Github项目地址:https://github.com/LeoCai/JobHarvester
相关文章:
JobHarvest——利用springAOP进行运行性能测评(更新中)
项目背景
就业季到了,现在的校招从7月份就差不多陆续开始了,但很多信息经常受限于地域,学校,很多学生会苦于找不到安全合理的渠道进行内推,网申等。现在比较靠谱的内推消息一般来自于各大名校的官方bbs,比如北邮人论坛。但是信息好乱,老是在bbs中看来看去,又很有可能遗漏掉信息。于是我决定做一个爬虫,专门自动收集各个论坛的就业信息。
摸索
从没写过爬虫,但对网页html有所了解,大概知道通过分析html结点得到自己所需的结点内容即可,先查阅资料怎么写爬虫的基本方法。开始简单地试着用urlconnetion,结果发现无法加载动态网页。然后查阅资料,发现很多人用webdriver,这个库本来是用来自动化测试的,它可以控制浏览器进行一些动作。现在基本的思路和工具有了,技术上是可行的,接下来就是设计。由于各大高校bbs的格式都是不同的,我们需要适配不同bbs,所以扩展性对系统非常重要。在设计的过程中,我发现尽管格式不同,很多步骤可以抽象出来,比如初始化浏览器,找到目标的列表,抽取目标信息,下一页等等。这种场景就非常适合模板模式。
版本1设计:
功能:
- 各大高校并行收集job信息
- 对job信息进行过滤(包括想要,不想要)
- 支持扩展爬虫,只需继承抽象类并实现少量函数(定位列表标签等)
- 利用类加载器加载配置文件中不同高校的爬虫。
- 抽取job信息中的格式,解析成统一的Bean
- 结果以简单地html页面展示。
目前涉及到的技术点:
- 主要包括利用spring解耦;
- mybatis处理数据库对象映射;
- 线程池并发收集;
- 类加载器动态加载爬虫。
系统架构设计:
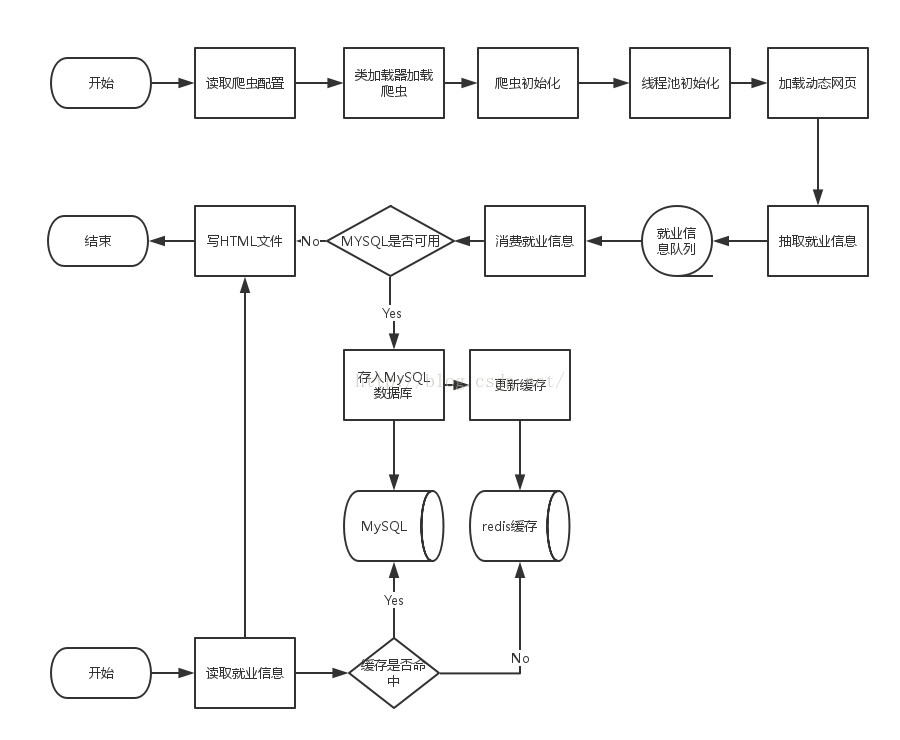
主要类设计:
程序入口两个:
- 一个是CrawlerWriter,用于爬虫和写数据库
- 一个是CrawlerRead,用于读取数据库和显示
还有几个重要的类介绍如下:
- CrawlerService:利用线程池并发收集不同高校的就业信息。
- MyCrawler:爬虫抽象类,模板模式,扩展爬虫必须继承的父类,包含了单爬虫爬取的算法
- JobInfoService:就业信息与数据库交互的服务
类图依赖关系如图所示:
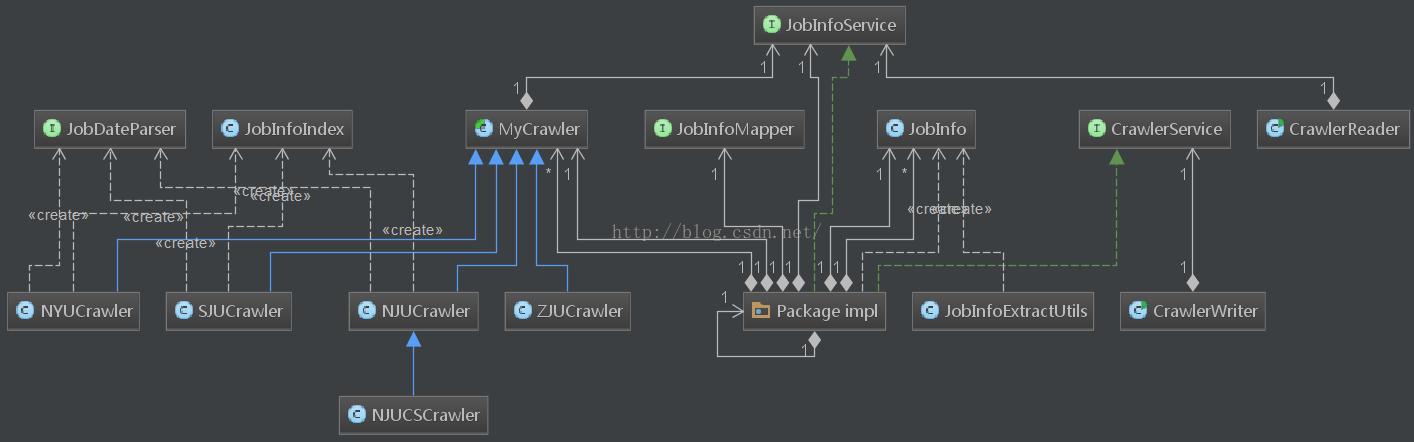
若要扩展爬虫只需三步:
- 只需继承MyCrawler
- 实现部分抽象方法,包括定位行,列,信息的索引,下一页等。
public class NYUCrawler extends MyCrawler { public NYUCrawler(String url) { super(url); setSource("南邮bbs"); } @Override protected JobInfo getInfoDTO(WebElement we) { JobInfoIndex jobInfoIndex = new JobInfoIndex(); jobInfoIndex.setHrefIdnex(1); jobInfoIndex.setTimeIndex(2); jobInfoIndex.setTitleIndex(1); jobInfoIndex.setHotIndex(4); JobDateParser jobDateParser = new JobDateParser() { public Date parse(String dateStr) { final SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); final SimpleDateFormat sdf2 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); Date date = new Date(); if (dateStr.contains("-")) { try { date = sdf.parse(dateStr); } catch (ParseException e) { e.printStackTrace(); } } else { try { date = sdf2.parse(JobDateUtils.getTodayDateStr() + " " + dateStr); } catch (ParseException e) { e.printStackTrace(); } } return date; } }; return JobInfoExtractUtils.simpleExtract(we, jobInfoIndex, jobDateParser); } protected List<WebElement> getCuCaoTarget() { return driver.findElements(By.tagName("tr")); } protected void nextPage() { WebElement el = driver.findElement(By.linkText(">>")); el.click(); } } - 在school.properties中配置对应的类名与网站的链接。
NJU = http://bbs.nju.edu.cn/board?board=JobExpress NJUCS = http://bbs.nju.edu.cn/board?board=D_Computer SJU = https://bbs.sjtu.edu.cn/bbsdoc?board=JobInfo NYU = http://bbs.cloud.icybee.cn/board/Job
无需显示调用,程序会利用类加载器加载配置文件中的爬虫类。
爬虫的抽象类如下:
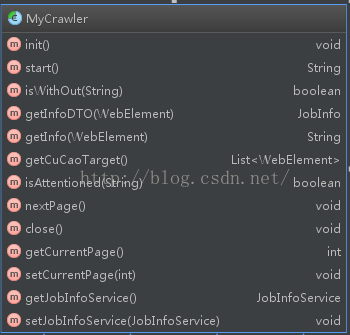
部分模块详解:
初始化:
只需在配置文件中配置类名和url,系统会利用
类加载器自动加载所有的爬虫类并放到一个
hashmap中。
/**
* 使用类加载器加载各个爬虫类
* 在school.properties中配置对于url
* 读取学校链接匹配地址,命名规范[School]+[Crawer]
*/
@PostConstruct public void init() {
Properties properties = new Properties();
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
try {
properties.load(classLoader.getResourceAsStream("school.properties"));
} catch (IOException e) {
e.printStackTrace();
}
Set<Object> keys = properties.keySet();
for (Object key : keys) {
try {
Class<MyCrawler> crawer = (Class<MyCrawler>) classLoader.loadClass(
"com.leocai.bbscraw.crawlers." + key + "Crawler");
MyCrawler c = crawer.getConstructor(String.class).newInstance(properties.getProperty((String) key));
c.setJobInfoService(jobInfoService);
map.put((String) key, c);
} catch (ClassNotFoundException e) {
logger.error(e.getMessage(), e);
} catch (InstantiationException e) {
logger.error(e.getMessage(), e);
} catch (IllegalAccessException e) {
logger.error(e.getMessage(), e);
} catch (NoSuchMethodException e) {
logger.error(e.getMessage(), e);
} catch (InvocationTargetException e) {
logger.error(e.getMessage(), e);
}
properties.get(key);
}
}单个爬虫算法初稿很简单如下,设计成一个模板模式:
红色均为抽象函数,不同的爬虫需要重写。
- 初始化:包括打开浏览器,禁用图片,css
- 进行连接
- 循环页数:
- 获得粗糙的目标(定位table)
- 定位行
- 过滤想要和不想要的信息
- 抽取jobinfo模型
- 下一页
/**
* 模板模式算法
* 粗糙定位目标位置:比如table
* 过滤想要和不想要的信息
* 定位行位置
* 抽取封装JobInfo信息
* 调用服务进行处理(此处可异步)
* 下一页
*
* @return
*/
public String start() {
init();
driver.get(url);
StringBuilder sb = new StringBuilder("");
for (int i = 0; i < pageNum; i++) {
List<WebElement> wes = getCuCaoTarget();
for (WebElement we : wes) {
String text = we.getText();
if (!AttentionUtils.isAttentioned(text) || AttentionUtils.isWithOut(text)) continue;
JobInfo infoDTO = getInfoDTO(we);
infoDTO.setSource(source);
jobInfoService.produceJobInfo(infoDTO);
}
nextPage();
}
return sb.toString();
}主函数
- 系统遍历爬虫map;
- 然后利用线程池提交任务;
- 利用future并行执行。
/**
* 利用线程池并行收集各个高校的信息
* 利用future进行收集
* 若未启用mysql,将得到的数据写入到html中
*/
public void asynStart() {
ExecutorService executorService = Executors.newFixedThreadPool(5);
Set<String> set = map.keySet();
List<Future<String>> fts = new ArrayList<Future<String>>(5);
for (final String key : set) {
Future<String> ft = executorService.submit(new Callable<String>() {
public String call() throws Exception {
String rs = map.get(key).start();
map.get(key).close();
return rs;
}
});
fts.add(ft);
}
for (Future<String> f : fts) {
try {
f.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
if (!isDBEnabled()) {
List<JobInfo> jobInfoList = jobInfoService.getJobInfosFromMemory();
HtmlUtils.writeHtml(jobInfoList, jobInfoService);
}
}版本一实现展示:

第二期需求:
- 支持断点爬虫(记录上次的位置),仅仅更新最新的信息(已完成)
- redis缓存(已完成)
- 已阅处理
相关文章:
JobHarvest——利用springAOP进行运行性能测评(更新中)
