首先说明ElasticSearch版本号5.5.2
目录介绍
- bin目录 存放es启动脚本
- config目录 存放es配置文件
- lib目录 第三方库依赖库
- modules 模块目录
- plugins 存放第三方插件目录
安装集群
master节点配置
cluster.name: wali
node.name: master
node.master: true
network.host: 127.0.0.1
slave1节点配置
cluster.name: wali
node.name: slave1
network.host: 127.0.0.1
http.port: 8200
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
slave2节点配置
cluster.name: wali
node.name: slave2
network.host: 127.0.0.1
http.port: 8000
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
电脑配置不行可以修改jvm.options
-Xms1g
-Xmx1g
基础概念
- 集群和节点 集群是一个或多个节点组成的集合
- 索引 含有相同属性的文档集合
- 类型 索引可以定义一个或多个类型, 文档必须属于一个类型
- 文档 文档是可以被索引的基本数据单位
- 分片 每个索引都有多个分片,每个分片是一个Lucene索引
- 备份 拷贝一份分片就完成了分片备份
基本用法
RESTful API
API基本格式 http://<ip>:<port>/<索引>/<类型><文档id>
常用HTTP动词 GET/PUT/POST/DELETE
创建索引


分片数默认为5,副本数默认1(如果只有一台机器设置为0)
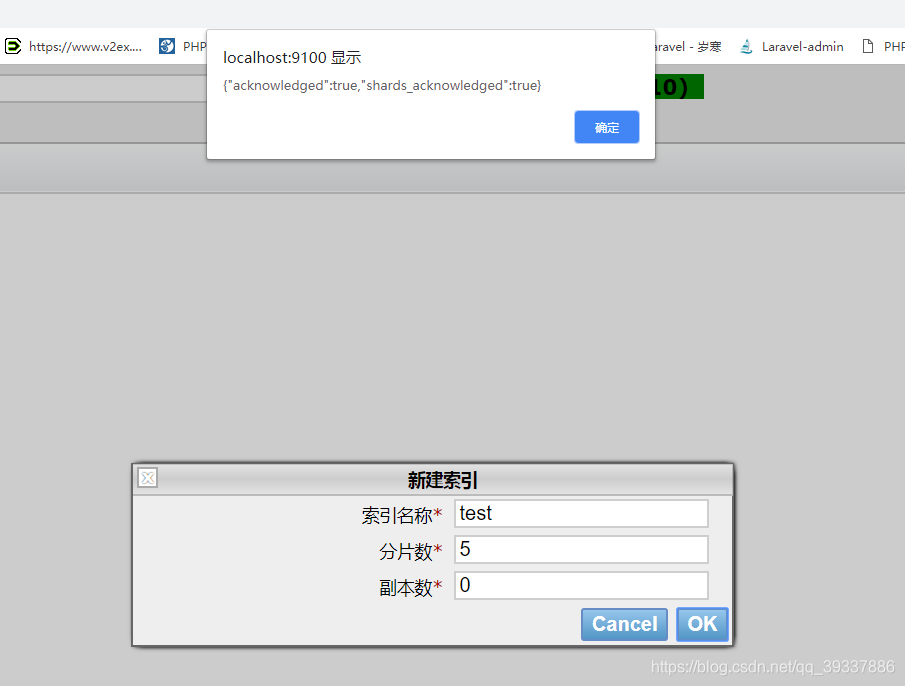
创建结果如下,mapping为空标识 非结构化索引

创建结构化索引
{
"novel": {
"properties": {
"title": {
"type": "text"
}
}
}
}
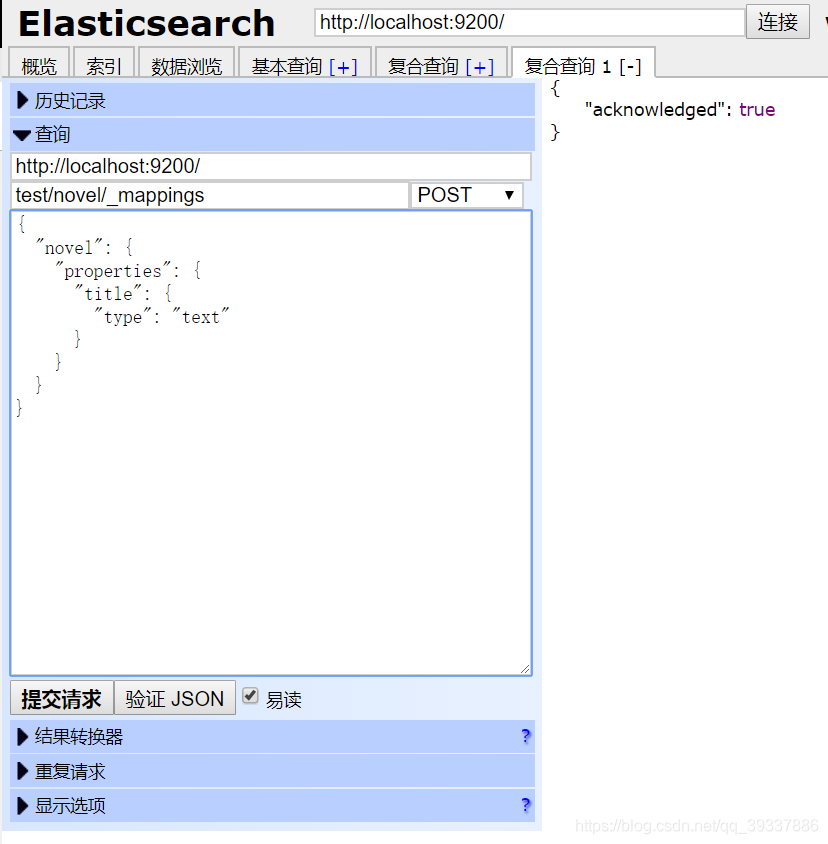
前往查看效果如下:

通过postman创建索引
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0
},
"mappings": {
"man": {
"properties": {
"name": {
"type": "text"
},
"country": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"date": {
"type": "date",
"format": "yyy-MM--dd HH:mm:ss||yyy-MM-dd||epoch_millis"
}
}
},
"woman": {
"properties": {
"name": {
"type": "text"
},
"country": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"date": {
"type": "date",
"format": "yyy-MM--dd HH:mm:ss||yyy-MM-dd||epoch_millis"
}
}
}
}
}
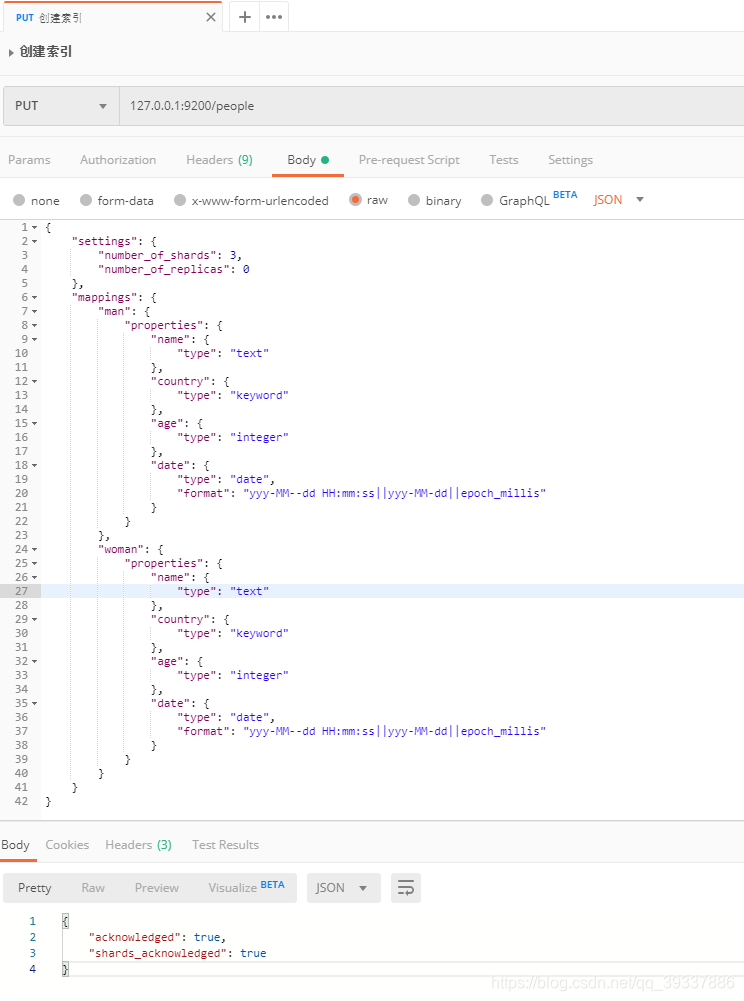
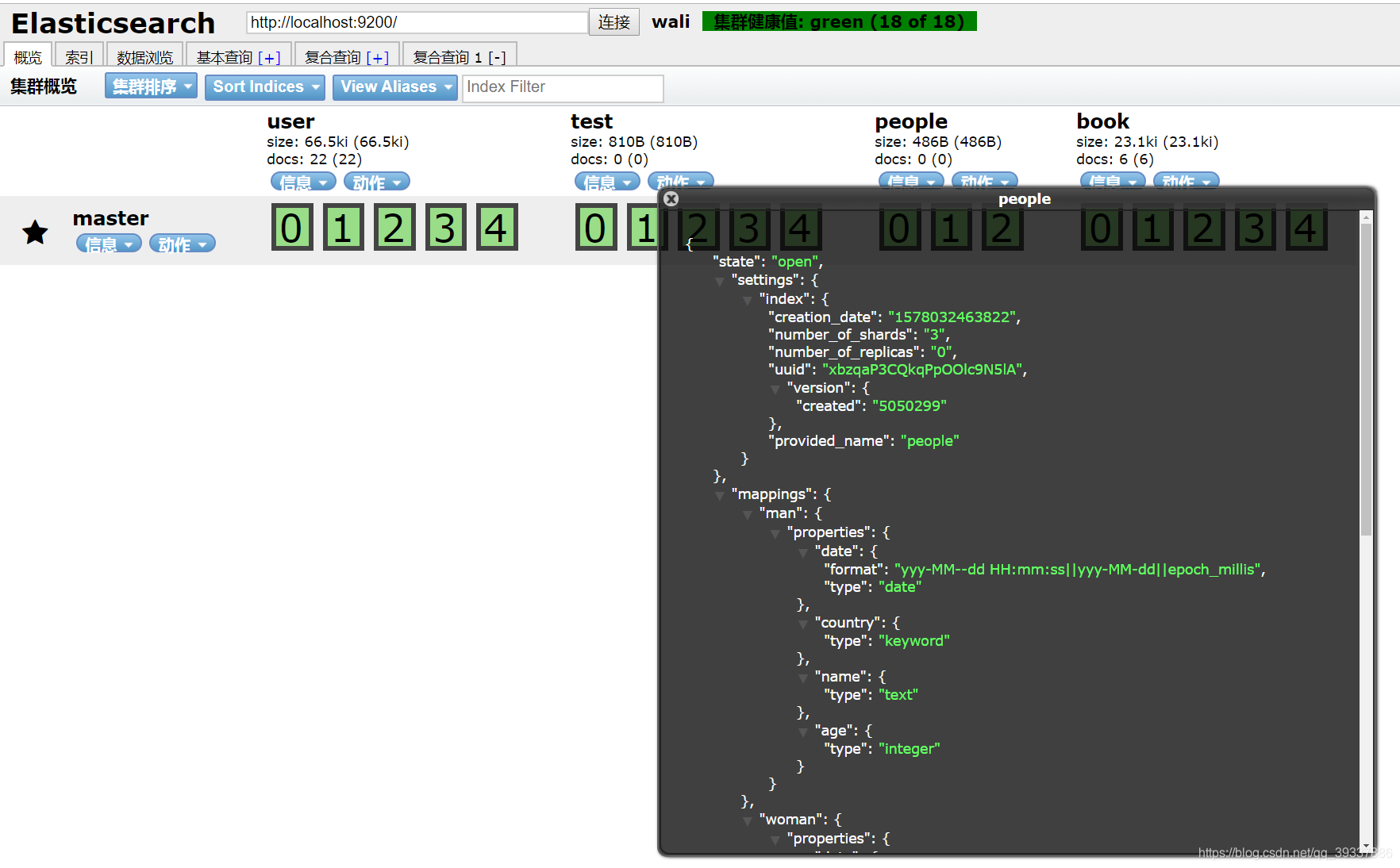
插入文档
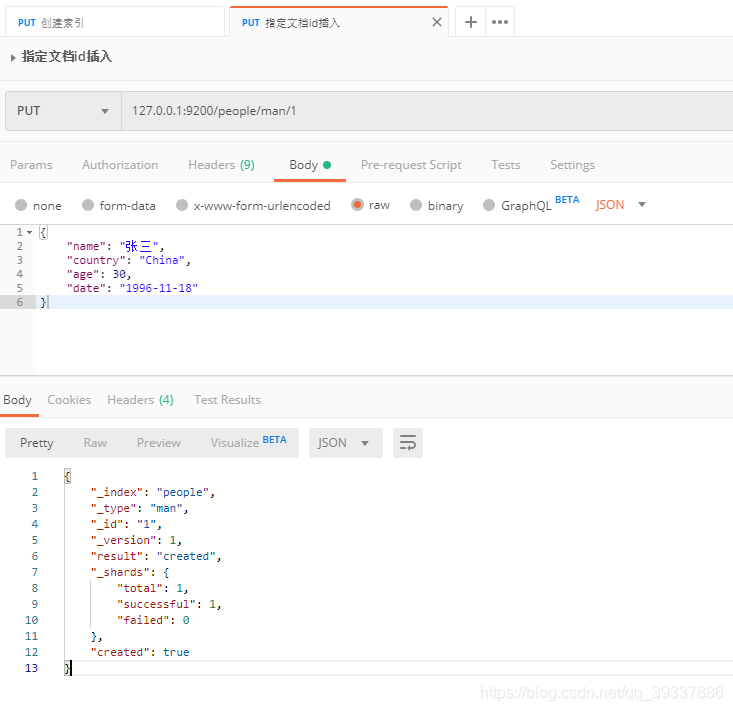
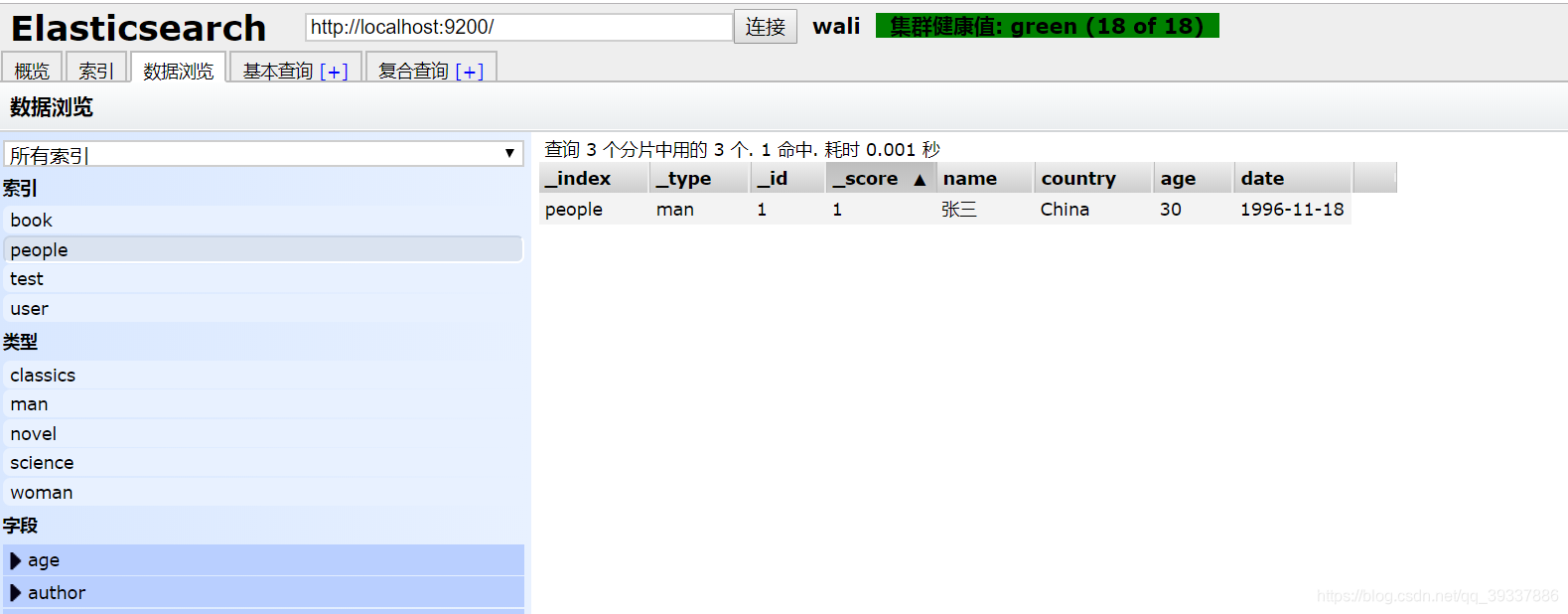
指定文档id插入
{
"name": "张三",
"country": "China",
"age": 30,
"date": "1996-11-18"
}
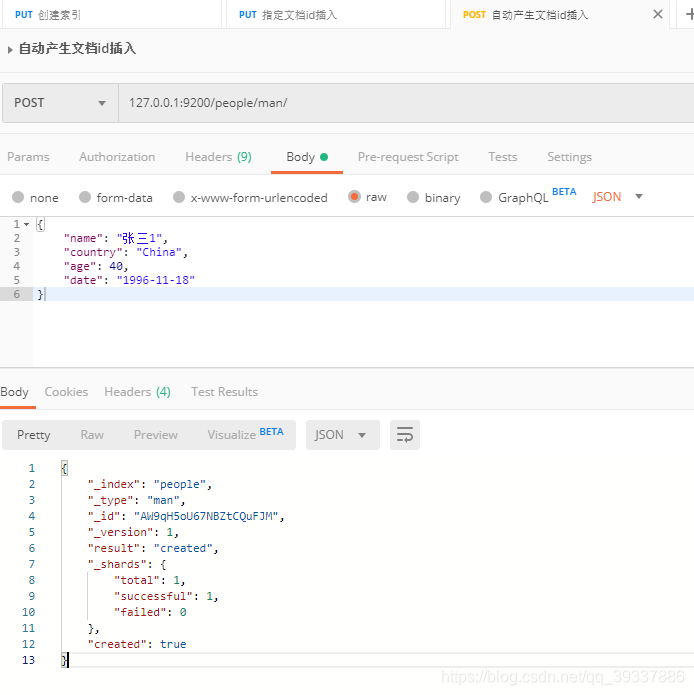
自动产生文档id插入
{
"name": "张三1",
"country": "China",
"age": 40,
"date": "1996-11-18"
}

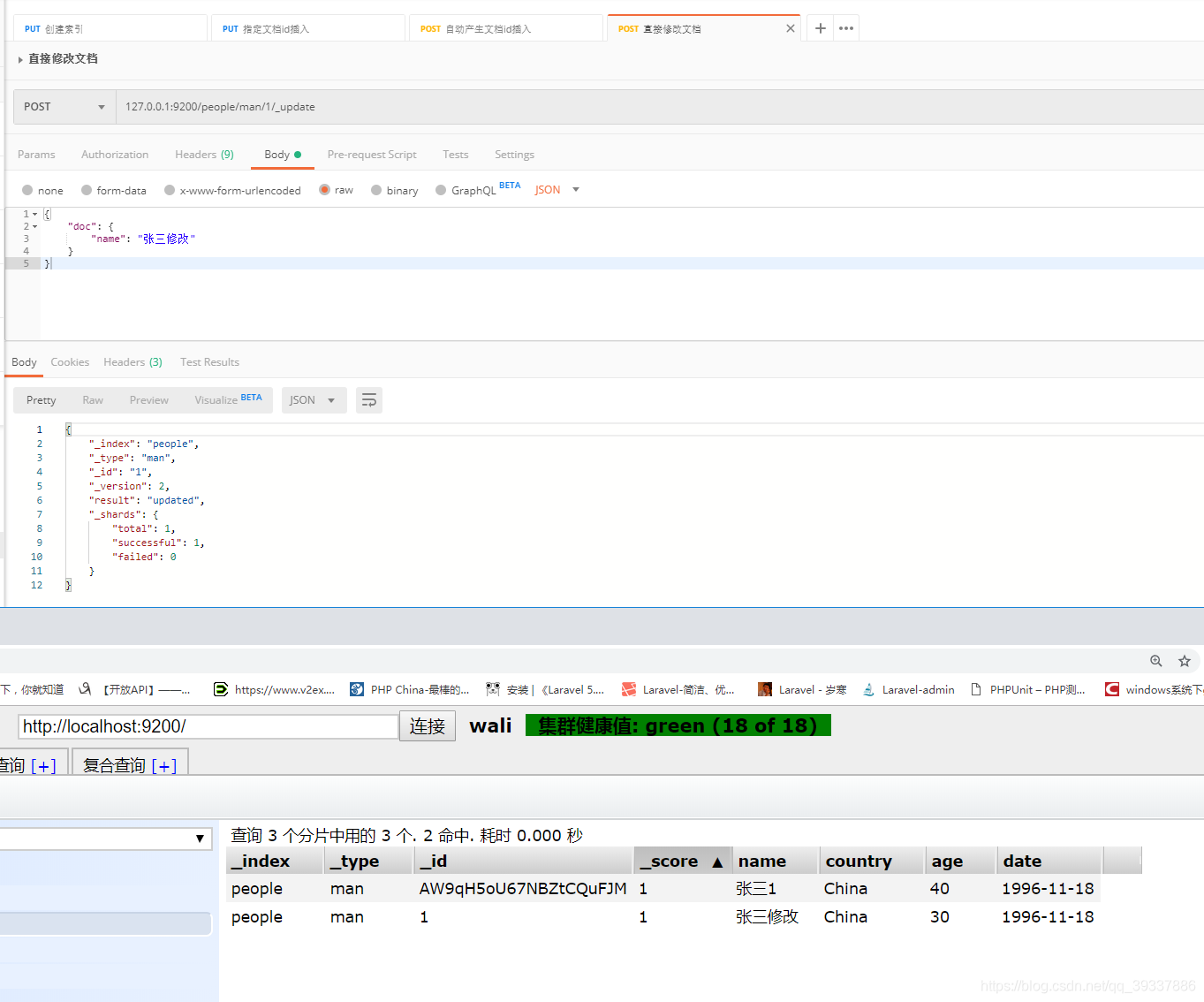
修改文档
直接修改文档
127.0.0.1:9200/people/man/1/_update
{
"doc": {
"name": "张三修改"
}
}
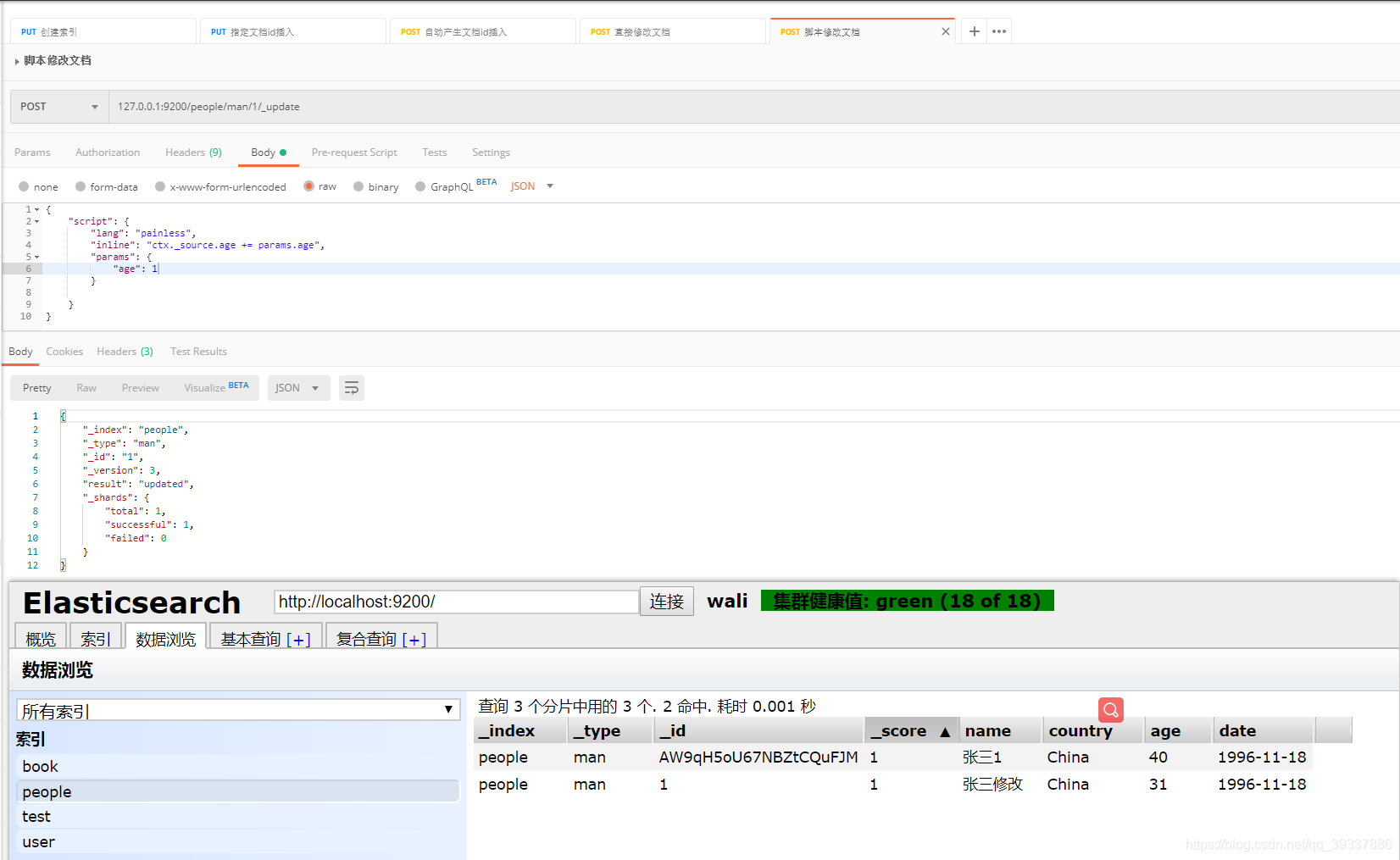
脚本修改文档
127.0.0.1:9200/people/man/1/_update
{
"script": {
"lang": "painless",
"inline": "ctx._source.age += params.age",
"params": {
"age": 1
}
}
}
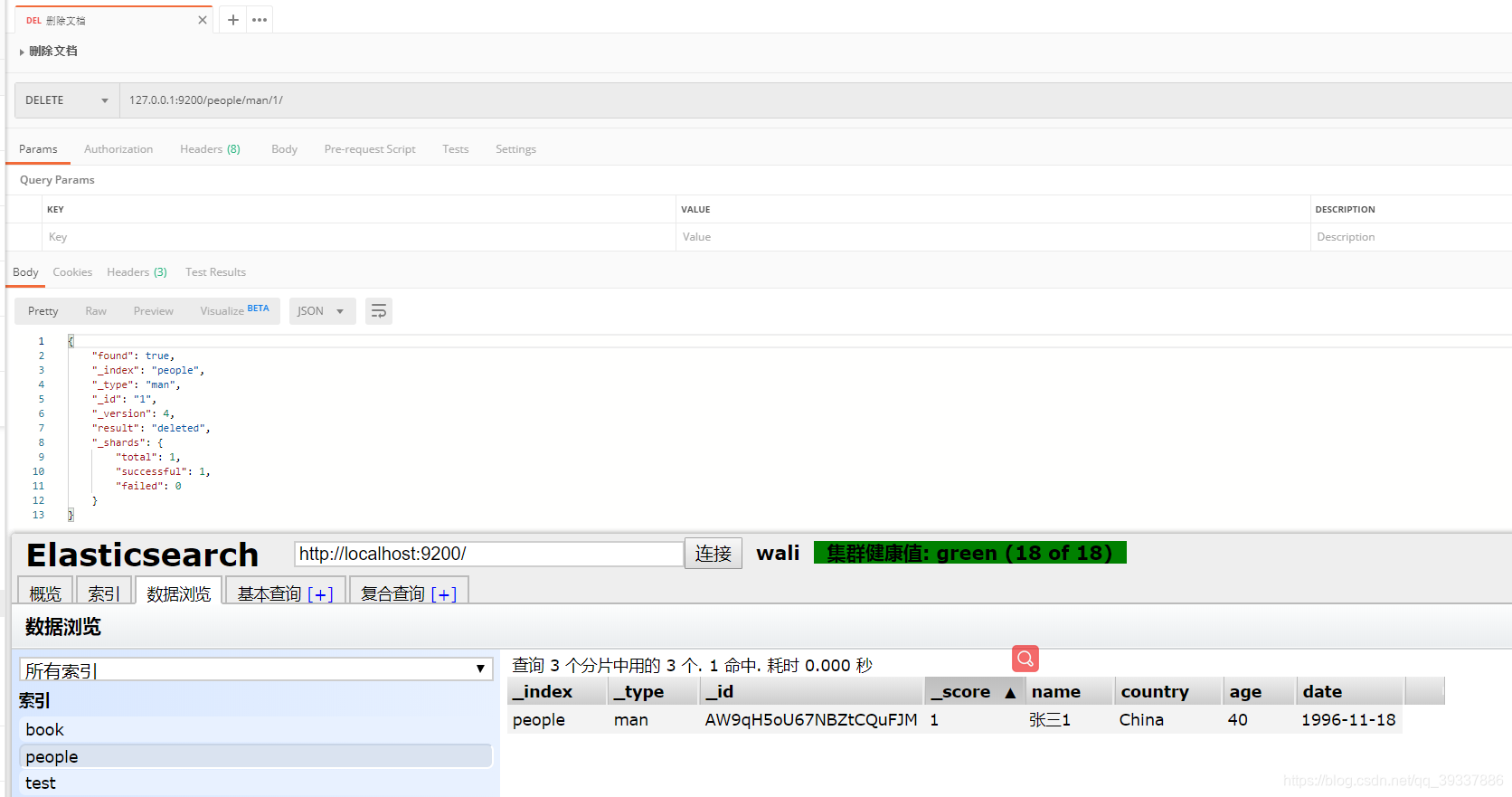
删除
删除文档
127.0.0.1:9200/people/man/1/
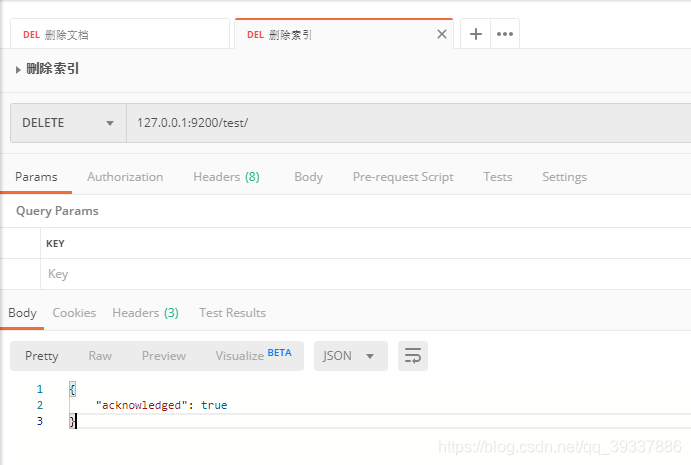
删除索引
127.0.0.1:9200/test/
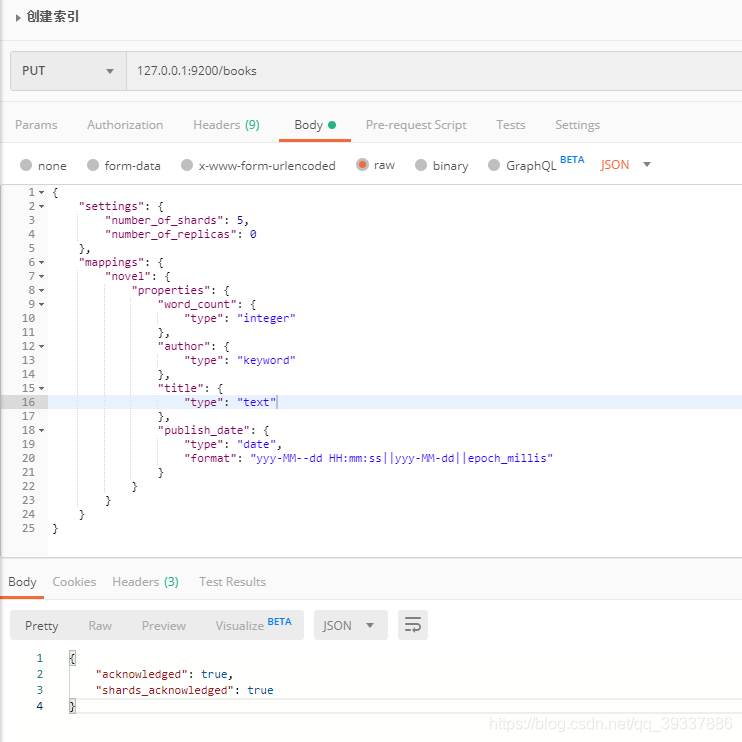
搜索
创建搜索

127.0.0.1:9200/books
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 0
},
"mappings": {
"novel": {
"properties": {
"word_count": {
"type": "integer"
},
"author": {
"type": "keyword"
},
"title": {
"type": "text"
},
"publish_date": {
"type": "date",
"format": "yyy-MM--dd HH:mm:ss||yyy-MM-dd||epoch_millis"
}
}
}
}
}
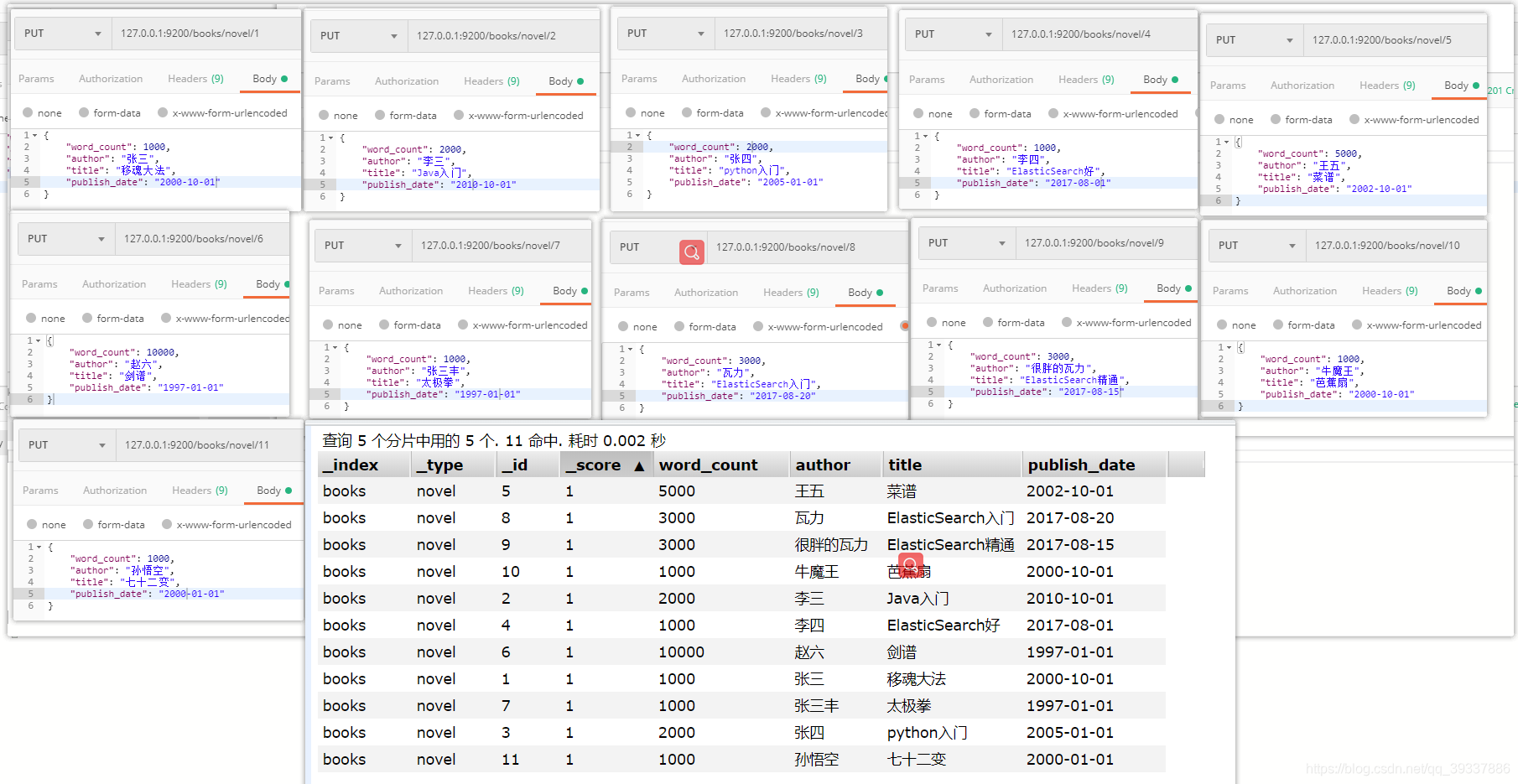
按照指定文档Id查询

搜索条件
took响应时间5ms
hits响应的结果
total总共数据11条。默认只返回10条

添加新的条件 size返回条数
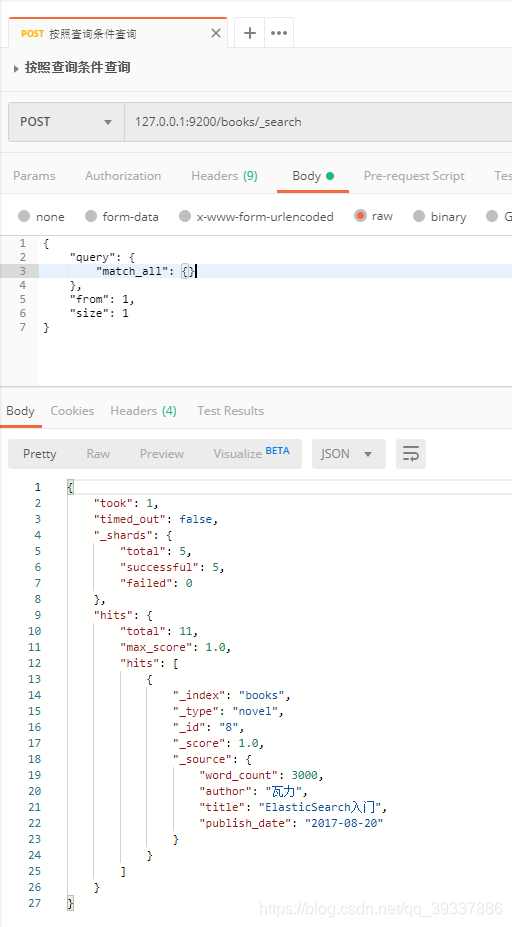
查找title中有ElasticSearch,返回数据默认以_score倒排
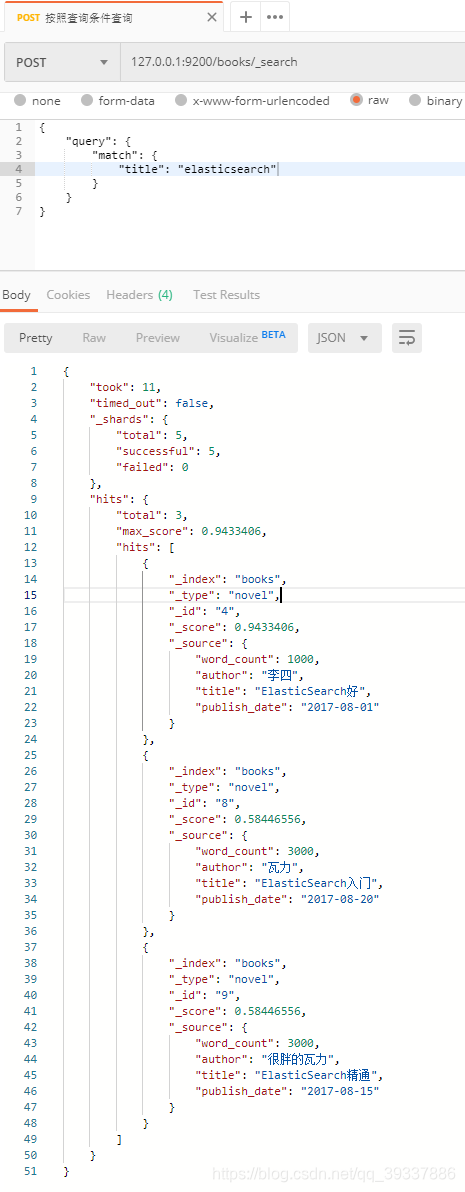
添加自己的排序,按照publish_date降序排列
聚合查询
group_by_word_count随便起名字

查询结果,1000的有5个
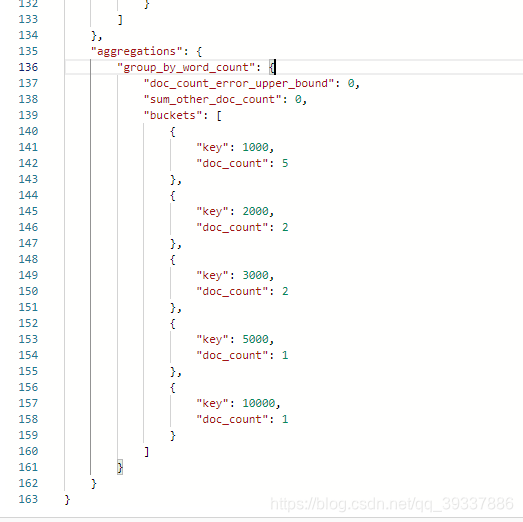
两个聚合条件
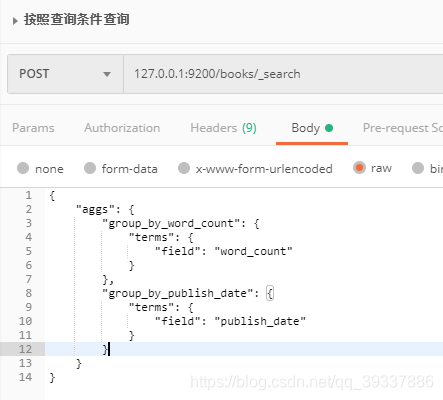
查询结果 group_by_word_count和上面一样,另一个是 1997-01-01有2条数据

对word_count进行计算
127.0.0.1:9200/books/_search
POST
{
"aggs": {
"grades_word_count": {
"stats": {
"field": "word_count"
}
}
}
}
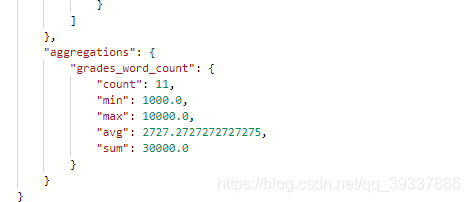
count总共11条,min最小,max最大,avg平均,sum总和
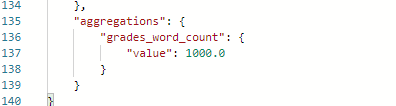
也可以直接将stats改为min
{
"aggs": {
"grades_word_count": {
"min": {
"field": "word_count"
}
}
}
}
运行结果如下
高级查询
子条件查询 特定字段查询所指特定值
Query Context
在查询过程中,除了判断文档是否满足查询条件外,ES还会计算一个_score来表示匹配的程度,旨在判断目标文档和查询条件匹配的有多好。
全文本查询 针对文本类型数据
数据展示
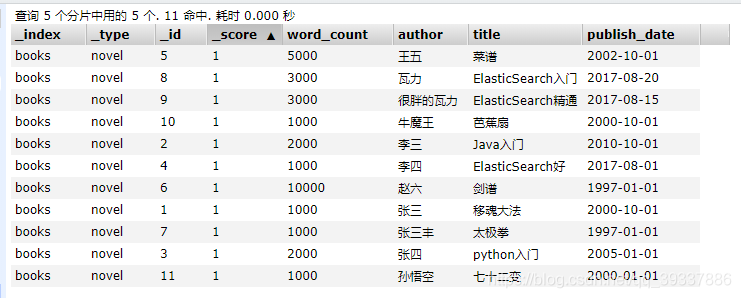
模糊匹配关键词match
搜索author为瓦力
POST请求方式
127.0.0.1:9200/books/_search
{
"query": {
"match": {
"author": "瓦力"
}
}
}

把上面条件进行修改如下,它会匹配ElasticSearch和入门这两个,所以返回上面熟的id为8,2,3,4,9的数据(结果太长截图不好看)
{
"query": {
"match": {
"title": "ElasticSearch入门"
}
}
}
如果非要匹配title为ElasticSearch入门,则需要用到习语匹配,返回数据只剩下一条满足的id为8
{
"query": {
"match_phrase": {
"title": "ElasticSearch入门"
}
}
}
进行多个字段的匹配查询,由于上面数据中title和author没有公共的,随意改一个就行
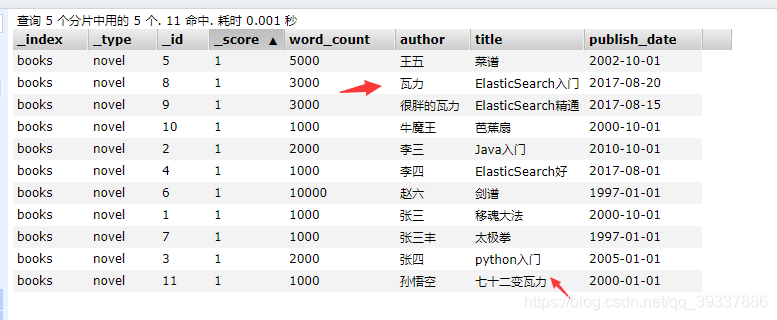
查询代码如下
POST方式
127.0.0.1:9200/books/_search
{
"query": {
"multi_match": {
"query": "瓦力",
"fields": ["author","title"]
}
}
}
语法查询
查询结果是id为4 和 3
如果把括号和OR Python去掉查询结果为4
POST方式
127.0.0.1:9200/books/_search
{
"query": {
"query_string": {
"query": "(ElasticSearch AND 好) OR Python"
}
}
}
指定字段查询,查询结果Id为8,11,4,9
POST方式
127.0.0.1:9200/books/_search
{
"query": {
"query_string": {
"query": "ElasticSearch OR 瓦力",
"fields": ["author","title"]
}
}
}
字段级别查询 针对结构化数据,如数字、日期等
查询word_count为1000的数据,查询结果id为10,4,1,7,11
POST方式
127.0.0.1:9200/books/_search
{
"query": {
"term": {
"word_count": 1000
}
}
}
查询author为瓦力,查询结果id为8
POST方式
127.0.0.1:9200/books/_search
{
"query": {
"term": {
"author": "瓦力"
}
}
}
支持范围查询,查询word_count,大于等于1000小于等于2000,查询结果id为10,2,4,1,7,3,11
去掉e相当于少了等于
POST方式
127.0.0.1:9200/books/_search
{
"query": {
"range": {
"word_count": {
"gte": 1000,
"lte": 2000
}
}
}
}
查询日期,2000-01-01到2000-12-31书籍,查询结果id为10,1,11
POST方式
127.0.0.1:9200/books/_search
{
"query": {
"range": {
"publish_date": {
"gte": "2000-01-01",
"lte": "2000-12-31"
}
}
}
}
查询日期,2017-08-15到现在书籍,查询结果id为8,9
POST方式
127.0.0.1:9200/books/_search
{
"query": {
"range": {
"publish_date": {
"gte": "2017-08-15",
"lte": "now"
}
}
}
}
Filter Context
在查询过程中,值判断该文档是否满足条件,只有Yes或No
相对于query较快,es会对数据进行缓存
POST
127.0.0.1:9200/books/_search
{
"query": {
"bool": {
"filter": {
"term": {
"word_count": 10000
}
}
}
}
}
复合条件查询 以一定的逻辑组合子条件查询
固定分数查询
只支持filter,返回_score为1.0,boost指定_score的值
POST
127.0.0.1:9200/books/_search
{
"query": {
"constant_score": {
"filter": {
"match": {
"title": "ElasticSearch"
}
}
}
}
}
{
"query": {
"constant_score": {
"filter": {
"match": {
"title": "ElasticSearch"
}
},
"boost": 2
}
}
}
布尔查询
里面条件是或的关系,只要满足一个就行。查询结果id为8,4,9
POST
127.0.0.1:9200/books/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"author": "瓦力"
}
},
{
"match": {
"title": "ElasticSearch"
}
}
]
}
}
}
查询前添加了一条数据
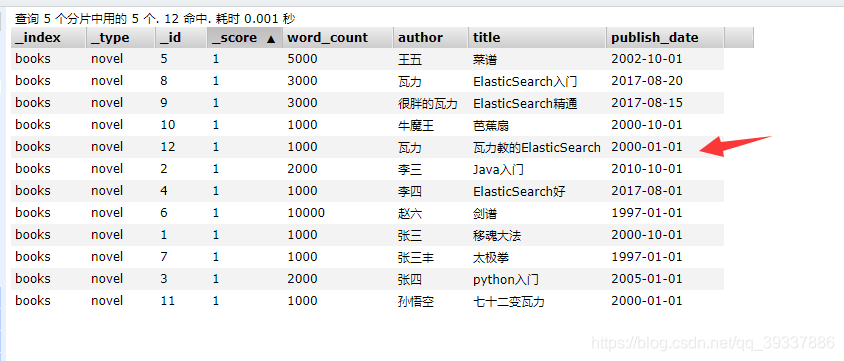
里面条件是并且的关系,查询结果id为8,12
POST
127.0.0.1:9200/books/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"author": "瓦力"
}
},
{
"match": {
"title": "ElasticSearch"
}
}
]
}
}
}
上面条件再加一个word_count条件,查询结果id为12
POST
127.0.0.1:9200/books/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"author": "瓦力"
}
},
{
"match": {
"title": "ElasticSearch"
}
}
],
"filter": [
{
"term": {
"word_count": 1000
}
}
]
}
}
}
mast_not不满足条件的结果,查询结果id为5,9,10,2,4,6,1,7,3,11
POST
127.0.0.1:9200/books/_search
{
"query": {
"bool": {
"must_not": [
{
"term": {
"author": "瓦力"
}
}
]
}
}
}
