有时候需要索引很长的字符列,这会让索引变得大且慢。其中有一种策略是通过自定义哈希索引的方式来模拟哈希索引,但是这样会存在一定的局限性。通常来讲我们可以采用前缀索引的方式,这样可以大大节约索引空间,从而提高索引效率。但是与此同时,这也会一定程度上的降低索引的选择性。
索引的选择性是指,不重复的索引值(也称为基数,cardinality)和数据表的记录总数(#T)的比值,范围从1/#T到1之间。索引的选择性越高则查询效率越高,因为选择性高的索引可以让MySQL在查找时过滤掉更多的行。当然显而易见,唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
因此我们要采用前缀索引的关键则是,对于前缀索引的长度的选择,以保证其较高的选择性,但同时又不能太长(有违选择前缀索引的初衷)。总而言之,前缀应该足够长,以使得前缀索引的选择性接近于索引整个列。换句话说,前缀的"基数"应该接近于完整列的"基数"。
假设我们现在有一个city城市表,其中包含了city字段表示城市名称。

现在需要为该字段添加前缀索引,接下来演示一下如何选取最佳前缀索引长度的方法。
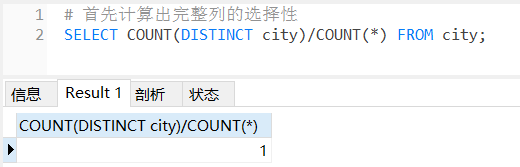
通过观察我们能够发现,完整列的选择性为1。
那么通常来说,在这个例子当中,我们所选取的前缀的选择性能够接近1,基本上就可以用了。可以在一个查询中针对不同前缀长度进行计算,这对于大表非常有用。下面将展示如何在同一个查询当中计算不同前缀长度的选择性:

通过观察我们可以看出,当前缀长度达到3时,其选择性便与完整列的选择性相同均为1,那么粗略的来说,我们可以认为在当前数据的背景条件下,前缀索引长度选取为3是最佳的。
以上便演示了在创建前缀索引时,如何确定最佳前缀索引长度的过程,但是仅供理解,不具备实战意义。
接下来补充说明一下关于具体选取前缀索引长度当中的"陷阱":
首先来分析,当我们通过上述的方法依次的得到了多个不同长度前缀的选择性,那么接下来我们需要做的事情便是从中选取出最合适的长度,既要满足与完整列的选择性非常接近,又要满足前缀长度不能过长。在这个模棱两可的抉择点,有时我们需要注意这种问题,由于在上述的方法当中,我们仅仅看到的是平均情况下的选择性,并未看到最坏情况下的选择性,我们在最终确定前缀长度时需要考虑到最坏情况下的选择性。这是由于当数据分布很不均匀的情况下,可能就会出现问题。
上面的描述可能有些抽象,这里再次简单的描述一下陷阱出现的关键原因,即:当我们分析计算得出的前缀索引选项性时只是以全局、平均的角度来分析该选择性,而并未考虑到极端情况下的问题。举个栗子,比如在一张表格当中,我们完整列的选择性为0.319,通过分析我们得到前缀长度为6和7情况下的选择性依次为:sel6=0.312,sel7=0.313,那么我们通过简单的对该数据进行分析,考虑到存储代价,可能会选取前缀索引长度为6作为我们最终的前缀索引长度。但是会存在这样一种情况,当前缀长度为6时,其不足的选择性正是由于极端数据的情况所导致的,而这种情况只会影响少部分前缀查询性能问题,并不会影响总体的查询性能问题。对于这种特殊情况,也应该作为我们考虑的因素。
那么我们应该如何判断有无极端情况的问题呢?答案当然是有的,我们可以通过以下办法来参考判断:

若通过比对后发现,并无明显数据分布极其不均匀现象,那么则说明平均选择性对于实际数据情况具备较强的参考性。
