解释过程
HTML 解释器的工作就是将网络或者本地磁盘获取的 HTML 网页和资源从字节流解释成 DOM 树结构。这一过程大致可以理解成下图
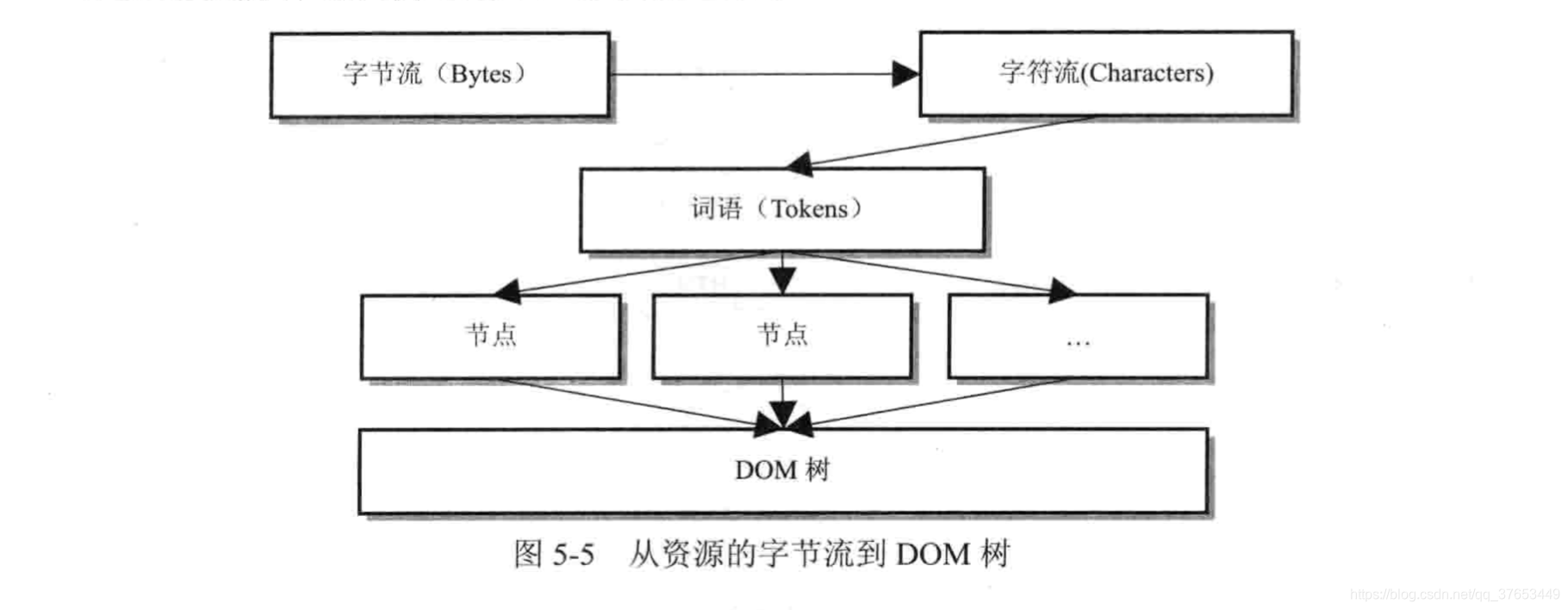
WebKit 中这一过程如下:首先是字节流,经过解码之后是字符流,然后通过词法分析器把字符流解释成词语(Tokens),之后经过语法分析器构建成节点,最后这些节点被组建成一棵 DOM 树。
词法分析
在进行词法分析之前,解释器首先要做的事情就是检查该网页内容使用的编码格式,以便后面使用合适的解码器。如果解释器在 HTML 网页中找到了设置的编码格式, WebKit 会使用相应的解码器来将字节流转换成特定格式的字符串。如果没有特殊格式,词法分析器 HTMLTokenizer 类可以直接进行词法分析
词法分析的工作都是由 HTMLTokenizer 来完成 ,简单来说,它就是一个状态机---输入的是字符串,输出的是一个个词语。因为字节流可能是分段的,所以输入的字符串可能也是分段的,但是这对词法分析器来说没有什么特别之处,它会自己维护内部的状态信息。
XSSAuditor 验证词语
当词语生成之后,WebKit 需要使用 XSSAuditor 来验证词语流(Token Stream)。XSS 指的是 Cross Site Security , 主要是针对安全方面的考虑。
根据 XSS 的安全机制,对于解析出来的这些词语,可能会阻碍某些内容的进一步执行,所以 XSSAuditor 类主要负责过滤这些被阻止的内容,只有通过的词语才会作后面的处理
词语到节点
经过词法分析器解释之后的词语随之被 XSSAuditor 过滤并且在没有被阻止之后,将被 WebKit 用来构建 DOM 节点。从词语到构建节点的步骤是由 HTMLDocumentParser 类调用 HTMLTreeBuilder 类的 “constructTree” 函数来实现。
节点到 DOM 树
从节点到构建 DOM 树,包括为树中的元素节点创建属性节点等工作由 HTMLConstructionSite 类来完成。正如前面介绍的,该类包含一个 DOM 树的根节点 ——HTMLDocument 对象,其他的元素节点都是它的后代。
因为
HTML 文档的 Tag 标签是有开始和结束标记的,所以构建这一过程可以使用栈结构来帮忙。HTMLConstructionSite 类中包含一个 “HTMLElementStack” 变量,它是一个保存元素节点的栈,其中的元素节点是当前有开始标记但是还没有结束标记的元素节点。想象一下 HTML 文档的特点,例如一个片段<body><div><img></img></div></body>当解释到 img 元素的开始标记时,栈中的元素就是 body 、div 和 img ,当遇到 img 的结束标记时,img 退栈, img 是 div 元素的子女;当遇到 div 的结束标记时,div 退栈,表明 div 和它的子女都已处理完,以此类推。
JavaScript 的执行
在 HTML 解释器的工作过程中,可能会有 JavaScript 代码(全局作用域的代码)需要执行,它发生在将字符串解释成词语之后、创建各种节点的时候。这也是全局执行的 JavaScript 代码不能访问 DOM 树的原因——因为 DOM 树还没有被创建完
所以建议 JavaScript 的使用如下
1、将 “script” 元素加上 “async” 属性,表明这是一个可以异步执行的 JavaScript 代码。
2、将 “script” 元素放在 “body” 元素的最后,这样它不会阻碍其他资源的并发下载。
但是不这样做的时候,WebKit 使用预扫描和预加载机制来实现资源的并发下载而不被 JavaScript 的执行所阻碍。
具体做法是:当遇到需要执行 JavaScript 代码的时候,WebKit 先暂停当前 JavaScript 代码的执行,使用预先扫描器 HTMLPreloadScanner 类来扫描后面的词语。如果 WebKit 发现它们需要使用其他资源,那么使用预资源加载器 HTMLPreloadScanner 类来发送请求,在这之后,才执行 JavaScript代码。预先扫描器本身并不创建节点对象,也不会构建 DOM 树,所以速度比较快。
当 DOM 树构建完之后,WebKit 触发 “DOMContentLoaded” 事件,注册在该事件上的 JavaScript 函数会被调用。当所在资源都被加载完之后,WebKit 触发 “onload” 事件
DOM 事件机制
事件在工作过程中使用两个主体,第一个是事件(event),第二个是事件目标(EventTarget)。WebKit 中用 EventTarget 类来表示 DOM 规范中 Events 部分定义的事件目标
每个 事件都有属性来标记该事件的事件目标。当事件到达事件目标(如一个元素节点)的时候,在这个目标上注册的监听者(Event Listeners)都会有触发调用,而这些监听者的调用顺序不是固定的,所以不能依赖监听者注册的顺序来决定你的代码逻辑
事件处理最重要就是事件捕获(Event capture)和事件冒泡(Event bubbling)这两种机制。图 5-18 是事件捕获和事件冒泡的过程。

当渲染引擎接收到一个事件的时候,它会通过 HitTest(WebKit 中的一种检查触发gkwrd哪个区域的算法)检查哪个元素是直接的事件目标。在图 5-18 中,以 “img” 为例,假设它是事件的直接目标,这样,事件会经过自顶向下和自底向上的两个过程。
事件的捕获是自顶向下,事件先是到 document 节点,然后一路到达目标节点。在图 5-18 中,顺序就是 “#document” -> “HTML” -> “body” -> “img” 这样一个顺序。事件可以在这一传递过程中被捕获,只需要在注册监听者的时候设置相应参数即可。默认情况下,其他节点不捕获这样的事件。如果网页注册了这样的监听者,那么监听者的回调函数会被调用,函数可以通过事件的 “stopPropagation” 函数来阻止事件向下传递
事件的冒泡过程是从下向上的顺序,它的默认行为是不冒泡,但是是事件包含一个是否冒泡的属性。当这一属性为真的时候,渲染引擎会将该事件首先传递给事件的目标节点的父亲,然后是父亲的父亲,以此类推。同捕获动作一样,这此监听函数也可以使用 “stopPropagation” 函数来阻止事件向上传递
WebKit 的事件处理机制
DOM 的事件分为很多种,与用户相关的只是其中的一种,称为 UIEvent ,其他的包括 CustomEvent、MutationEvent 等。UIEvent 又可以分为很多种,包括但是不限于 FocusEvent、MouseEvent、KeyboardEvent、Composition 等
基于 WebKit 的浏览器事件处理过程,首先是做 HitTest ,查找事件发生处的元素,检查该元素有无监听者。如果网页的相关节点注册了事件的监听者,那么浏览器会把事件派发给 WebKit 内核来处理。同时,浏览器也可能需要理解和处理这样的事件。这主要是因为,有些事件浏览器必须响应从而对网页作默认处理
影子(Shadow)DOM
影子 DOM 是一个新东西,主要解决了一个文档中可能需要大量交互的多个 DOM 树建立和维护各自的功能边界的问题。
当网页的开发者需要访问网页 DOM 树的时候,这些控件内部的 DOM 子树都会暴露出来,这些暴露的节点不仅可能给 DOM 树的遍历带来很多麻烦,而且也可能给 CSS 的样式选择带来问题,因为选择器无意中可能会改变这些内部节点的样式,从而导致很奇怪的控件界面。
HTML5 支持了很多新的特性,例如对视频、音频的支持,读者会发现这些元素其实是由很复杂的控制界面组成,这些界面也是使用 HTML 元素编写,但是在 DOM 树中,你无法找到相应的节点,这其实也是使用了影子 DOM 的思想。
因为影子 DOM 的子树在整个网页的 DOM 树中不可见,那么事件是如何处理的呢 ?事件中需要包含事件目标,这个目标当然不能是不可见的 DOM 节点,所以事件目标其实就是包含影子 DOM 子树的节点对象。事件捕获的逻辑没有发生变化,在影子 DOM 子树内也会继续传递。当影子 DOM 子树中的事件向上冒泡的时候, WebKit 会同时向整个文档的 DOM 上传递该事件,以避免一些很奇怪的行为。
使用shadowDOM
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<div id="div"></div>
<script>
window.onload = function(){
let adiv = document.getElementById('div');
let root = adiv.createShadowRoot();
let shadowImg = document.createElement("img");
shadowImg.src = "/render.png";
shadowImg.width= 100;
shadowImg.height= 200;
root.appendChild(shadowImg);
let shadowDiv = document.createElement('div');
shadowDiv.innerHTML = 'this is div from shadow dom!';
root.appendChild(shadowDiv);
}
</script>
</body>
</html>
网页只包含了一个 “div” 元素,JavaScript 代码使用该元素创建了一个影子 DOM 子树的根节点,然后该根节点下加入了两个子女,第一个是图片元素,第二个是 “div” 元素,该元素内部包含了一些文本。
如此解决上述问题
