创建
1、创建空的DataFrame
column = ['a','b','c']
data = pd.DataFrame(columns=column)
2、利用数组创建
'''创建一个6行4列的数组'''
data = np.random.randn(6,4)
df=pd.DataFrame(data,columns=list('ABCD'),index=[i for i in range(6)])
df

排序
pd.sort_values("xxx",inplace=True)
pd.sort_values(["1","2","3","4"],inplace=True)
处理xlsx文件
import pandas as pd
data = pd.read_excel(io = '1.xlsx')
a = data.values
data = pd.DataFrame(a, columns = [str(i) for i in range(9)])
'''此时转化为了DataFrame格式'''
边删除边遍历csv数据
一边删除一边遍历,需要删除后重新建立索引
wea= pd.read_csv(path)
for i in range(wea.shape[0]):
datee = str(wea.loc[i,'date']) #读取某一列
if():#满足某个条件
wea.drop(wea.index[i],inplace=True)
wea = wea.reset_index(drop = True) #删除后重新建立索引,否则不从0开始
也试过把索引遍历设置变量表示,跟着增加,但不如重置index方法更灵活
loc和iloc(index)
总结两个的用法:
数字代表行(因为也没有行名啊),loc指定列只能用“列名”, iloc指定列只能用数字,列的index;
import pandas as pd
import numpy as np
N = 10
D = 4
X = np.zeros((N, D))
print(X.shape[0])
for i in range(10):
for j in range(4):
X[i][j] = i+j
df = pd.DataFrame(X)
df.columns = ['1','2','3','4']
print(df.head())
#----------------------------loc------------------------------
print(df.loc[4,'1'],type(df.loc[4,'1']))
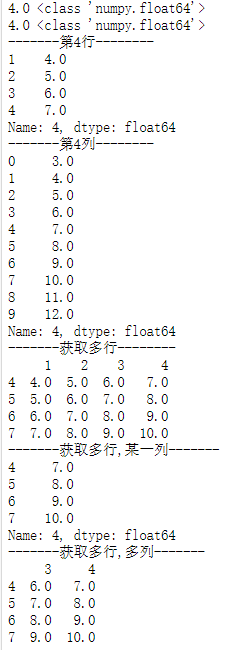
print('-------第4行--------')
print(df.loc[4])
print('-------第4列--------')
print(df.loc[:,'4'])
print('-------获取多行--------')
print(df.loc[4:7])
print('-------获取多行,某一列-------')
print(df.loc[4:7,'4'])
print('-------获取多行,多列-------')
print(df.loc[4:7,['3','4']])
#----------------------------iloc------------------------------
print(df.iloc[1][2])
print('-------第4行_1--------')
print(df.iloc[4:5],type(df.iloc[4:5]))
print('-------第4行_2--------')
print(df.iloc[4],type(df.iloc[4]))
print('-------第4列_只能通过数字索引第几列--------')
print(df.iloc[:,[3]])
print('-------某行某列一个数字--------')
print(int(df.iloc[1:2,3:4].values),type(df.iloc[1:2,3:4].values),type(int(df.iloc[1:2,3:4].values)))
print('-------多列--------')
print(df.iloc[:,3:4])
print('-------获取多行--------')
print(df.iloc[4:7])
print('-------获取多行,某一列-------')
print(df.iloc[4:7,[3]])
print('-------获取多行,多列-------')
print(df.iloc[4:7,2:4])
输出结果为:(左为loc,右为iloc)

修改
loc , iloc 都可以修改数据
print('------修改数据---------')
print(int(df.iloc[1:2,3:4].values),type(df.iloc[1:2,3:4].values),type(int(df.iloc[1:2,3:4].values)))
df.iloc[1][3] = 4.5
print(np.float64(df.iloc[1:2,3:4].values),type(df.iloc[1:2,3:4].values),type(np.float64(df.iloc[1:2,3:4].values)))
df.iloc[1]['4'] = 4.7
print(np.float64(df.iloc[1:2,3:4].values),type(df.iloc[1:2,3:4].values),type(np.float64(df.iloc[1:2,3:4].values)))
按照条件修改,速度快很多,比apply要快
index_a = df['bb'] == 15
df['rr'] = 0
df.loc[index_a,'rr'] = 1
7000000条数据修改比较速度:
条件筛选:1.5s
apply: 2.3s
插入
1、字典插入一行
row = {'imo':imo,'type_code':type_code,'age':age}
data.loc[total] = row
2、插入一列
pandas.insert(loc, columns, value):
loc要插入的位置、columns列名,value值
'''在第1列后插入一个P列'''
df.insert(1,'P',[0,1,2,3,4,5])
df
插入前后:


删除
drop(labels, axis=0, level=None, inplace=False)
lables:要删除数据的标签
axis:0表示删除行,1表示删除列,默认0
inplace:是否在当前df中执行此操作
'''删除第1,3,4行'''
df.drop([1,3,4],axis=0)
'''删除第A,D列'''
df.drop(['A','D'],axis=1)

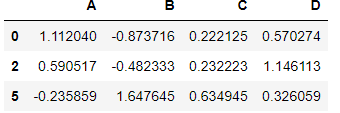
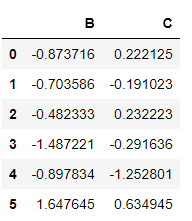
如果真的删除的话,需要重新赋值,同时要注意类型,因为有的数据类型进行增删改查等操作之后,类型发生了改变!
'''此时是在原结构上进行的删除!'''
df.drop(['A','D'],axis=1,inplace=True)
但是索引的序列不会有改变,需要重建索引
df.index = [i for i in range(df.shape[0])]
