文章目录
什么是TensorRT
TensorRT™的核心是一个C ++库,可以提升NVIDIA图形处理单元(GPU)的高性能推断。它旨在与TensorFlow,Caffe,PyTorch,MXNet等深度学习框架以互补的方式工作。它专注于在GPU上快速有效地运行已经过训练的网络,以便生成结果(在各个地方称为评分,检测,回归或推理的过程)。
一些神经网络训练框架(如TensorFlow)已经集成了TensorRT,因此可用于加速框架内的推理过程。或者,TensorRT可以用作用户应用程序中的库。它包括用于从Caffe,ONNX或TensorFlow导入现有模型的解析器,以及用于以编程方式构建模型的C ++和Python API。
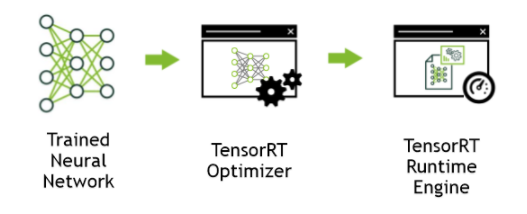
图-1TensorRT是一种用于生产部署的高性能神经网络推理优化器和运行时引擎
TensorRT通过组合层和优化内核选择来优化网络,从而改善延迟,吞吐量,功效和内存消耗。如果应用程序指定,它还将优化网络以更低的精度运行,进一步提高性能并降低内存需求。
下图显示了TensorRT被定义为高性能推理优化器和部件运行时引擎的一部分。它可以采用在一些流行框架上训练的神经网络,优化神经网络计算,生成轻量级运行时引擎(这是您需要部署到生产环境的唯一需要做的事),然后它将最大化这些GPU平台上的吞吐量,延迟和性能。
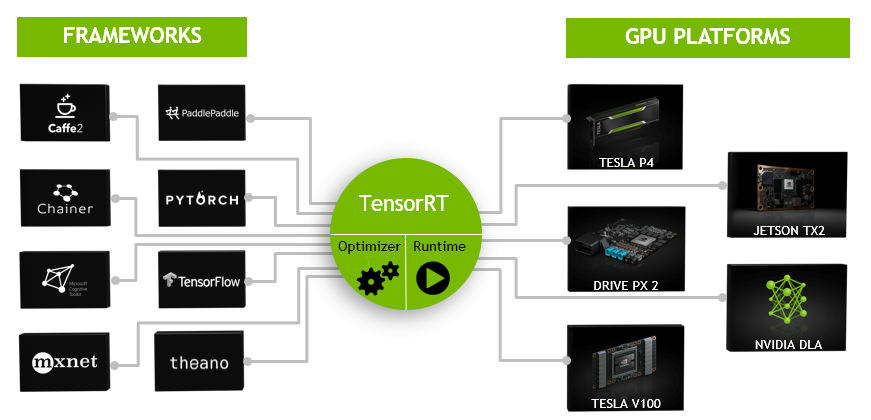
图-2 TensorRT是一种可编程推理加速器
TensorRT API包括最常见的深度学习层的实现。有关图层的更多信息,可以参见这里。您还可以使用C++插件API或Python插件API为TensorRT不支持的不常用或更具创新性的层提供实现。
TensorRT的优势
神经网络被训练好之后,TensorRT使网络能够被压缩、优化并作为运行时部署,而不需要框架的开销。TensorRT结合了多个层,优化内核选择,并根据指定的精度(FP32、FP16或INT8)执行规范化和转换,以优化矩阵数学,从而提高延迟、吞吐量和效率。
对于深度学习推理,有5个关键因素可以用来衡量软件:
- 吞吐量:在一定时期内的输出量。通常以inferences/second或samples/second来度量,每个服务器的吞吐量对于数据中心的成本效益扩展非常关键。
- 效能:单位功率的吞吐量,通常表示为性能/瓦特。效率是高效数据中心扩展的另一个关键因素,因为服务器、服务器机架和整个数据中心必须在固定的电力预算内运行。
- 延迟:执行推理的时间,通常以毫秒为单位。低延迟对于交付快速增长的实时基于推理的服务至关重要。
- 准确度:训练有素的神经网络提供正确答案的能力。对于基于图像分类的应用,关键指标表示为前5或前1个百分比。
- 内存使用量:在神经网络上进行推理需要保留的主机和设备内存取决于所使用的算法。这限制了在给定的推理平台上运行哪些网络以及网络的哪些组合。这对于需要多个网络且内存资源有限的系统尤其重要,如用于智能视频分析和多摄像头、多网络自主驾驶系统的级联多类检测网络。
使用TensorRT的替代方案包括:
- 使用训练框架本身执行推理。
- 编写一个定制应用程序,该应用程序专门用于使用低级库和数学操作执行网络。
使用训练框架来执行推断很简单,但是在给定的GPU上,使用类似于TensorRT这样的优化解决方案可能会导致更低的性能。训练框架倾向于实现更通用的代码,这些代码强调通用性,在进行优化时,优化的重点往往是有效的进行训练。
只需要编写一个定制的应用程序来执行一个神经网络,就可以获得更高的效率,但是它可能非常耗费人力,并且需要相当多的专业知识才能在现代GPU上达到高水平的性能。此外,在一个GPU上工作的优化可能不能完全转化为同一家族中的其他GPU,而且每一代GPU都可能引入只能通过编写新代码来利用的新功能。
TensorRT通过将API与特定硬件细节的高级抽象以及专门针对高吞吐量、低延迟和低设备内存占用推断而开发和优化的实现相结合来解决这些问题。
谁可以从TensorRT中受益
TensorRT适用于工程师,他们负责基于新的或现有的深度学习模型构建特性和应用程序,或者将模型部署到生产环境中。这些部署可以部署到数据中心或云中的服务器、嵌入式设备、机器人或车辆,或者运行在用户工作站上的应用程序软件中。
TensorRT已成功地在广泛的场景中使用,包括:
- **机器人:**公司销售的机器人使用TensorRT来运行各种计算机视觉模型,自动引导无人机系统在动态环境中飞行。
- **自动驾驶车辆:**TensorRT用于驱动应用了NVIDIA Drive的产品实现计算机视觉处理。
- **科学计算:**一个流行的技术计算包嵌入了TensorRT,以支持神经网络模型的高吞吐量执行。
- **深度学习训练和框架部署:**TensorRT包含在几个流行的深度学习框架中,包括TensorFlow和MXNet。有关TensorFlow和MXNet容器发布说明,请参见TensorFlow发布说明和MXNet发布说明。
- **视频分析:**TensorRT被用于英伟达的DeepStream产品中,为复杂的视频分析解决方案提供强大的支持,这些解决方案包括边缘的1 - 16个摄像头源,以及数据中心中可能聚集数百甚至数千个视频原的数据中心。
- **自动语音识别:**TensorRT用于小型桌面/桌面设备上的语音识别。该设备支持有限的词汇量,而云计算支持更大的词汇量语音识别系统。
TensorRT适用于哪里
一般来说,开发和部署深度学习模型的工作流经历三个阶段。
- 第一阶段:神经网络训练
- 第二阶段:开发部署解决方案
- 第三阶段:部署解决方案
第一阶段:训练
在培训阶段,数据科学家和开发人员将从他们想要解决的问题的陈述开始,并决定他们将使用的精确的输入、输出和损失函数。他们还将收集、整理、扩充训练、测试和验证数据集,并可能为这些数据集贴上标签。然后他们将设计网络的结构并训练模型。在训练过程中,他们会监控学习过程,这可能会提供反馈,导致他们修改损失函数,获取或增加培训数据。在这个过程的最后,他们将验证模型的性能并保存所训练的模型。训练和验证通常使用DGX-1™、Titan或Tesla数据中心gpu完成。TensorRT一般不用于训练阶段的任何部分。
第二阶段:开发部署解决方案
在第二阶段中,数据科学家和开发人员将从经过训练的模型开始,并使用这个经过训练的模型创建和验证部署解决方案。将这个阶段分解为几个步骤,就得到:
-
考虑一下神经网络在更大的系统中是如何工作的,它是这个系统的一部分,并设计和实现一个合适的解决方案。可能包含神经网络的系统是非常多样化的。例子包括
- 车辆的自动驾驶技术
- 公共场所或公司校园的视频安全系统
- 电子消费设备的语音接口
- 工业生产线自动化质量保证系统
- 提供产品推荐的在线零售系统
- … …
确定你的首要任务是什么。考虑到可以实现的不同系统的多样性,在设计和实现部署体系结构时可能需要考虑很多事情。
- 车辆的自动驾驶技术
- 您有单个网络还是多个网络?例如,您正在开发基于单个网络(人脸检测)的功能或系统吗?或者您的系统将由不同模型的混合或级联组成,或者 可能由一个更通用的工具来提供最终用户可能提供的集合模型?
- 您将使用什么设备或计算元素来运行网络?CPU, GPU,其他,还是混合?如果模型要在GPU上运行,它是单一类型的GPU,还是需要设计一个可以在多种GPU上运行的应用程序?
- 数据将如何到达模型?什么是数据管道?这些数据是来自摄像头或传感器、一系列文件,还是通过网络连接上传的?
- 将进行什么预处理?数据将采用什么格式?如果是图像,是否需要裁剪和旋转?如果是文本,那么它是什么字符集?是否允许所有字符作为模型的输入?有什么特别的token吗?
- 您将有什么延迟和吞吐量需求?
- 您能够将多个请求批处理在一起吗?
- 您是否需要单个网络的多个实例来实现所需的总体系统吞吐量和延迟?
- 您将如何处理网络的输出?
- 需要什么后处理步骤?
TensorRT提供了一个快速、模块化、紧凑、健壮、可靠的推理引擎,可以支持部署体系结构中的推理需求。
-
在数据科学家和开发人员定义了他们的推理解决方案的体系结构之后,他们确定了优先级,然后使用TensorRT从保存的网络构建一个推理引擎。根 据使用的训练框架和网络体系结构,有许多方法可以做到这一点。通常,这意味着您需要使用ONNX解析器(参见图3)、Caffe解析器或TensorFlow/UFF解析器将保存的神经网络从其保存的格式解析为TensorRT。
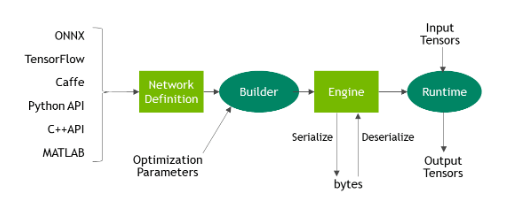
图-3 ONNX 工作流 V1
-
通过解析器对网络尽心解析之后,您需要考虑优化选项——批处理大小、工作区大小和混合精度。这些选项被选择并指定为TensorRT构建步骤的一部分,在此步骤中,您将根据您的网络实际构建一个优化的推理引擎。本指南的后续部分提供了关于工作流这一部分的详细说明和大量示例,将您的模型解析为TensorRT并选择优化参数(参见图4)。
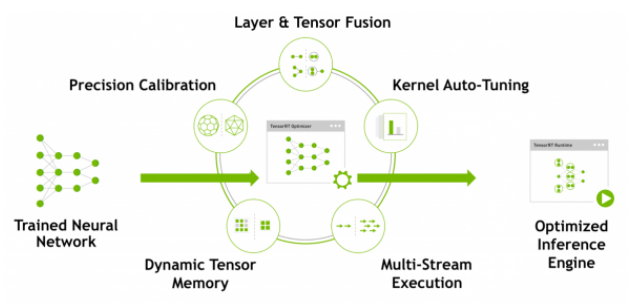
图-4TensorRT优化训练过的神经网络模型,以生成可部署的运行时推理引擎
-
在使用TensorRT创建了一个推理引擎之后,您将需要验证它是否复制了在训练过程中测量的模型结果。如果您选择了FP32或FP16,那么它应该与结果非常接近。如果你选择了INT8,那么在训练中获得的准确性和推理的准确性之间可能会有一个小的差距。
-
以串行格式写出推理引擎。这也称为计划文件。
第三阶段:部署解决方案
TensorRT库将链接到部署应用程序,部署应用程序将在需要推理结果时调用该库。要初始化推理引擎,应用程序首先将模型从计划文件反序列化为推理引擎。
TensorRT通常异步使用,因此,当输入数据到达时,程序调用一个enqueue函数,其中包含输入缓冲区和TensorRT应该将结果放入其中的缓冲区。
TensorRT如何工作
为了优化您的推理模型,TensorRT接受您的网络定义,执行优化,包括特定于平台的优化,并生成推理引擎。 这个过程称为构建阶段。构建阶段可能需要相当长的时间,特别是在嵌入式平台上运行时。因此,典型的应用程序将构建引擎一次,然后将其序列化为计划文件供以后使用。
**注意:**生成的计划文件不能跨平台或移植到其他TensorRT版本。 计划特定于它们构建的精确GPU模型(除了平台和TensorRT版本),并且必须重新定位到特定的GPU,以防您想要在不同的GPU上运行它们。
构建阶段在图层图上执行以下优化:
- 去除没有输出的层
- 融合卷积,bias和ReLU操作
- 具有足够相似的参数和相同的源张量的操作聚合(例如,GoogleNet v5初始模块中的1x1卷积)
- 通过将层输出定向到正确的最终目标来合并连接层。
如有必要,构建器还会修改权重的精度。 当以8位整数精度生成网络时,它使用称为校准的过程来确定中间激活的动态范围,并因此确定用于量化的适当缩放因子。
此外,构建阶段还在虚拟数据上运行图层以从其内核目录中选择最快的图像,并在适当的情况下执行权重预格式化和内存优化。
获取更多信息可以参考混合精度工作一节。
TensorRT提供何种能力
TensorRT使开发人员能够导入,校准,生成和部署优化过的网络。网络可以直接从Caffe导入,也可以通过UFF或ONNX格式从其他框架导入。还可以通过编程方式创建它们,方法是实例化各个层并直接设置参数和权重。
用户还可以使用插件接口通过TensorRT运行定制过的层。通过graphurgeon实用程序,可以将TensorFlow节点映射到TensorRT中的自定义层,从而可以使用TensorRT对许多TensorFlow网络进行推理。
TensorRT在所有支持的平台上提供c++实现,在x86上提供Python实现。
TensorRT核心库的关键接口为:
网络定义
网络定义接口为应用程序提供了指定网络定义的方法。可以指定输入和输出张量,可以添加层,并且有一个接口用于配置每个受支持的层类型。除了支持卷积层、循环层之外,Tensor还可以通过安装插件的方式扩展其本身不支持的类型。有关网络定义的详细信息,请参阅网络定义API。
构建器
构建器接口允许通过网络定义创建优化过的引擎。它允许应用程序指定最大批量和工作空间大小,最小可接受精度水平,自动调整的计时迭代计数,以及用于量化网络以8位精度运行的接口。 有关Builder的更多信息,请参阅Builder API。
引擎
Engine接口允许应用程序执行推理。 它支持同步和异步执行,分析,枚举和查询引擎输入和输出的绑定。 单个引擎可以具有多个执行上下文,允许使用单组训练参数来同时执行多个批次。 有关Engine的更多信息,请参阅Execution API。
TensorRT提供解析器,用于导入经过训练的网络以创建网络定义,TensorRT支持的解析器包括:
- Caffe Parser:
此解析器可用于解析在BVLC Caffe或NVCaffe 0.16中创建的Caffe网络。 它还提供了为自定义图层注册插件工厂的功能。有关c++ Caffe解析器的详细信息,请参阅 NvCaffe Parser 或Python Caffe Parser。
-
UFF Parser:
此解析器可用于以UFF格式解析网络。 它还提供了注册插件工厂和传递自定义图层的字段属性的功能。 有关C ++ UFF Parser的更多详细信息,请参阅NvUffParser或Python UFF Parser。 -
ONNX Parser:
此解析器可用于解析ONNX模型。 有关C ++ ONNX Parser的更多详细信息,请参阅NvONNXParser或Python ONNX Parser。
限制
由于ONNX格式正在快速开发,因此您可能会遇到模型版本和解析器版本之间的版本不匹配。 TensorRT 5.0.0附带的ONNX Parser支持ONNX IR(中间表示)版本0.0.3,opset版本7。
哪里可以获得TensorRT
有关如何安装TensorRT的详细说明,可以参考TensorRT Installation Guide.
使用c++ API处理TensorRT
使用c++ API处理TensorRT”.以下部分突出显示了可以使用c++ API执行的TensorRT用户目标和任务。示例部分提供了进一步的详细信息,并在适当时链接到下面。
假设您从一个经过训练的模型开始。本章将介绍使用TensorRT时的必要步骤:
- 从模型创建TensorRT网络定义
- 调用TensorRT构建器从网络创建优化过的运行时引擎
- 序列化和反序列化引擎,以便在运行时快速重新创建引擎
- 为引擎提供数据以执行推理。
在本质上,c++ API和Python API在支持您的需求方面应该非常接近。 C++ API应该用于任何性能关键场景,以及安全性非常重要的情况,例如在汽车中。
Python API的主要好处是数据预处理和后处理很容易使用,因为您可以使用各种库,比如NumPy和SciPy。有关Python API的更多信息,请参见使用Python API一节。
实例化TensorRT
实例化TensorRT”.为了运行推理,您需要使用IExecutionContext对象。为了创建类型为IExecutionContext的对象,首先需要创建类型为的对象
ICudaEngine(引擎)。
引擎可以通过以下两种方式创建:
- 通过来自于用户模型的网络定义。在这种情况下,可以选择序列化引擎并保存起来供以后使用。
- 通过从磁盘读取序列化引擎。在这种情况下,性能更好,因为解析模型和创建中间对象的步骤被省略了。
需要全局创建iLogger类型的对象。它被用作TensorRT API的各种方法的参数。下面是一个演示如何创建日志程序的简单示例:
class Logger : public ILogger
{
void log(Severity severity, const char* msg) override
{
// suppress info-level messages
if (severity != Severity::kINFO)
std::cout << msg << std::endl;
}
} gLogger;
名为createInferBuilder(gLogger)的全局TensorRT API方法用于创建iBuilder类型的对象,如图5所示。有关更多信息,请参阅IBuilder类引用。

图-5 使用iLogger作为输入参数创建iBuilder
为iBuilder定义的名为createNetwork的方法用于创建iNetworkDefinition类型的对象,如图6所示。

图-6 createNetwork()用于创建网络。
使用iNetwork定义作为输入创建一个可用的解析器:
- ONNX:parser = nvonnxparser::createParser(*network, gLogger);
- NVCaffe:ICaffeParser* parser = createCaffeParser();
- UFF:parser = createUffParser();
调用来自iParser类型的对象的名为parse()的方法来读取模型文件并填充TensorRT网络。

图-7 解析模型文件。
调用iBuilder的一个名为buildCudaEngine()的方法来创建一个iCudaEngine类型的对象,如图8所示:

图-8 创建TensorRT引擎。
可以选择将引擎序列化并转储到文件中。

图-9 序列化TensorRT引擎。
执行上下文用于执行推理。

图-10 创建执行上下文。
如果引擎已经序列化被保留并保存到文件中,则可以绕过上述大多数步骤。
名为createInferRuntime(gLogger)的全局TensorRT API方法用于创建iRuntime类型的对象,如图11所示:

图-11 创建TensorRT运行时。
有关TensorRT运行时的更多信息,请参阅IRuntime类引用。 通过调用运行时方法deserializeCudaEngine()来创建引擎。
对于这两种使用模型,其余推断是相同的。
尽管可以避免创建CUDA上下文(将为您创建默认上下文),但这是不可取的。 建议在创建运行时或构建器对象之前创建和配置CUDA上下文。
将使用与创建线程关联的GPU上下文创建构建器或运行时。 虽然如果缺省上下文尚不存在,但会创建它,但建议在创建运行时或构建器对象之前创建和配置CUDA上下文。
创建网络定义
使用TensorRT进行推理的第一步是从您的模型创建TensorRT网络。 实现此目的的最简单方法是使用TensorRT解析器库导入模型,该解析器库支持以下格式的序列化模型:
另一种方法是使用TensorRT API直接定义模型。 这要求您进行少量API调用以定义网络图中的每个层,并为模型的训练参数实现自己的导入机制。
在任何一种情况下,您都明确需要告诉TensorRT需要哪些张量作为推理的输出。 未标记为输出的张量被认为是可由建造者优化的瞬态值。 输出张量的数量没有限制,但是,将张量标记为输出可能会禁止对张量进行一些优化。 输入和输出张量也必须给出名称(使用ITensor :: setName())。 在推理时,您将为引擎提供一个指向输入和输出缓冲区的指针数组。 为了确定引擎对这些指针的预期顺序,您可以使用张量名称进行查询。
TensorRT网络定义的一个重要方面是它包含指向模型权重的指针,这些指针由构建器复制到优化引擎中。 如果网络是通过解析器创建的,则解析器将拥有权重占用的内存,因此在构建器运行之前,不应删除解析器对象。
使用C ++ API从头开始创建网络定义
您也可以通过网络定义API直接将网络定义到TensorRT,而不是使用解析器。 此方案假定在网络创建期间,每层权重已准备好在主机内存中传递给TensorRT。
在下面的示例中,我们将创建一个包含Input,Convolution,Pooling,FullyConnected,Activation和SoftMax图层的简单网络。要查看整体代码,请参阅位于/usr/src/tensorrt/samples/sampleMNISTAPI目录。
-
创建Builder和network
IBuilder* builder = createInferBuilder(gLogger); INetworkDefinition* network = builder->createNetwork(); -
使用输入维将“输入”层添加到网络。 网络可以有多个输入,但在此示例中只有一个:
auto data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{1, INPUT_H, INPUT_W}); -
添加具有隐藏层输入节点的Convolution图层,过滤器和偏差的步幅和权重。 为了从图层中检索张量参考,我们可以使用:
auto conv1 = network->addConvolution(*data->getOutput(0), 20, DimsHW{5, 5}, weightMap["conv1filter"], weightMap["conv1bias"]); conv1->setStride(DimsHW{1, 1});**Note:**传递给TensorRT图层的权重在主机内存中。
-
添加Pooling层:
auto pool1 = network->addPooling(*conv1->getOutput(0), PoolingType::kMAX, DimsHW{2, 2}); pool1->setStride(DimsHW{2, 2}); -
添加FullyConnected和Activation图层:
auto ip1 = network->addFullyConnected(*pool1->getOutput(0), 500, weightMap["ip1filter"], weightMap["ip1bias"]); auto relu1 = network->addActivation(*ip1->getOutput(0), ActivationType::kRELU); -
添加SoftMax图层以计算最终概率并将其设置为输出:
auto prob = network->addSoftMax(*relu1->getOutput(0)); prob->getOutput(0)->setName(OUTPUT_BLOB_NAME); -
标记输出:
network->markOutput(*prob->getOutput(0));
使用解析器导入模型
要使用C ++ Parser API导入模型,您需要执行以下高级步骤:
-
创建TensorRT构建器和网络。
IBuilder* builder = createInferBuilder(gLogger); nvinfer1::INetworkDefinition* network = builder->createNetwork();有关如何创建记录器的示例,参见实例化TensorRT。
-
为特定格式创建TensorRT解析器。
ONNX
auto parser = nvonnxparser::createParser(*network, gLogger);UFF
auto parser = createUffParser();NVCaffe
ICaffeParser* parser = createCaffeParser(); -
使用解析器解析导入的模型并填充网络。
parser->parse(args); 具体的args取决于使用什么格式的解析器。 有关更多信息,请参阅[TensorRT API](https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/index.html)中记录的解析器。
必须在网络之前创建构建器,因为它充当网络的工厂。 不同的解析器具有用于标记网络输出的不同机制。
使用C ++ Parser API导入Caffe模型
以下步骤说明了如何使用C ++ Parser API导入Caffe模型。欲获得更多信息,参见。
-
创建builder和network
IBuilder* builder = createInferBuilder(gLogger); INetworkDefinition* network = builder->createNetwork(); -
创建Caffe parser:
ICaffeParser* parser = createCaffeParser(); -
解析导入的模型:
const IBlobNameToTensor* blobNameToTensor = parser->parse("deploy_file" , "modelFile", *network, DataType::kFLOAT); 这将填充Caffe模型中的TensorRT网络。 最后一个参数指示解析器生成权重为32位浮点数的网络。 使用DataType :: kHALF将生成具有16位权重的模型。 除了填充网络定义之外,解析器还返回一个字典,该字典从Caffe blob名称映射到TensorRT张量。 与Caffe不同,TensorRT网络定义没有就地操作的概念。 当Caffe模型使用就地操作时,字典中返回的TensorRT张量对应于对该blob的最后一次写入。 例如,如果卷积写入blob并且后跟就地ReLU,则该blob的名称将映射到TensorRT张量,该张量是ReLU的输出。 -
指定网络的输出:
for (auto& s : outputs) network->markOutput(*blobNameToTensor->find(s.c_str()));
使用C ++ UFF Parser API导入TensorFlow模型
**NOTE:**对于新项目,建议使用TensorFlow-TensorRT集成作为转换TensorFlow网络以使用TensorRT进行推理的方法。
有关集成说明,请参阅Integrating TensorFlow With TensorRT与 Release Notes。
从TensorFlow框架导入需要您将TensorFlow模型转换为中间格式UFF(通用框架格式)。有关转换的更多信息,Converting A Frozen Graph To UFF。
以下步骤说明了如何使用C ++ Parser API导入TensorFlow模型。有关UFF导入的更多信息,参见。
-
创建builder和network:
IBuilder* builder = createInferBuilder(gLogger); INetworkDefinition* network = builder->createNetwork(); -
创建UFF parser:
IUFFParser* parser = createUffParser(); -
向UFF解析器声明网络输入和输出:
parser->registerInput("Input_0", DimsCHW(1, 28, 28), UffInputOrder::kNCHW); parser->registerOutput("Binary_3"); **NOTE:**TensorRT期望输入张量为CHW顺序。 从TensorFlow导入时,请确保输入张量符合所需顺序,如果不是,请将其转换为CHW。 -
解析导入的模型以填充网络:
parser->parse(uffFile, *network, nvinfer1::DataType::kFLOAT);
使用C ++ Parser API导入ONNX模型
构建引擎
下一步是调用TensorRT构建器来创建优化的运行时。 构建器的一个功能是搜索其CUDA内核目录以获得最快的可用实现,因此必须使用相同的GPU来构建优化引擎将运行的GPU。
构建器具有许多属性,您可以设置这些属性以控制网络应运行的精度,以及自动调整参数,例如TensorRT在确定哪个最快时(多次迭代导致更长的运行时间)应该为每个内核计时多少次 但是对噪声的敏感性较低。)您还可以查询构建器以找出硬件本身支持的精简类型。
两个特别重要的属性是最大批量大小和最大工作空间大小。
-
最大批量大小指定TensorRT将优化的批量大小。 在运行时,可以选择较小的批量大小。
-
层算法通常需要临时工作空间。 此参数限制网络中任何层可以使用的最大大小。 如果提供的***insufficient scratch***,则TensorRT可 能无法找到给定层的实现。
-
使用构建器对象构建引擎:
builder->setMaxBatchSize(maxBatchSize); builder->setMaxWorkspaceSize(1 << 20); ICudaEngine* engine = builder->buildCudaEngine(*network);在构建引擎时,TensorRT会复制权重。
-
销毁network、builder、parser
parser->destroy(); network->destroy(); builder->destroy();
序列化模型
要进行序列化,您要将引擎转换为一种格式,以便以后存储和使用以进行推理。 要用于推理,您只需反序列化引擎即可。 序列化和反序列化是可选的。 由于从网络定义创建引擎可能非常耗时,因此每次应用程序重新运行时都可以通过序列化一次并在推理时对其进行反序列化来避免重建引擎。 因此,在构建引擎之后,用户通常希望将其序列化以供以后使用。
构建可能需要一些时间,因此一旦构建了引擎,您通常需要将其序列化以供以后使用。 在将模型用于推理之前,并非绝对有必要对模型进行序列化和反序列化 - 如果需要,可以直接使用引擎对象进行推理。
**NOTE:**序列化引擎不能跨平台或TensorRT版本移植。 引擎特定于它们构建的精确GPU模型(除了平台和TensorRT版本)。
-
将构建器作为先前的脱机步骤运行,然后序列化:
IHostMemory *serializedModel = engine->serialize(); // store model to disk // <…> serializedModel->destroy(); -
创建要反序列化的运行时对象:
IRuntime* runtime = createInferRuntime(gLogger); ICudaEngine* engine = runtime->deserializeCudaEngine(modelData, modelSize, nullptr);
最后一个参数是使用自定义图层的应用程序的插件层工厂。欲获得更多信息,参见Extending TensorRT With Custom Layers。
执行推理
以下步骤说明了如何使用引擎在C++中执行推理。
-
创建一些空间来存储中间激活值。 由于引擎保持网络定义和训练的参数,因此需要额外的空间。 这些都保存在执行上下文中。
IExecutionContext *context = engine->createExecutionContext();引擎可以具有多个执行上下文,允许一组权重用于多个重叠推理任务。 例如,你可以在并行CUDA流处理中使用一个引擎配合一个上下文的方式来处理图像。 每个上下文将在与引擎相同的GPU上创建。
-
使用输入和输出blob名称来获取相应的输入和输出索引:
int inputIndex = engine.getBindingIndex(INPUT_BLOB_NAME); int outputIndex = engine.getBindingIndex(OUTPUT_BLOB_NAME); -
使用这些索引,设置指向GPU上输入和输出缓冲区的缓冲区数组:
void* buffers[2]; buffers[inputIndex] = inputbuffer; buffers[outputIndex] = outputBuffer; -
TensorRT执行通常是异步的,因此将内核排入CUDA流:
context.enqueue(batchSize, buffers, stream, nullptr);
通常在内核之前和之后将异步memcpy()排入队列以从GPU移动数据(如果尚未存在)。 enqueue()的最后一个参数是一个可选的CUDA事件,当输入缓冲区被消耗并且它们的内存可以安全地重用时,它将被发出信号。
要确定内核(以及可能的memcpy())何时完成,请使用标准CUDA同步机制(如事件)或等待流。
内存管理
TensorRT提供了两种机制,允许应用程序更好地控制设备内存。
默认情况下,在创建IExecutionContext时,会分配持久设备内存来保存激活数据。 要避免此分配,请调用
createExecutionContextWithoutDeviceMemory。 然后应用程序负责调用IExecutionContext :: setDeviceMemory()来提供运行网
络所需的内存。 内存块的大小由ICudaEngine :: getDeviceMemorySize()返回。
此外,应用程序可以通过实现IGpuAllocator接口提供在构建和运行时使用的自定义分配器。 实现接口后,调用setGpuAllocator(&allocator);
在IBuilder或IRuntime接口上。 然后,将通过此接口分配和释放所有设备内存。
改进引擎
TensorRT可以使用新的权重改进引擎,而无需重建。 引擎必须构造为“可重新改进”。 由于引擎的优化方式,如果您更改一些权重,您可能还需要提供一些其他权重。 接口可以告诉您需要提供哪些额外的权重。
-
在构建之前请求可重新改进的引擎:
... builder->setRefittable(true); builder->buildCudaEngine(network); -
创建一个refitter对象:
ICudaEngine* engine = ...; IRefitter* refitter = createInferRefitter(*engine,gLogger) -
更新要更新的权重。 例如,要更新名为“MyLayer”的卷积层的内核权重:
Weights newWeights = ...; refitter.setWeights("MyLayer",WeightsRole::kKERNEL,newWeights);新的权重应与用于构建引擎的原始权重具有相同的计数。
如果出现问题,setWeights返回false,例如错误的图层名称或角色,或者权重计数的变化。 -
找出必须提供的其他权重。 这通常需要两次调用IRefitter :: getMissing,首先获取必须提供的Weights对象的数量,然后获取他们的图层和角色。
const int n = refitter->getMissing(0, nullptr, nullptr); std::vector<const char*> layerNames(n); std::vector<WeightsRole> weightsRoles(n); refitter->getMissing(n, layerNames.data(), weightsRoles.data()); -
以任何顺序提供缺失的权重:
for (int i = 0; i < n; ++i) refitter->setWeights(layerNames[i], weightsRoles[i], Weights{...});仅提供缺失的权重将不再需要任何权重。 提供任何额外的权重可能会触发更多权重的需要。
-
使用提供的所有权重更新引擎:
bool success = refitter->refitCudaEngine(); assert(success);如果success为假,请检查日志以查找诊断,可能还有仍然缺失的权重。
-
销毁refitter结构
refitter->destroy();
更新的引擎行为是否是从使用新权重更新的网络构建的。要查看引擎中所有可重新调整的权重,请使用refitter-> getAll(…); 类似于步骤3中如何使用getMissing。
使用Python API
混合精度工作”.使用自定义层扩展TensorRT
混合精度工作
混合精度工作”.混合精度是在计算方法中组合使用不同的数值精度。 TensorRT可以存储权重和激活,并以32位浮点,16位浮点或量化的8位整数执行层。
使用低于FP32的精度可以减少内存使用,允许部署更大的网络。 数据传输花费的时间更少,计算性能也会提高,尤其是在Tensor Core支持该精度的GPU上。
默认情况下,TensorRT使用FP32推理,但它也支持FP16和INT8。 在运行FP16推理时,它会自动将FP32权重转换为FP16权重。
您可以使用以下API检查平台上支持的精度:
if (builder->platformHasFastFp16()) { … };
if (builder->platformHasFastInt8()) { … };
指定网络的精度定义了应用程序的最低可接受精度。 如果对于某些特定的内核参数集更快,或者如果不存在低精度内核,则可以选择更高精度的内核。 您可以设置构建器标志setStrictTypeConstraints以强制网络或层精度,这可能没有最佳性能。 仅建议在调试时使用此标志。
如果平台支持,您也可以选择设置INT8和FP16模式。 TensorRT将选择性能最佳的内核来执行推理。
NOTE:Jetson TX2仅支持FP32和FP16.
DLA
NVIDIA DLA(深度学习加速器)是一款针对深度学习操作的固定功能加速器引擎。 DLA旨在对卷积神经网络进行全硬件加速。 DLA支持各种层,如卷积,反卷积,完全连接,激活,池化,批量标准化等。
NOTE:Jetson TX2不支持DLA.
部署一个TensorRT优化模型
在创建包含优化推理模型的计划文件后,可以将该文件部署到生产环境中。 如何创建和部署计划文件取决于您的环境。 例如,您可能为模型提供了一个专用推理可执行文件,用于加载计划文件,然后使用TensorRT执行API将输入传递给模型,执行模型以执行推理,最后从模型中读取输出。
本节讨论如何在一些常见的部署环境中部署TensorRT。
云端部署
用于推理的一种常见云部署策略是通过为模型实现HTTP REST或gRPC端点的服务器公开模型。 然后,远程客户端可以通过向该端点发送格式正确的请求来执行推理。 请求将选择模型,提供模型所需的必要输入张量值,并指出应计算哪些模型输出。
要在此部署策略中利用TensorRT优化模型,不需要进行任何根本性更改。 必须更新推理服务器以接受由TensorRT计划文件表示的模型,并且必须使用TensorRT执行API来加载和执行这些计划。 可以在TensorRT推理服务器容器发行说明和TensorRT推理服务器指南中找到为推理提供REST终结点的推理服务器示例。
嵌入式系统部署
TensorRT还可用于将经过训练的网络部署到嵌入式系统,如NVIDIA Drive PX。 在此上下文中,部署意味着获取网络并在嵌入式设备上运行的软件应用程序中使用它,例如对象检测或映射服务。 将经过训练的网络部署到嵌入式系统涉及以下步骤:
-
将训练好的网络导出为UFF或ONNX等可导入TensorRT的格式(参见,使用深度学习框架)
-
编写一个程序,使用TensorRT C ++ API将训练好的网络导入,优化和序列化为计划文件(参见前面对应的章节)
-
在部署到目标系统之前,在主机系统上构建并运行make_plan以验证训练的模型.(能不能直接在目标系统上验证?)
-
将训练有素的网络(和INT8校准缓存,如果适用)复制到目标系统。在目标系统上重新构建并重新运行make_plan程序以生成计划文件。
**NOTE:**make_plan程序必须在目标系统上运行,才能为该系统正确优化TensorRT引擎。但是,如果在主机上生成了INT8校准高速缓存,则在生成引擎时,构建器可以在目标上重新使用高速缓存(换句话说,不需要在目标系统本身上进行INT8校准)。
在嵌入式系统上创建计划文件后,嵌入式应用程序可以从计划文件创建引擎,并使用TensorRT C++ API对引擎执行推理。更多信息可以参考,使用c++ API处理TensorRT
介绍在嵌入式系统上部署TensorRT引擎的典型用例可以参考:
使用深度学习框架
使用深度学习框架”.使用Python API,使用TensorFlow,Caffe或ONNX兼容框架构建的现有模型可用于使用提供的解析器构建TensorRT引擎。 Python API还支持以NumPy兼容格式存储图层权重的框架,例如PyTorch。
使用TensorFlow
示例
示例.FAQ
BatchSize是什么?
出现在builder->setMaxBatchSize(maxBatchSize)、context.enqueue(batchSize, buffers, stream, nullptr)中的batchsize是什么意思?
