) celery_app.autodiscover_tasks() -
常规配置
broker_url = 'redis://127.0.0.1:6379/0' broker_pool_limit = 1000 # Borker 连接池, 默认是10 timezone = 'Asia/Shanghai' accept_content = ['pickle', 'json'] task_serializer = 'pickle' result_expires = 3600 # 任务过期时间 result_backend = 'redis://127.0.0.1:6379/1' result_serializer = 'pickle' result_cache_max = 10000 # 任务结果最大缓存数量 worker_redirect_stdouts_level = 'INFO' -
启动 Worker
Linux / mac下:
celery worker -A worker --loglevel=info
win:
celery worker -A worker --loglevel=info -P eventlet
