小菜鸡使用pyspider进行的初步实战
1.启动pyspider时,直接输入pyspider,pyspider会自动创建一个新的文件夹,如果想进入以往的旧文件夹,需注意把路径cd进目标文件夹
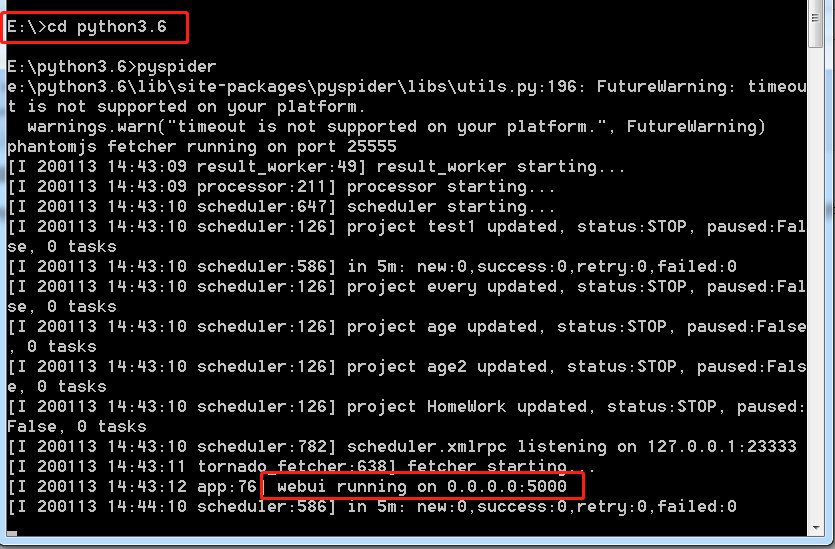
运行后出现webui running on 0.0.0.0:5000表示启动成功,Chorme输入localhost:5000即可进入。

进入之后首先要做的当然就是创建了
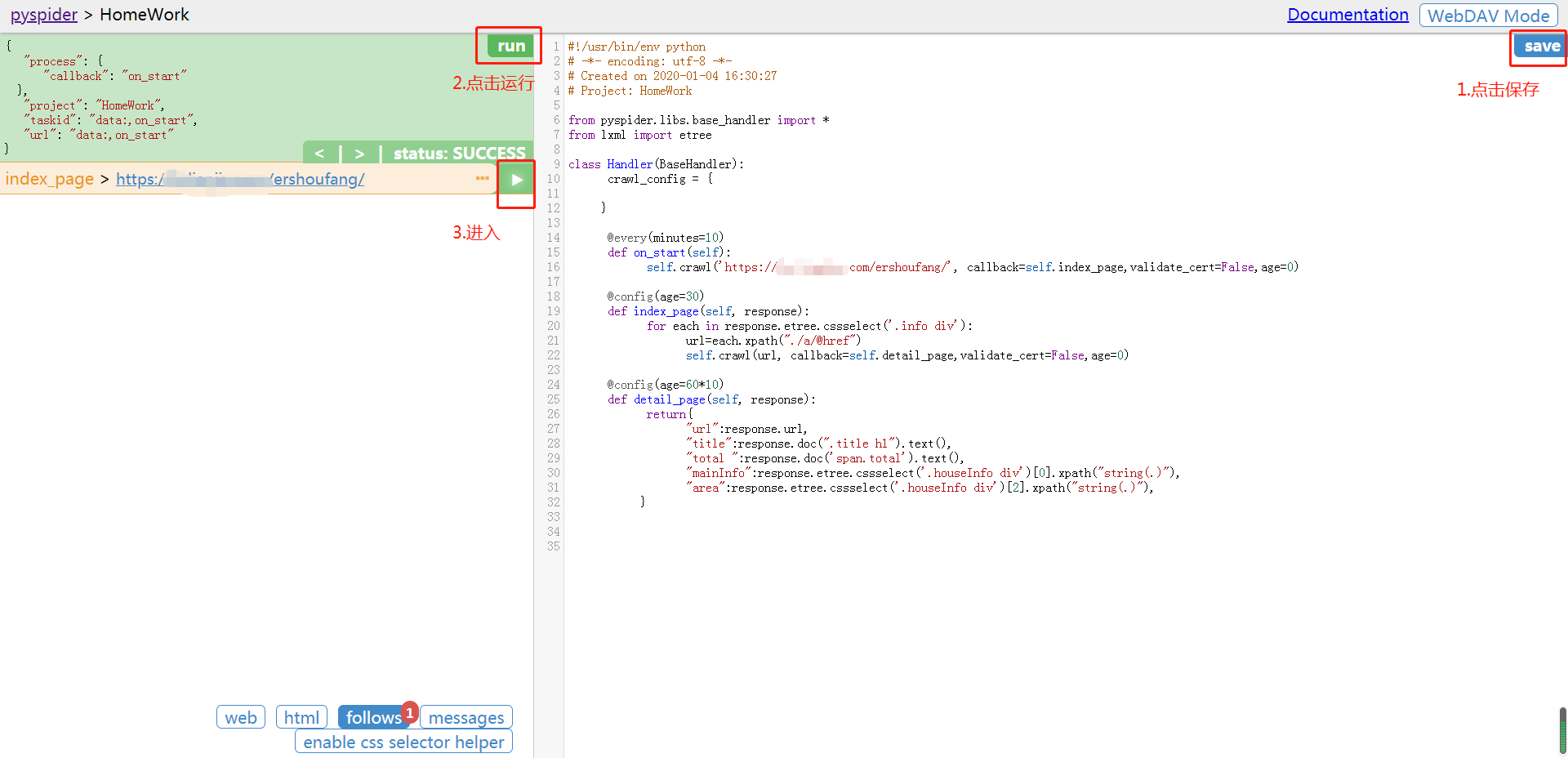
需要注意的是
for each in response.etree.cssselect('.info div'):
url=each.xpath("./a/@href")
这个地方很容易写错(小菜鸡本人就是这个地方经常错。。。手动捂脸)
个人建议:每个self.crawl中都加上validate_cert=False,age=0(反正加了也没啥损失,不加的话又容易报错,那你就加上去呗)
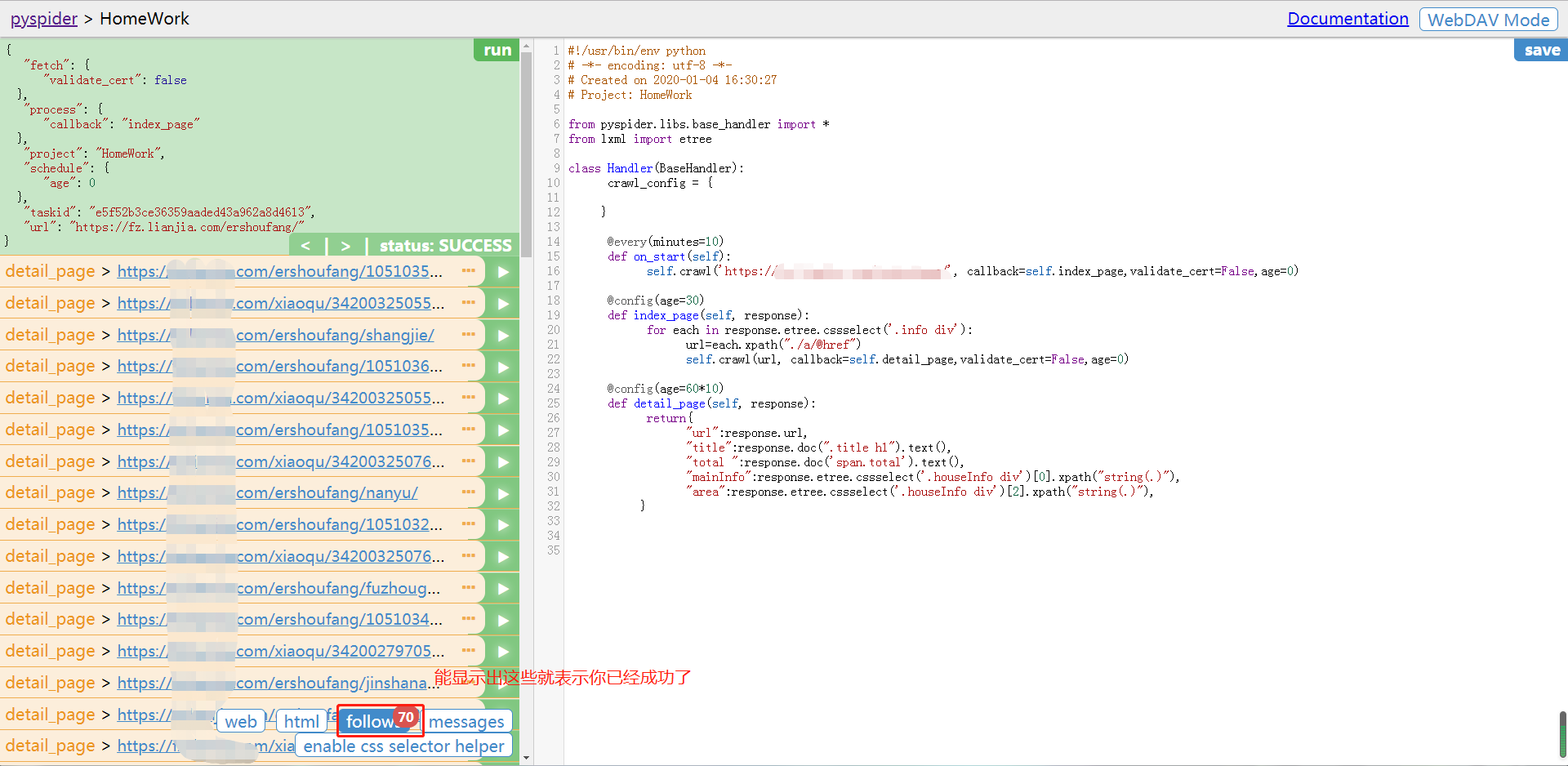
接下来我们就点击左上角的Pyspider返回到初始页面

选择完之后我们点击Run,然后你会发现cmd终端跟打了鸡血一样疯狂滚动,别担心,这是正在爬取文档
点击Active Tasks查看状态
最后我们点击Results就能成功看到我们爬取的东西了
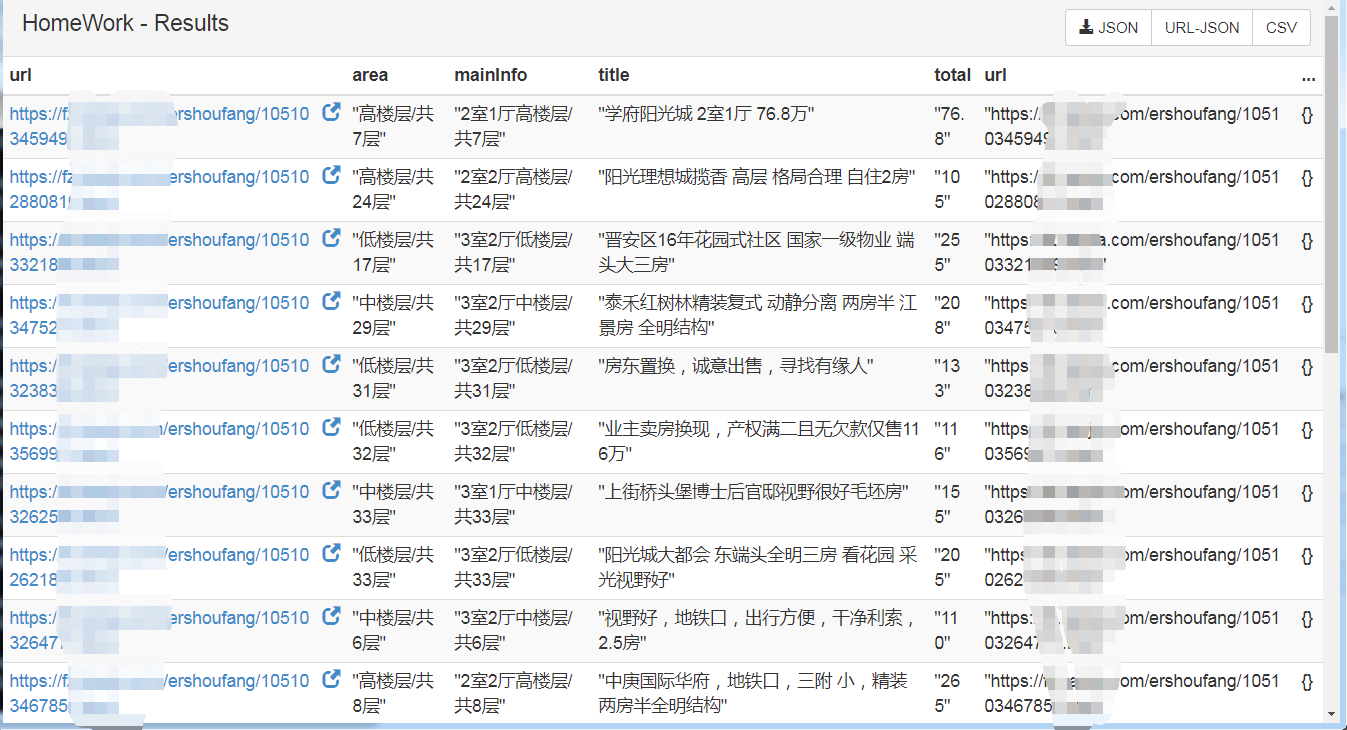
打上马赛克手动保命。咱也不知道会不会擦边,还是打上马赛克比较保险!!!
以上就是小菜鸡的pyspider第一次实战过程,简单随笔,欢迎指点