此文翻译自:COROUTINES INTRODUCTION
在很长时间的争论,反对和准备后,WG21(ISO C++ Committee) 统一了在C++20中coroutines (协程)的具体实现。这是一个巨大的feature,我们需要提前学习。
有很多人反对这个特性,很多人抱怨协程很难懂以及性能可能不是最佳–动态内存分配没有优化(possibly ?)。
有些人甚至打算根据 TS (officially published Technical Specifications) 自己实现协程机制。我们这里讨论的协程是TS(技术规范)中的协程,是由微软提供的解决方案。
协程介绍
协程已经在很多语言中存在了,比如说Python和C#。协程提供了另一种创建异步代码的方法。我们会介绍协程与线程的区别,以及协程的优点。
协程有很多不同的叫法:
- stackless coroutines
- stackful coroutines
- green threads
- fibers
- goroutines
一般来说stackful coroutines, green threads, fibers, goroutines是同一个意思(有时有区别),我们称这些为 fibers 或者 stackful coroutines。但stackless coroutines有一些特殊,我们会重点讨论。
为了理解协程,我们先介绍一下函数。
void foo(){
return; //here we exit the function
}
foo(); //here we call/start the function
在我们调用函数之后,我们无法暂停或恢复它。我们可以执行的函数的唯一操作是start和finish。一旦功能启动,我们必须等到它完成。如果我们再次调用该函数,它将从头开始执行。
但对于协程来说不一样,你不仅可以启动和停止它,还可以暂停和恢复它。它仍然与内核的线程不同,因为协同程序本身并不是抢占式的(另一方面,协程通常属于线程,线程是抢占式的)。为了理解它,我们看一下python中定义的生成器。虽然Python叫它生成器,但在C ++中被称为coroutine。示例如下:
def generate_nums():
num = 0
while True:
yield num
num = num + 1
if num > 9:
break
nums = generate_nums()
for x in nums:
print(x)
这段代码的工作方式是调用 generate_nums 函数创建一个协程对象。每次在协程上迭代协程对象时,从上次暂停的地方继续运行, 当遇到yield 关键词 时再次暂停,并返回yield后的内容。当num大于9时,协程终止。这种协程可以是 started, suspended,resumed和最后 finished。
译者注:更多内容参考:Python yield 使用浅析
协程库
所以现在你对协程有了初步的了解,你知道有库可以创建协程。
问题是,为什么我们需要一个专用的语言功能而不仅仅是库。
我将试图回答这个问题,并向您展示stackful和stackless协同程序之间的区别。这个区别是理解协程语言功能的关键。
Stackful coroutines
首先让我们来谈谈什么是Stackful coroutines,它们如何工作,以及为什么它们可以作为库实现。它们可能更容易被解释,因为它们与线程构建很类似。
fibers 或者 stackful coroutines是一个单独的堆栈,可用于处理函数调用。要了解这种协程的工作原理,我们先简要了解函数框架和函数调用。但首先,让我们来看看fibers的特性。
- 他们有自己的堆栈
- fibers的生命周期与调用它的代码无关
- fibers可以从一个thread(线程)detach并attach到另一个thread上
- 协作调度
- 多个fibers不能在同一个线程上同时运行
上述属性的具体意思如下:
- fiber的上下文切换必须由fiber的user执行,而不是操作系统(操作系统仍然可以通过剥夺其运行的线程来处理光纤)
- 在同一线程上运行的两个fiber之间不会发生真正的数据争抢,因为只有一个可以处于活动状态
- fiber的开发人员必须知道它在一个适当的地方和时间将计算能力提供给可能的调度程序或被调用者。
- fiber中的I / O操作应该是异步的,以便其他fiber可以完成工作而不会相互阻塞
现在让我们解释一下fiber是如何工作的,从解释函数调用的stack开始。
栈(stack)是内存的连续块,需要存储局部变量和函数参数。但更重要的是,在每次函数调用(少数例外)之后,附加信息被放在堆栈上,让我们知道被调用函数如何返回被调用者并恢复处理器寄存器。
一些寄存器具有特殊用途,并在函数调用时保存在堆栈中。这些寄存器(在ARM架构的情况下)是:
- SP – stack pointer
- LR – link register
- PC – program counter
stack pointer指针保存堆栈的开始的地址,即属于当前函数调用的寄存器。通过这个值,很容易引用保存在堆栈中的参数和局部变量。
link register 在函数调用期间非常重要。它存储返回地址(被调用者的地址),其中存在当前函数执行结束后要执行的代码。调用函数时,PC将保存到LR。当函数返回时,使用LR恢复PC。
program counter–程序计数器是当前执行指令的地址。
每次调用函数时,都会保存链接寄存器,以便函数知道完成后返回的位置。
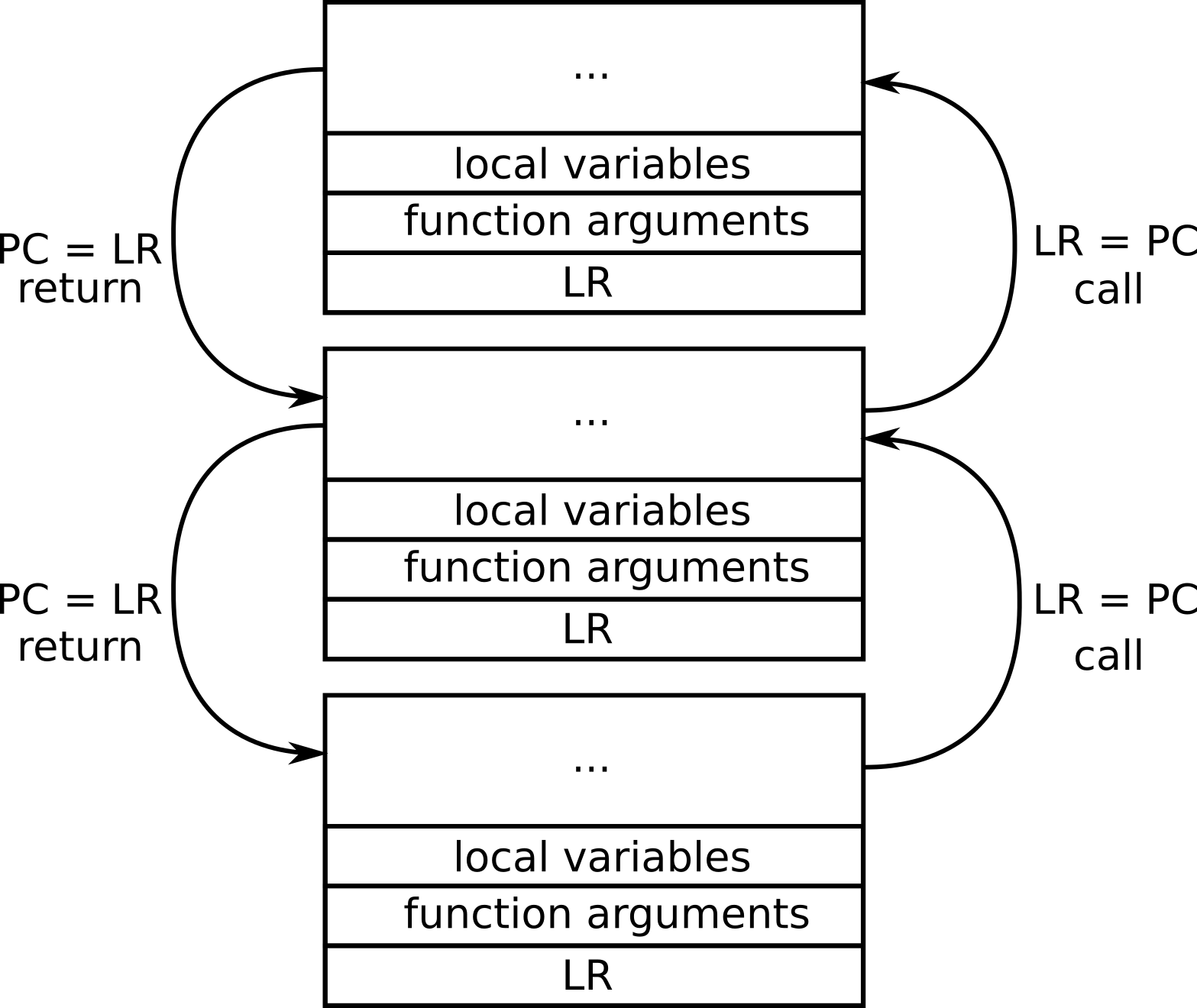
当调用stackful coroutines时,被调用的函数使用事先分配的堆栈来存储其参数和局部变量。因为所有信息都存储在堆栈中,用于在堆栈协程中调用的每个函数,所以fiber可能会暂停在协程中调用的任何函数中。
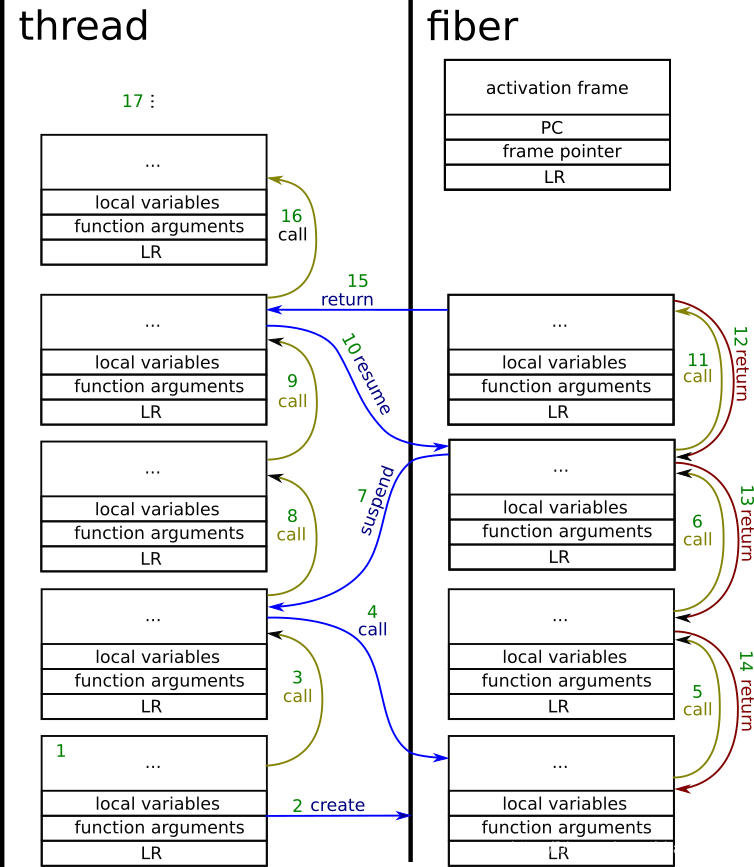
现在让我们看一下上图中的情况。首先,线程和fiber有自己独立的堆栈。下面对上图进行详细介绍。
1.线程内的常规函数调用。执行堆栈上的分配
2.该函数创建fiber对象,属于fiber的堆栈被分配。创建fiber并不一定意味着它会立即执行。此外,激活帧被分配。激活帧中的数据以这样的方式设置:将其内容保存到处理器的寄存器,从而使上下文切换到fiber堆栈。
3.常规函数调用。
4.协程调用。 处理器的寄存器设置为激活帧的内容。
5.协程内的常规函数调用。
6.协程内的常规函数调用。
7.协程暂停。更新激活帧内容并设置处理器的寄存器,以便上下文返回到线程的堆栈。
8.线程内的常规函数调用。
9.线程内的常规函数调用。
10.恢复协程 - 类似的事情发生在协同调用期间。激活帧记住协程内部处理器寄存器的状态,这是在协程挂起期间设置的。
11.协程内的常规函数调用。在协程栈中分配的功能帧。
12.对图像进行了一些简化。现在发生的事情是,协程结束并且所有堆栈都是未展开的。但是从协程的返回确实发生在底部(而不是顶部)功能。
13.常规函数返回。
14.常规功能返回。
15.协程回归。coroutine的堆栈是空的。上下文切换回线程。从现在开始,fiber无法恢复。
16.线程上下文中的常规函数调用。
稍后,函数可以继续操作或完成。
在stackful coroutines的情况下,不需要专用语言功能来使用它们。整个堆栈协程可以在库的帮助下实现,并且已经设计了用于执行此操作的库:
- https://swtch.com/libtask/
- https://code.google.com/archive/p/libconcurrency/
- https://www.boost.org Boost.Fiber
- https://www.boost.org Boost.Coroutine
上面提到的只有boost是C++的库,其他的都会C语言的库。
这些库都能够为fiber创建单独的堆栈,并且可以恢复(从调用者)和挂起(从内部)协程。
下面以Boost.Fiber为例:
#include <cstdlib>
#include <iostream>
#include <memory>
#include <string>
#include <thread>
#include <boost/intrusive_ptr.hpp>
#include <boost/fiber/all.hpp>
void fn( std::string const& str, int n) {
for ( int i = 0; i < n; ++i) {
std::cout << i << ": " << str << std::endl;
boost::this_fiber::yield();
}
}
int main() {
try {
boost::fibers::fiber f1( fn, "abc", 5);
std::cerr << "f1 : " << f1.get_id() << std::endl;
f1.join();
std::cout << "done." << std::endl;
return EXIT_SUCCESS;
} catch ( std::exception const& e) {
std::cerr << "exception: " << e.what() << std::endl;
} catch (...) {
std::cerr << "unhandled exception" << std::endl;
}
return EXIT_FAILURE;
}
Boost.Fiber库具有协程的内置调度程序。所有Fiber都在同一个线程中执行。由于协程调度是协作的,因此fiber需要决定何时将控制权交还给调度程序。在该示例中,它发生在对yield函数的调用上,该函数暂停协程。
由于没有其他fiber,fiber的调度程序总是决定恢复协程。
Stackless coroutines
Stackless coroutines跟Stackful coroutines有很多区别。
无堆栈协程仍然可以启动,并且在它们暂停之后它们可以恢复。
从现在开始我们将之称为协程。这是我们可能在C ++ 20中看到的协程类型。
协程特性:
- 协程与调用程序紧密相连 - 调用协同程序将执行程序转移到协程,并从协程返回到其调用程序。
- Stackful coroutines只要它们的堆栈就可以存活,但Stackless coroutines的生命周期与它们的对象存活时间一样。
Stackless coroutines不需要分配整个堆栈。它们的内存消耗要少得多,但由于这一点,它们有一些局限性。
首先,如果他们不为堆栈分配内存,那么它们如何工作?答案是:在调用者堆栈上。
Stackless coroutines 的秘密在于:它们只能从顶级函数中暂停。对于所有其他函数,它们的数据在被调用堆栈上分配,因此从协程调用的所有函数必须在挂起协程之前完成。协同程序需要保留其状态的所有数据都是在堆上动态分配的。这通常需要几个局部变量和参数,这些变量和参数的大小远小于事先分配的整个堆栈。
让我们来看看无堆协程如何工作:
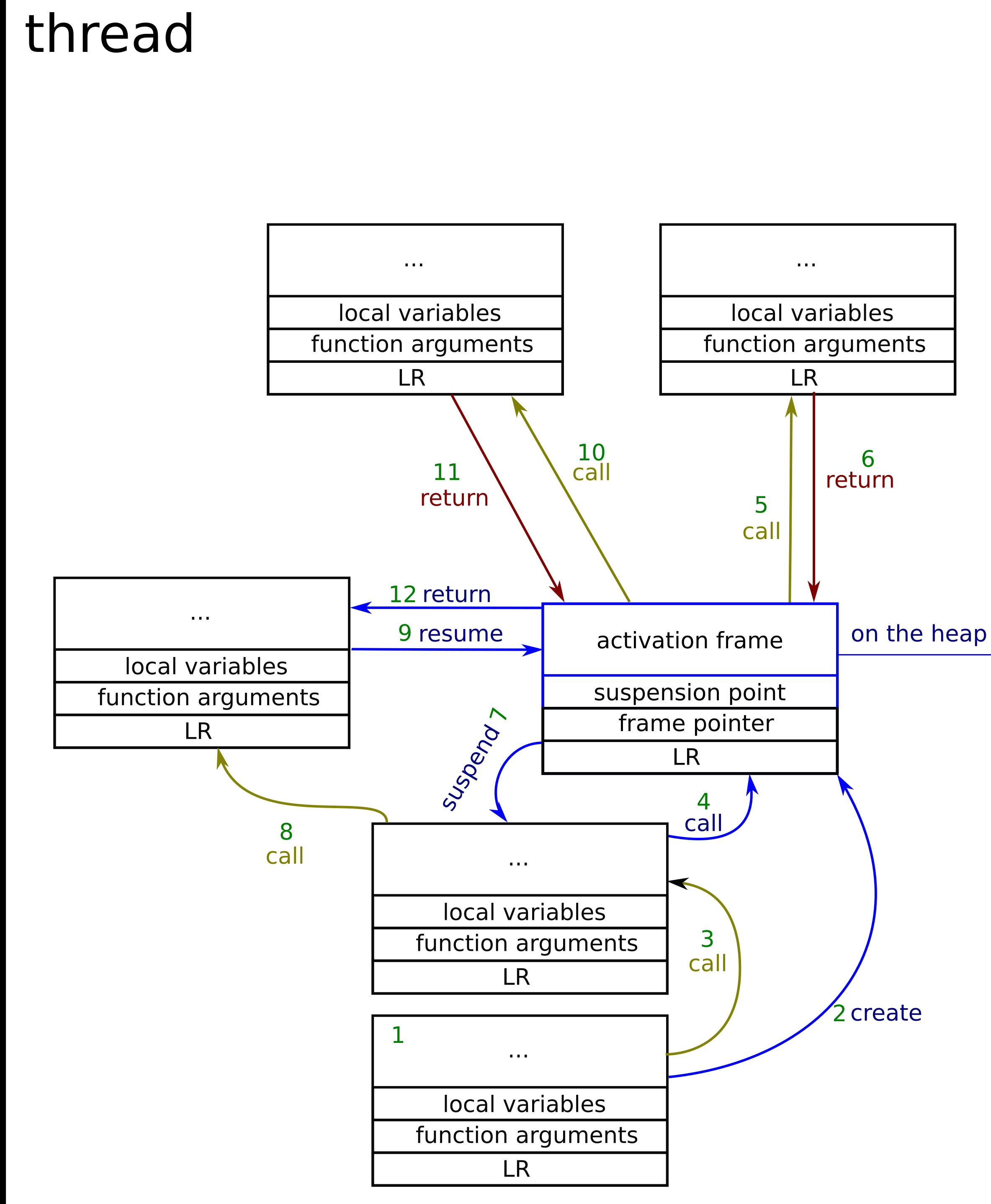
现在我们可以看到,只有一个堆栈 - 这是线程主堆栈。让我们一步一步地按照图片中的内容进行操作。(协同程序激活框架有两种颜色 - 黑色是存储在堆栈中的颜色,蓝色是存储在堆上的颜色)。
1.常规函数调用,函数帧存储在栈中。
2.该函数创建协程。这意味着在堆上的某处分配激活帧。
3.常规函数调用。
4.协程调用。 协程的主体分配在通常的栈上。程序流程与普通功能相同。
5.来自协程的常规函数调用。一切都还在栈上。[注意:从这一点开始,协程无法暂停,因为它不是协程的顶级功能)
6.函数返回到协同程序的顶级函数[注意协同程序现在可以暂停。]
7.协程暂停 - 在协同程序调用中需要保留的所有数据都放入激活框架中。
8.常规函数调用
9.Coroutine恢复 - 这发生在常规函数调用中,但跳转到前一个挂起点 + 从激活帧恢复变量状态。
10.函数调用。
11.函数返回。
12.协程回归。从现在开始无法恢复协同程序。
因此,我们可以看到,在协程挂起和恢复中需要记住的数据要少得多,但协程只能从顶层函数中暂停和返回。所有函数和协同调用都以相同的方式发生。在协同程序的情况下,需要在调用之间保留一些额外的数据以知道如何跳转到挂起点并恢复局部变量的状态。此外, function frame和 coroutine frame之间没有区别。
协程也可以调用其他协程(示例中未显示)。在无堆栈协程的情况下,每次调用将为协程数据分配新空间(对协同程序的多次调用可能导致多个动态内存分配)。
协同程序需要具有专用语言功能的原因是编译器需要决定哪些变量描述协同程序的状态并创建用于跳转到挂起点的样板代码。
Summary
阅读本文后我想让您知道的是:
- 为什么我们需要协程的专用语言功能
- Stackless coroutines跟Stackful coroutines之间的区别
- 为什么我们需要协程
我希望这篇文章可以帮助你理解这些主题。
