会议: 2019 interspeech
单位: ObEN公司
作者:Seyed Hamidreza Mohammadi, Taehwan Kim
demo: https://shamidreza.github.io/is19samples/
summary:听了一下,相似度一般,不像,可能是用WORLD vocoder,语音质量很差
但是可以学习结果分析和展示的方法
abstract
motivation: one-shot vc,只需要one or few target utterances, 完成any-to-any的vc
思路:用distangled representation of speaker identity and linguistic context,RNN encoder编码speaker embedding, ppgs表示文本编码,RNN decoder生成转换句子。
优点:模型简单,不需要对抗训练、hierarchical model,相似度超过baseline.
introduction
non-parallel的方法仍然需要说话人的信息作为先验知识。
【14】提出用FH-VAE引入解相关和可解释的特征,可以用一句话就实现转换,但是相似度并不让人满意。【15】基于这个结构做了cross-lingual的实验,模型学习将说话人信息和文本信息解相关,但是无监督学习下将这个两个特征解相关比较难,因为没有 inductive biases(归纳偏好,学习过程中的价值观,比如可以有多条曲线拟合一个点,但是什么样的标准选择哪一条更好,就是归纳偏好)。
因为,本文用PPGs代替文本信息,目的是学习speaker embedding,并且在和ppgs结合之后重建波形的时候降低loss。
Related Work
GAN网络训练的是src-tar pairs,即使有many-to-many的vc,但是target speaker必须是训练时候见过的。VAE用作vc的时候,speaker identity必须在训练时候见过,而不能直接infer。
DC-GAN,InfoGAN, 被他=VAE,FHVAE都提出利用latent code的解相关特征。计算机视觉和图像生成上也用到风格和内容的单独编码,vc可以沿用相似的思路,在target utt很少的情况下,用无监督的方法从数据中infer speaker identity(FHVAE提出的)。Siamese AE提出用平行数据学习解相关的说话人和文本特征,难点在于:假设hierarchical architecture, domain adversail train,但是相似度不够。
本文直接用PPGs表示说话人无关的文本信息,子网络单独提取说话人信息,结果表示更有效。
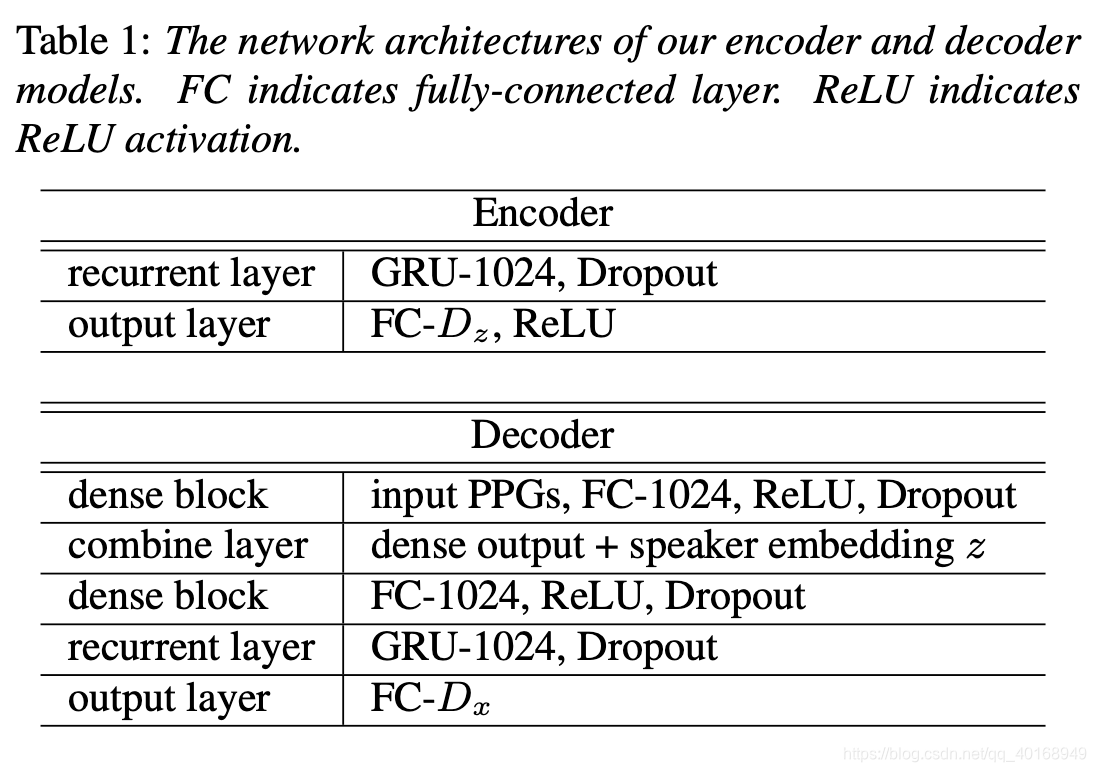
model
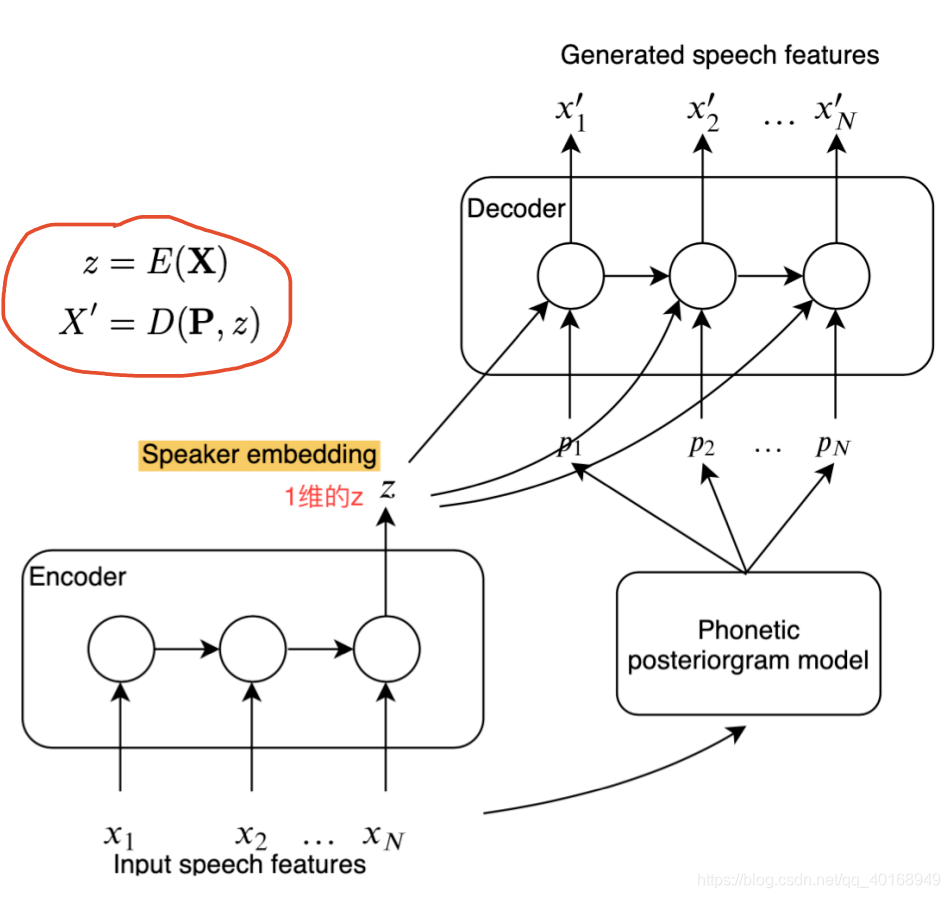
loss 函数
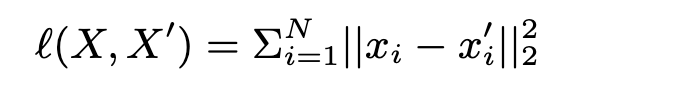
inference两种方法
(1)
直接取代
,但是结果不好,muffled speech(含糊)
(2)计算差距:source和target utt分别提取计算,取得性能的明显提升,分析是
可能不是完全解相关的。
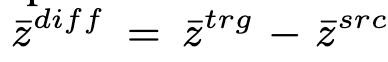
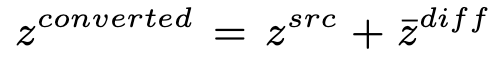
4. experiment
4.1 datasets
vc model: TIMIT(train&test),客观测试(需要平行数据)—CMU
ASR: librispeech, Kaldi ASR recipe
4.2 experiment setting
4.3. Visualizing embeddings
实验1: 比较proposed model和FHVAE的可视化结果
实验2: 比较
的区别
衡量标准
(1)男女分开,分界线更明显;(2)不同人间距比较—距离大,分布均衡(密集);
4.4. Effect of training data size
客观指标mel-CD[7],不同数目的句子提取的speaker embedding对性能的影响,结果表明,proposed model一致性的好于FHVAE。

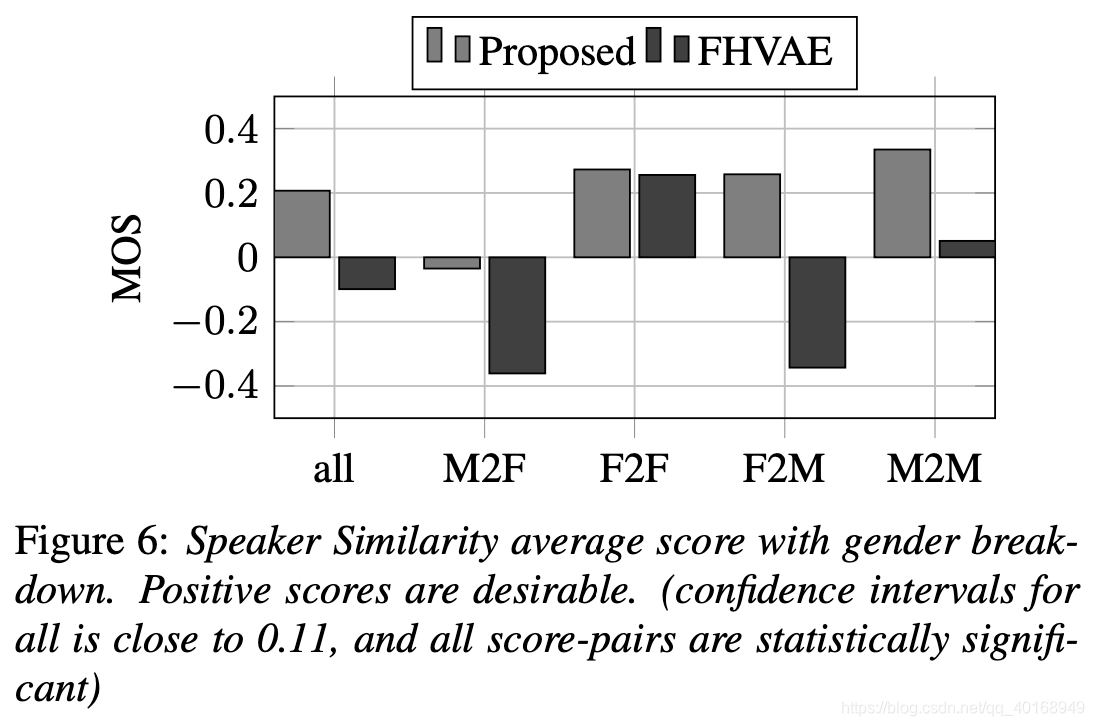
4.5 subjective test
在amazon平台上做的主观测试,
(1)语音质量—AB test;
(2)语音相似度,评分指标–+2 (definitely same), +1 (probably same), 0 (unsure), -1 (probably different), and -2 (definitely different)
最后对结果进行t-test分析,t-test介绍,直接比绝对性能。