文章目录
- 官方collection教程
- 所有collection扩展自Iterable特质
- 三大类,序列,集合,映射 seq set map
- 对于几乎所有的collection,都提供了可变和不可变的版本
- 列表要么是空的,要么是一头一尾,尾是列表
- 集合没有先后次序
- + 将元素添加到无先后次序的容器中,+: 和 :+向前或向后追加到序列,++将两个集合串接到一起,-和–移除元素(1个减号和两个减号)
- Iterable和Seq特质有数十个常见操作方法,很丰富
- 映射、折叠和拉链
主要的collection特质
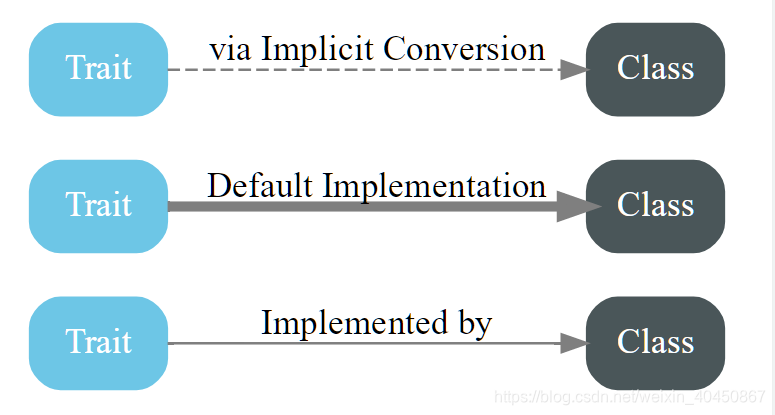
- 下面请欣赏一组图片,注意蓝底白字(特质trait)和黑底白字(类class),虚线(隐式转换)和粗实线(默认实现)、细实线(通过类实现)。图片来源。
- 首先是scala.collection
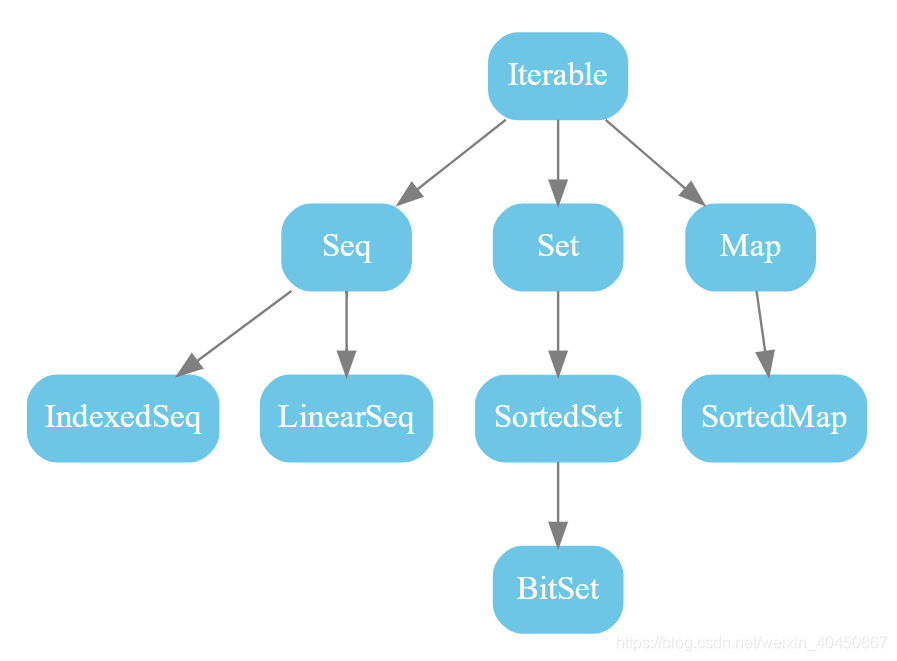
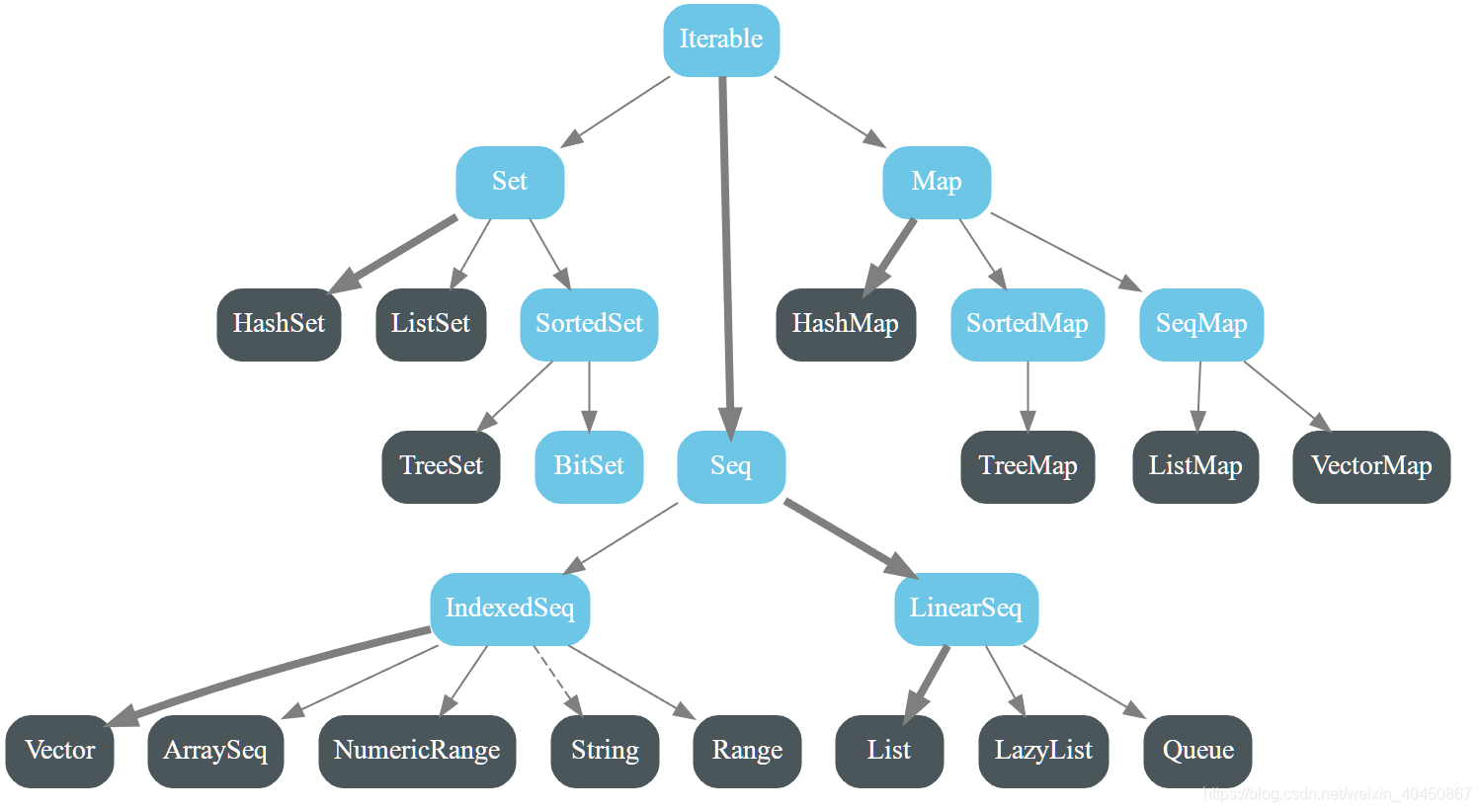
- scala.collection.immutable
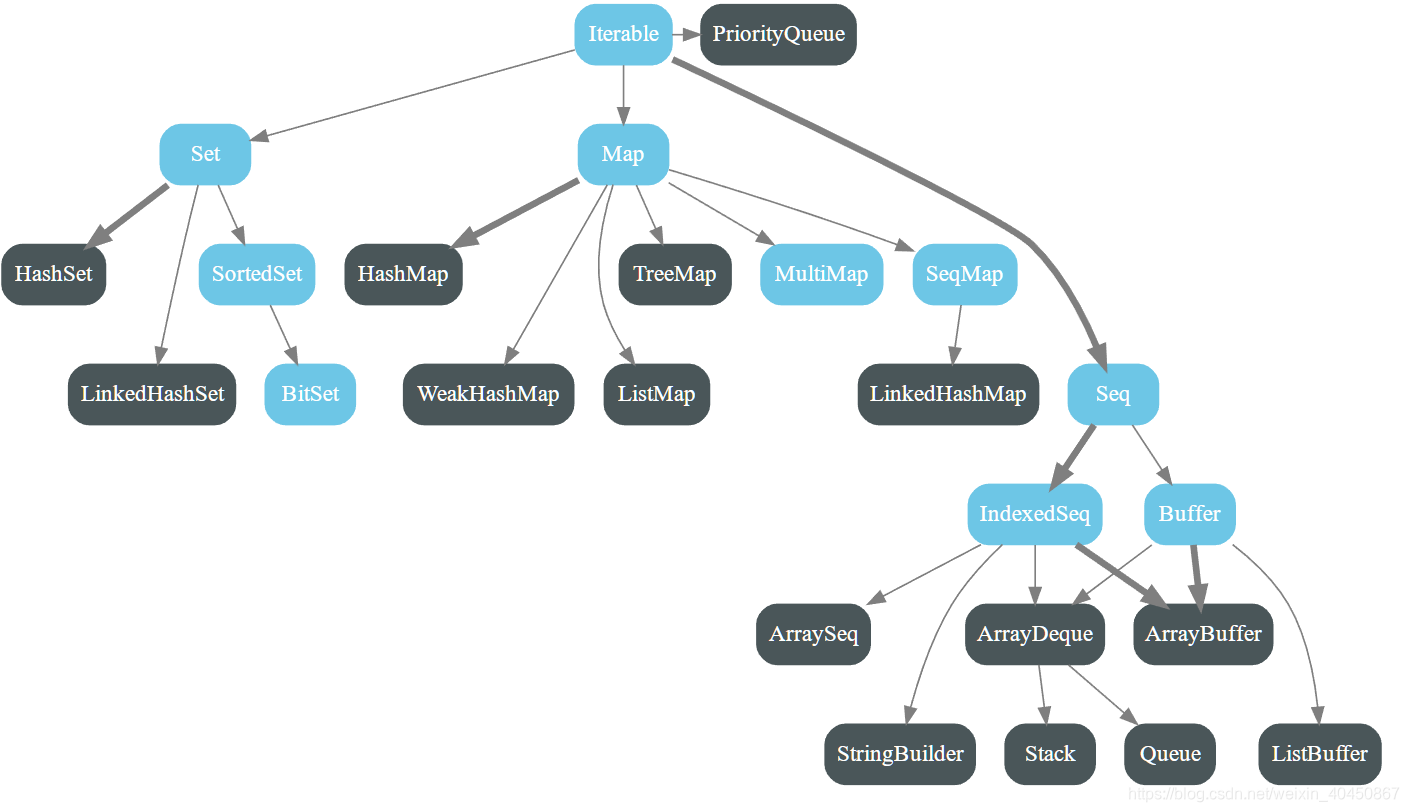
- scala.collection.mutable
- 图例
- Iterable指的是那些能够交出用来访问集合中所有元素的Iterator的集合
val coll = List(2,1,4,3) //任意Iterable特质的类
val iter = coll.iterator
while (iter.hasNext){println(iter.next())}
- Seq是一个有先后次序的值的序列,例如数组或列表,IndexedSeq可以通过整型下标快速访问任意元素,ArrayBuffer带下标但链表不带。
- Set是一组没有先后次序的值。
- Map是一组键值的对偶。
- 每一个collection特质或类都带有一个apply方法的伴生对象,这个apply方法可以用来构建collection中的实例。
- 上面的三个图中出现的特质或类,统统可以直接拿来创建实例。图中粗实线是默认实现的关系,不管是Seq还是Iterable,默认的都是List
scala> Seq(1,2,3)
res1: Seq[Int] = List(1, 2, 3)
scala> Iterable(1,2,3)
res2: Iterable[Int] = List(1, 2, 3)
- 不同collection之间的转换,可以调用toXX方法,和to[C]的泛型方法
scala> val list = List(1,2,3)
list: List[Int] = List(1, 2, 3)
scala> list.toVector
res5: Vector[Int] = Vector(1, 2, 3)
scala> list.to[Vector]
res6: Vector[Int] = Vector(1, 2, 3)
- 使用==操作符实现任何seq、set、map的比较,如果不同类的collection比较,可以使用sameElements方法比较元素是否是相同。
scala> list == Vector(1,2,3)
res8: Boolean = true
scala> list == Set(1,2,3)
res9: Boolean = false
scala> list sameElements Set(1,2,3,2)
res10: Boolean = true
可变和不可变的collection
- 不可变的collection可以安全共享引用,在多线程的应用程序中也无妨,scala.collection.Map, scala.collection.mutable.Map, scala.collection.immutable.Map,第一个是第二个和第三个的超类型
- scala优先采用不可变集合,scala包和Predef对象里还有指向不可变特质的类型别名List、Set、Map。
- 使用可变的,import scala.collection.mutable,然后使用mutable.Map就是可变的了。
序列Seq
- 不可变的Seq
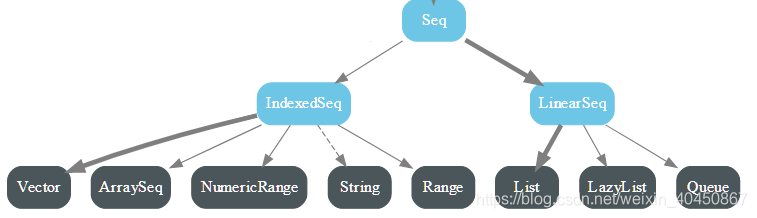
- 可变的Seq
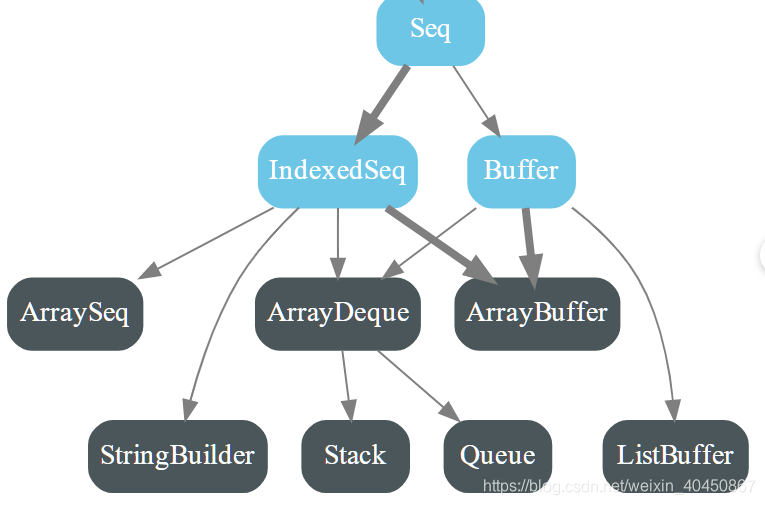
- 对比上面两个图可以看出,不可变版的默认实现是Vector,可变版本的默认实现是ArrayBuffer。
- Vector支持快速随机访问,是以树形结构的形式实现,每个节点可以有不超过32个子节点,速度很快
- Range表示一个整数序列,只存储开始值、结束值、增值,可以使用to和until方法构造Range对象
- 此外还有栈、队列、优先级队列等
scala> Range(1,10)
res16: scala.collection.immutable.Range = Range(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> Range(1,10,2)
res17: scala.collection.immutable.Range = Range(1, 3, 5, 7, 9)
scala> 1 until 10
res18: scala.collection.immutable.Range = Range(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> 1 to 10
res19: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
//栈
scala> val a = collection.mutable.Stack(1,2,3)
a: scala.collection.mutable.Stack[Int] = Stack(1, 2, 3)
//入栈
scala> a.push(10)
res19: a.type = Stack(10, 1, 2, 3)
//出栈
scala> a.pop
res20: Int = 10
scala> a
res21: scala.collection.mutable.Stack[Int] = Stack(1, 2, 3)
//队列
scala> val b = collection.mutable.Queue(1,2,3,4)
b: scala.collection.mutable.Queue[Int] = Queue(1, 2, 3, 4)
//入队
scala> b.enqueue(7)
//出队
scala> b.dequeue
res23: Int = 1
列表
- 列表只有头和尾,head和tail,空列表Nil,head是第一个元素,tail是除了第一个元素以外的所有元素。
scala> val list = List(1,2,3,4)
list: List[Int] = List(1, 2, 3, 4)
scala> list.head
res24: Int = 1
scala> list.tail
res25: List[Int] = List(2, 3, 4)
scala> List(1).tail
res26: List[Int] = List()
- 从给定的head和tail创建新列表 使用
::操作符,这个操作符是右结合的,其右边需要是个List
scala> 100::list
res28: List[Int] = List(100, 1, 2, 3, 4)
//下面的错误
scala> list :: 100
<console>:13: error: value :: is not a member of Int
list :: 100
scala> list ::list
res30: List[Any] = List(List(1, 2, 3, 4), 1, 2, 3, 4)
//使用递归访问列表,当然比较低效,下面的代码就出现了java.lang.StackOverflowError
def sum(lst:List[Int]):Double={
if (lst == Nil) 0 else (lst.head * 1.0) + sum(lst.tail)
}
val a = (1 to 100000).toList
//使用模式匹配计算,同样的错误
def sum2(lst:List[Int]):Int=lst match{
case Nil => 0
case h :: t => h+sum2(t)
}
- 可别版本的List使用ListBuffer,链表支撑的数据结构,高效地从任意一端添加或移除元素,但是添加或移除元素并不高效。
集 Set
- Set是不重复的元素的collection,默认顺序是hashcode方法进行组织,这样查找元素比在数组或列表中更快
scala> val s = Set(1,2,3)
s: scala.collection.immutable.Set[Int] = Set(1, 2, 3)
scala> s+1
res34: scala.collection.immutable.Set[Int] = Set(1, 2, 3)
- 链式哈希set可以保留元素的插入顺序LinkedHashSet
//多参数
scala> Set(1 to 5: _*)
res8: scala.collection.immutable.Set[Int] = Set(5, 1, 2, 3, 4)
scala> for(i <- Set(1,2,3,4,5,6)) println(i)
5
1
6
2
3
4
scala> val s1 = collection.mutable.LinkedHashSet(1,2,3,4,5,6)
s1: scala.collection.mutable.LinkedHashSet[Int] = Set(1, 2, 3, 4, 5, 6)
scala> for(i <- s1) println(i)
1
2
3
4
5
6
- 已排序集合 SortedSet
scala> collection.mutable.SortedSet(5,1,3,2,4)
res11: scala.collection.mutable.SortedSet[Int] = TreeSet(1, 2, 3, 4, 5)
- 位组集合,BitSet,以一个字符序列的方式存放非负整数,只能是正的Int型的,不能太大,也不能是其他类型的。如果位组中有i,那么低i个字位是1。
scala> collection.immutable.BitSet(1,2,3,2)
res35: scala.collection.immutable.BitSet = BitSet(1, 2, 3)
scala> collection.immutable.BitSet(1,2,2100000000)
java.lang.OutOfMemoryError: Java heap space
- contains方法检查一个集合是不是包含某个元素,subsetOf方法检查某个集合是否被另一个集合包含
- 集合的运算,交集、并集、差集,符号太麻烦,还是记忆union intersect diff简单
| 操作 | 方法 | 符号1 | 符号2 |
|---|---|---|---|
| 并 | union | | | ++ |
| 交 | intersect | & | |
| 差 | diff | &~ | -- |
scala> val s1 = Set(1,2,3)
s1: scala.collection.immutable.Set[Int] = Set(1, 2, 3)
scala> val s2 = Set(2,3,4)
s2: scala.collection.immutable.Set[Int] = Set(2, 3, 4)
scala> val s3 = Set(7,8)
s3: scala.collection.immutable.Set[Int] = Set(7, 8)
scala> s1.union(s2)
res38: scala.collection.immutable.Set[Int] = Set(1, 2, 3, 4)
scala> s1.intersect(s2)
res39: scala.collection.immutable.Set[Int] = Set(2, 3)
scala> s1.diff(s2)
res40: scala.collection.immutable.Set[Int] = Set(1)
scala> s3.intersect(s1)
res41: scala.collection.immutable.Set[Int] = Set()
添加或去除元素的操作符
- 当你想添加或删除某个元素或某些元素时,操作符取决于容器类型
- coll(k) , 即coll.apply(k)
排在第k位的元素,或键k对应的映射值,适合Seq,Map - coll :+ elem 或 elem +: coll,向后追加或向前追加了elem的与coll类型相同的容器,适合Seq。冒号靠近coll
scala> val a = List(1,2,3)
a: List[Int] = List(1, 2, 3)
scala> a :+ 4
res0: List[Int] = List(1, 2, 3, 4)
scala> 4 +: a
res1: List[Int] = List(4, 1, 2, 3)
- coll + elem 或 coll + (e1,e2,…)添加了给定元素的与coll相同的容器,适合Set Map
scala> val s = Set(1,2,3)
s: scala.collection.immutable.Set[Int] = Set(1, 2, 3)
scala> s + 5
res2: scala.collection.immutable.Set[Int] = Set(1, 2, 3, 5)
scala> s + (6,7)
res3: scala.collection.immutable.Set[Int] = Set(1, 6, 2, 7, 3)
- coll - elem 或 coll - (e1,e2,…)移除了给定元素的与coll相同的容器,适合Set Map ArrayBuffer
scala> s - 1
res4: scala.collection.immutable.Set[Int] = Set(2, 3)
scala> s - (2,3)
res5: scala.collection.immutable.Set[Int] = Set(1)
- coll ++ coll2或coll2 ++: coll,与coll类型相同的容器,同时包含两个容器,适用于Iterable
scala> val r = 1 to 10
r: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> val l = List(20,22)
l: List[Int] = List(20, 22)
scala> r ++ l
res7: scala.collection.immutable.IndexedSeq[Int] = Vector(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 22)
scala> r ++: l
res8: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 22)
scala> s ++ r
res9: scala.collection.immutable.Set[Int] = Set(5, 10, 1, 6, 9, 2, 7, 3, 8, 4)
scala> r ++ s
res10: scala.collection.immutable.IndexedSeq[Int] = Vector(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3)
- coll --coll2,移除coll中的coll2,相当于diff,适用于Set Map ArrayBuffer
scala> s -- r
res15: scala.collection.immutable.Set[Int] = Set()
- elem :: lst,lst2 ::: lst,追加到lst中,适用于List ,带冒号的是右结合的,左边的元素添加都右边
三个冒号和 ++: 一样,两个冒号和 +: 一样
scala> 1 :: List(3,4)
res19: List[Int] = List(1, 3, 4)
scala> List(1,2) :: List(3,4)
res20: List[Any] = List(List(1, 2), 3, 4)
scala> List(1,2) ::: List(3,4)
res21: List[Int] = List(1, 2, 3, 4)
scala> List(1,2) ++: List(3,4)
res22: List[Int] = List(1, 2, 3, 4)
scala> List(1,2) +: List(3,4)
res23: List[Any] = List(List(1, 2), 3, 4)
- set | set2 , set & set2 ,set &~ set2,并交差集,适用于Set
- coll += elem,coll += (e1,e2,…) ,coll ++= coll2 ,coll -= elem,coll -= (e1,e2,…) ,coll --= coll2,通过添加或移除元素修改coll,适用于可变的collection
scala> val s = collection.mutable.Set(1,2,3)
s: scala.collection.mutable.Set[Int] = Set(1, 2, 3)
scala> s += 4
res24: s.type = Set(1, 2, 3, 4)
scala> s += (5,6,7)
res25: s.type = Set(1, 5, 2, 6, 3, 7, 4)
scala> s ++= Set(8,9)
res26: s.type = Set(9, 1, 5, 2, 6, 3, 7, 4, 8)
scala> s -= (1,2,3)
res27: s.type = Set(9, 5, 6, 7, 4, 8)
scala> s --= Set(9,10,11)
res28: s.type = Set(5, 6, 7, 4, 8)
- elem +=: coll,coll2 ++=:coll1,通过向前追加给定元素修改coll,适合ArrayBuffer
scala> val a = collection.mutable.ArrayBuffer(1,2)
a: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2)
scala> 4 +=: a
res30: a.type = ArrayBuffer(4, 1, 2)
scala> a += 5
res32: a.type = ArrayBuffer(4, 1, 2, 5)
scala> List(7,8) ++=: a
res33: a.type = ArrayBuffer(7, 8, 4, 1, 2, 5)
常用方法
介绍




Iterable常用方法
- head,last,headOption,lastOption
scala> val a = List(1,2,3,4,5)
a: List[Int] = List(1, 2, 3, 4, 5)
scala> a.head
res0: Int = 1
scala> a.last
res1: Int = 5
scala> a.headOption
res2: Option[Int] = Some(1)
scala> a.lastOption
res3: Option[Int] = Some(5)
- tail,init
scala> a.tail
res4: List[Int] = List(2, 3, 4, 5)
scala> a.init
res5: List[Int] = List(1, 2, 3, 4)
//init 和 last,head和tail能够拼接成完整的列表
scala> a.init :+ a.last
res8: List[Int] = List(1, 2, 3, 4, 5)
scala> a.head +: a.tail
res9: List[Int] = List(1, 2, 3, 4, 5)
- length,isEmpty
scala> a.length
res10: Int = 5
scala> a.isEmpty
res11: Boolean = false
scala> Nil.isEmpty
res12: Boolean = true
- map,flatMap,foreach,transform,collect
scala> val s = "I love China I love my homeland"
s: String = I love China I love my homeland
scala> val words = s.split(" ")
words: Array[String] = Array(I, love, China, I, love, my, homeland)
scala> words.map(_.toUpperCase)
res16: Array[String] = Array(I, LOVE, CHINA, I, LOVE, MY, HOMELAND)
scala> Array("I love China","I love my homeland","I love programming").map(_.split(" "))
res22: Array[Array[String]] = Array(Array(I, love, China), Array(I, love, my, homeland), Array(I, love, programming))
scala> Array("I love China","I love my homeland","I love programming").flatMap(_.split(" "))
res23: Array[String] = Array(I, love, China, I, love, my, homeland, I, love, programming)
scala> words.foreach(println)
I
love
China
I
love
my
homeland
// transform适用于可变的容器,直接修改本身,而不是生成新的
scala> collection.mutable.ArrayBuffer(1,2,3).transform(_*2)
res31: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 4, 6)
//collect
scala> "+3-1".collect{case '+' => 1; case '-' => -1}
//scala.collection.immutable.IndexedSeq[Int] = Vector(1, -1)
scala> s.collect{case x if x.isUpper => 1;case y if y.isLower => -1; case _ => 0}
// scala.collection.immutable.IndexedSeq[Int] = Vector(1, 0, -1, -1, -1, -1, 0, 1, -1, -1, -1, -1, 0, 1, 0, -1, -1, -1, -1, 0, -1, -1, 0, -1, -1, -1,-1, -1, -1, -1, -1)
//collect的参数函数不一定需要对每个输入都有定义
scala> s.collect{case x if x.isUpper => 1}
res2: scala.collection.immutable.IndexedSeq[Int] = Vector(1, 1, 1)
- reduceLeft.reduceRight,foldLeft,foldRIght
scala> a.map(_.toString).reduceLeft((x,y)=>(s"f(${x},${y})"))
res60: String = f(f(f(f(1,2),3),4),5)
scala> a.map(_.toString).reduceRight((x,y)=>(s"f(${x},${y})"))
res61: String = f(1,f(2,f(3,f(4,5))))
scala> a.map(_.toString).foldLeft("0")((x,y)=>(s"f(${x},${y})"))
res65: String = f(f(f(f(f(0,1),2),3),4),5)
scala> a.map(_.toString).foldRight("0")((x,y)=>(s"f(${x},${y})"))
res67: String = f(1,f(2,f(3,f(4,f(5,0)))))
- reduce,fold,aggregate
(Since version 2.13.0) aggregate is not relevant for sequential collections. Use foldLeft(z)(seqop) instead.
scala> a.map(_.toString).reduce((x,y)=>(s"f(${x},${y})"))
res71: String = f(f(f(f(1,2),3),4),5)
scala> a.map(_.toString).fold("0")((x,y)=>(s"f(${x},${y})"))
res72: String = f(f(f(f(f(0,1),2),3),4),5)
scala> val c = Array("1","2","3","4","5","6")
c: Array[String] = Array(1, 2, 3, 4, 5, 6)
//aggregate较难理解,针对并行的collection
scala> c.par.aggregate("0")(
| {(x:String,y:String)=>s"f(${x},${y})"},
| {(a:String,b:String)=>s"g(${a},${b})"}
| )
res74: String = g(g(f(0,1),g(f(0,2),f(0,3))),g(f(0,4),g(f(0,5),f(0,6))))
- sum product max min
scala> a.sum
res79: Int = 15
scala> a.product
res80: Int = 120
scala> a.min
res81: Int = 1
scala> a.max
res82: Int = 5
scala> (1 to 100) .product
res84: Int = 0
- count forall,exists
scala> a.count( _ > 2)
res2: Int = 3
scala> a.forall( _ > 2)
res3: Boolean = false
scala> a.forall( _ > 0)
res4: Boolean = true
scala> a.exists( _ > 0)
res5: Boolean = true
scala> a.exists( _ < 0)
res6: Boolean = false
- filter , filterNot , partition
scala> a.filter( _ > 2 )
res7: List[Int] = List(3, 4, 5)
scala> a.filter( _ > 10 )
res8: List[Int] = List()
scala> a.filterNot( _ > 10 )
res9: List[Int] = List(1, 2, 3, 4, 5)
scala> a.partition( _ > 10 )
res10: (List[Int], List[Int]) = (List(),List(1, 2, 3, 4, 5))
scala> a.partition( _ > 2 )
res11: (List[Int], List[Int]) = (List(3, 4, 5),List(1, 2))
- takeWhile(pred), dropWhile (pred), span (pred)
scala> val b = List(3,1,2,9,1,8,2)
b: List[Int] = List(3, 1, 2, 9, 1, 8, 2)
scala> b.takeWhile(_ > 3)
res12: List[Int] = List()
scala> b.dropWhile(_ > 3)
res13: List[Int] = List(3, 1, 2, 9, 1, 8, 2)
scala> b.span(_ > 3)
res14: (List[Int], List[Int]) = (List(),List(3, 1, 2, 9, 1, 8, 2))
scala> b.takeWhile(_ < 4)
res15: List[Int] = List(3, 1, 2)
scala> b.span(_ < 4)
res16: (List[Int], List[Int]) = (List(3, 1, 2),List(9, 1, 8, 2))
- take drop splitAt
scala> b
res17: List[Int] = List(3, 1, 2, 9, 1, 8, 2)
scala> b.take(3)
res18: List[Int] = List(3, 1, 2)
scala> b.drop(3)
res19: List[Int] = List(9, 1, 8, 2)
scala> b.splitAt(3)
res20: (List[Int], List[Int]) = (List(3, 1, 2),List(9, 1, 8, 2))
- takeRight,dropRIght
scala> b.takeRight(3)
res0: List[Int] = List(1, 8, 2)
scala> b.dropRight(3)
res1: List[Int] = List(3, 1, 2, 9)
- slice,view
scala> b.slice(2,4)
res2: List[Int] = List(2, 9)
scala> b.view(2,4)
res5: scala.collection.SeqView[Int,List[Int]] = SeqViewS(...)
//调用view的force方法求值
scala> b.view(2,4).force
res6: List[Int] = List(2, 9)
- zip,zipAll,zipWithIndex
scala> val prices = List(5.0,20.0,9.95)
prices: List[Double] = List(5.0, 20.0, 9.95)
scala> val quantities = List(10,2,1)
quantities: List[Int] = List(10, 2, 1)
//zip后的每个元素是个二元组
scala> prices.zip(quantities)
res7: List[(Double, Int)] = List((5.0,10), (20.0,2), (9.95,1))
//如果一个比较短,则以短的为主
scala> prices.zip(List(5,20))
res8: List[(Double, Int)] = List((5.0,5), (20.0,20))
scala> prices.zip(Nil)
res10: List[(Double, Nothing)] = List()
//zipAll可以指定默认值,如果下例中,0是prices的默认值,1是参数列表的默认值
scala> prices.zipAll(List(5,20),0,1)
res12: List[(AnyVal, Int)] = List((5.0,5), (20.0,20), (9.95,1))
scala> prices.zipAll(List(5,20,21,22,23),0,1)
res13: List[(AnyVal, Int)] = List((5.0,5), (20.0,20), (9.95,21), (0,22), (0,23))
//zipWIthIndex结果的第二个元素是第一个元素的下标索引
scala> prices.zipWithIndex
res14: List[(Double, Int)] = List((5.0,0), (20.0,1), (9.95,2))
- grouped(n),sliding(n)返回长度为n的子集合迭代器,
scala> b
res16: List[Int] = List(3, 1, 2, 9, 1, 8, 2)
//滑动窗口步长为n,窗口大小为n
scala> b.grouped(3).toList
res18: List[List[Int]] = List(List(3, 1, 2), List(9, 1, 8), List(2))
//滑动窗口,步长为1,窗口大小为n
scala> b.sliding(3).toList
res19: List[List[Int]] = List(List(3, 1, 2), List(1, 2, 9), List(2, 9, 1), List(9, 1, 8), List(1, 8, 2))
- groupBy(function),返回一个映射,对于每一个x,由y=function(x),键是所有的y,值是y对应的所有的x
scala> b
res23: List[Int] = List(3, 1, 2, 9, 1, 8, 2)
scala> b.groupBy(_*3)
res24: scala.collection.immutable.Map[Int,List[Int]] = Map(24 -> List(8), 6 -> List(2, 2), 9 -> List(3), 27 -> List(9), 3 -> List(1, 1))
- mkString,addString
//mkString接受一个或三个参数
scala> b.mkString("-")
res25: String = 3-1-2-9-1-8-2
scala> b.mkString("!","-","?")
res26: String = !3-1-2-9-1-8-2?
//addString将字符串添加到StringBuilder中,字符串构建器
//返回的是修改后的StringBuilder
scala> val sb = new StringBuilder
sb: StringBuilder =
scala> b.addString(sb,"-")
res29: StringBuilder = 3-1-2-9-1-8-2
scala> b.addString(sb,"!","-","?")
res30: StringBuilder = 3-1-2-9-1-8-2!3-1-2-9-1-8-2?
- toIterable,to[C]转换为其他类型的collection
scala> b.to
to toBuffer toIterable toList toParArray toSet toString toVector
toArray toIndexedSeq toIterator toMap toSeq toStream toTraversable
Seq常用方法
- contains,containsSlice,startsWith,endsWith,第一个的参数为元素,其他的参数为Seq
scala> b
res32: List[Int] = List(3, 1, 2, 9, 1, 8, 2)
scala> b.contains(9)
res33: Boolean = true
scala> b.containsSlice(Array(2,9))
res34: Boolean = true
scala> b.containsSlice(Array(2,9,2))
res35: Boolean = false
scala> b.startsWith(Array(3))
res37: Boolean = true
scala> b.startsWith(Array(2))
res38: Boolean = false
scala> b.startsWith(Array(3,1,2))
res39: Boolean = true
scala> b.endsWith(Array(2))
res40: Boolean = true
- indexOf,lastIndexOf,indexOfSlice,lastIndexOfSlice
第一个或最后一个的索引
scala> b
res41: List[Int] = List(3, 1, 2, 9, 1, 8, 2)
scala> b.indexOf(1)
res42: Int = 1
scala> b.lastIndexOf(1)
res43: Int = 4
scala> b.indexOfSlice(Array(1,2,9))
res44: Int = 1
scala> b.lastIndexOfSlice(Array(2))
res45: Int = 6
- indexWhere满足条件的首个元素的下标
scala> b.indexWhere(_>7)
res47: Int = 3
- prefixLength,segmentLength,第一个满足条件的最长元素序列的长度,
segmentLength可以指定从第几个元素开始查找。
scala> b
res50: List[Int] = List(3, 1, 2, 9, 1, 8, 2)
scala> b.prefixLength(_ < 8)
res51: Int = 3
scala> b
res52: List[Int] = List(3, 1, 2, 9, 1, 8, 2)
scala> b.segmentLength(_ < 8 , 3)
res53: Int = 0
scala> b.segmentLength(_ < 8 , 2)
res54: Int = 1
scala> b.segmentLength(_ < 8 , 1)
res55: Int = 2
- padTo(n,fill),拷贝当前seq到一个新的,长度为n,如果原来的长度不够就用fill填充,如果原长度更大就返回原Seq的拷贝
scala> b.padTo(20,5)
res57: List[Int] = List(3, 1, 2, 9, 1, 8, 2, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5)
scala> b.padTo(4,5)
res59: List[Int] = List(3, 1, 2, 9, 1, 8, 2)
- intersect,diff,类似Set的交集、差集,不过只对第一次满足条件的操作
scala> b
res65: List[Int] = List(3, 1, 2, 9, 1, 8, 2)
scala> b.intersect(Array(1,2,5))
res66: List[Int] = List(1, 2)
scala> b.diff(Array(1,2,5))
res67: List[Int] = List(3, 9, 1, 8, 2)
scala> b.union(Array(1,2,5))
res68: List[Int] = List(3, 1, 2, 9, 1, 8, 2, 1, 2, 5)
- reverse
scala> b.reverse
res69: List[Int] = List(2, 8, 1, 9, 2, 1, 3)
- sorted,sortWith,sortBy
scala> b.sorted
res72: List[Int] = List(1, 1, 2, 2, 3, 8, 9)
scala> b.sortWith(_>_)
res75: List[Int] = List(9, 8, 3, 2, 2, 1, 1)
9.permutations,combinations(n)返回所有排列组合的迭代器,n为指定子序列的长度
scala> List(1,2,3).permutations.toList
res78: List[List[Int]] = List(List(1, 2, 3), List(1, 3, 2), List(2, 1, 3), List(2, 3, 1), List(3, 1, 2), List(3, 2, 1))
scala> List(1,2,1).permutations.toList
res79: List[List[Int]] = List(List(1, 1, 2), List(1, 2, 1), List(2, 1, 1))
scala> List(1,2,3).combinations(2).toList
res81: List[List[Int]] = List(List(1, 2), List(1, 3), List(2, 3))
流
- 流stream是一个尾部被懒计算的不可变列表,也就是说只有当你需要时才被计算
- 流会缓存访问过的行
- 不要直接使用.force,应该先用take再用force
scala> def numsFrom(n:BigInt):Stream[BigInt] = n #:: numsFrom(n+1)
numsFrom: (n: BigInt)Stream[BigInt]
//得到的是流对象
scala> val tenOrMore = numsFrom(10)
tenOrMore: Stream[BigInt] = Stream(10, ?)
scala> tenOrMore.tail.tail.tail
res3: scala.collection.immutable.Stream[BigInt] = Stream(13, ?)
scala> tenOrMore.take(5).force
res4: scala.collection.immutable.Stream[BigInt] = Stream(10, 11, 12, 13, 14)
//不要直接使用.force,应该先用take再用force
scala> import scala.io.Source
import scala.io.Source
scala> val words = Source.fromFile("D:\\data\\shuihu.txt").getLines.toStream
words: scala.collection.immutable.Stream[String] = Stream(1 天魁星 呼保义 宋江, ?)
scala> words(5)
res0: String = 6 天雄星 豹子头 林冲
scala> words.take(5).force
res1: scala.collection.immutable.Stream[String] = Stream(1 天魁星 呼保义 宋江, 2 天罡星 玉麒麟 卢俊义, 3 天机星 智多星 吴用, 4 天闲星 入云龙 公孙胜, 5 天勇星 大刀 关胜)
scala> s.mkString("\n")
res3: String =
1 天魁星 呼保义 宋江
2 天罡星 玉麒麟 卢俊义
3 天机星 智多星 吴用
4 天闲星 入云龙 公孙胜
5 天勇星 大刀 关胜
懒视图 lazy view
- 使用view方法得到懒视图
- force方法可以强制求值,但是不要直接使用流的force方法
- 跟流不同,视图不会缓存任何值,再次调用时会从头开始计算
scala> val palindromicSquares =(1 to 100000).view.map(x=>x*x).filter(x=> x.toString == x.toString.reverse )
palindromicSquares: scala.collection.SeqView[Int,Seq[_]] = SeqViewMF(...)
//执行如下代码会执行得到十个
scala> palindromicSquares.take(10).mkString(",")
res4: String = 1,4,9,121,484,676,10201,12321,14641,40804
- 调用apply方法会强制对整个视图求值
//不要这样调用
scala> palindromicSquares(20)
res7: Int = 102030201
//使用下面的方法
scala> palindromicSquares.take(20).last
res9: Int = 100020001
并行collection
- 很方便的并发执行,例如 coll.par.sum
- par方法产生当前集合的一个并行实现,会尽可能并行地执行集合方法
- 可以发现使用了所有核的CPU进行了计算
scala> (1 to 1000000000).par.sum

- 使用for循环遍历par后的,可以看到顺序是按照作用于该任务的线程产出的顺序输出的。
- 而如果使用for/yield循环,可以看到介个是依次组装的
scala> for (i <- (1 to 24).par) print(s"${i} ")
1 2 3 19 5 10 11 7 16 18 20 21 17 8 9 12 24 4 23 13 22 6 15 14
scala> for (i <- (1 to 24).par) yield(s"${i} ")
res16: scala.collection.parallel.immutable.ParSeq[String] = ParVector("1 ", "2 ", "3 ", "4 ", "5 ", "6 ", "7 ", "8 ", "9 ", "10 ", "11 ", "12 ", "13 ", "14 ", "15 ", "16 ", "17 ", "18 ", "19 ", "20 ", "21 ", "22 ", "23 ", "24 ")
scala> (for (i <- (1 to 1000).par) yield i) == (1 to 1000)
res18: Boolean = true
- 如果并行运算修改了共享的变量,结果无法预知,不要更新一个共享计数器,如果非要这样做,结果不是预期的结果了。
scala> var count = 0
count: Int = 0
scala> for (i <- (1 to 24).par) count += 1
//看起来没问题
scala> count
res20: Int = 24
//如果数再大点
scala> var count = 0
count: Int = 0
scala> for (i <- (1 to 24000).par) count += 1
scala> count
res25: Int = 4946
//再试一次,结果又变了
scala> var count = 0
count: Int = 0
scala> for (i <- (1 to 24000).par) count += 1
scala> count
res27: Int = 6742
- 使用seq方法将并行collection转为顺序的
val result = (1 to 100).par.map(_+1).seq
- 不是所有的方法都能被并行化
- 默认情况下,并行集合使用全局的fork-join线程池,适用于高处理器开销的计算,如果执行的步骤包含阻塞调用,应该选用执行上下文(execution context),第17章
