1.头脑风暴+代码重写一遍(见github的SortRewrite)
排序分为两种:内部排序——只用内存。和外部排序——占用外部空间,如磁盘,其实外部排序的内部用的还是内部排序。
[补:元素过多,数据量过大,内存放不下时,可能需要借助外部存储器。
线性排序O(n):桶,基数,计数]
排序需要考虑:时间复杂度、(最好、最坏、平均)空间复杂度、稳定性(值相等的元素的前后顺序有无改变)、如何优化这四个问题。
[原先讨论时间复杂度时,数据规模n很大,表示时会忽略系数、常数、低阶,但实际软件开发中,排序的可能是10个、100个、1000个这样规模很小的数据,依次对于同一阶时间复杂度的排序算法性能对比时,需要考虑系数、常数和低阶。]
冒泡排序
以升序为例,“冒泡”就是轻(小)的会浮上来,重(大)的会沉到底,冒泡是两两之间的比较,比如:3,7,5,1,8,4。从头开始遍历,3比7小,不变,7比5大,需要交换俩元素,数组变为3,5,7,1,8,4;7比1大,需要交换,数组变为3,5,1,7,8,4;7比8小,不变,8比4大,需要交换俩元素,数组变为3,5,1,7,4,8。第一趟下来,最大的。因为是从头往后遍历,大的给后放,所以一趟下来总会有个大的元素到它正确的位置。
[补:冒泡排序只会操作相邻的两个数据。]
代码如下:
package Java;
//冒泡排序
public class BobbleSort {
public void sort(int[] data)
{
for(int i=0;i<data.length;i++)
{
for(int j=0;j<data.length-i-1;j++)
{
if(data[j]>data[j+1]) swap(data,j,j+1);
}
}
}
public void swap(int[]data,int a,int b)
{ int temp=data[a];
data[a]=data[b];
data[b]=temp; }
}
时间复杂度:最好/坏 情况/平均:O(n^2)
[改:最好:要排序的数据已经是有序的了,O(n)]
空间复杂度:没有额外开辟空间O(1).原地排序。
稳定性:写的代码是如果data[j]>data[j+1]才交换,小于等于的情况是不交换的,因此是稳定的。
如何优化:如果当前元素已经有序,不必再遍历,可以减少循环次数。可以设置标志位判断当前是否有序。代码如下:
package Java;
//冒泡排序
public class BobbleSort {
public void sort(int[] data)
{
//优化:设置标志位,如果当前数组已有序,不需要再遍历
for(int i=0;i<data.length;i++)
{boolean flag=false;
for(int j=0;j<data.length-i-1;j++)
{
if(data[j]>data[j+1])
{ swap(data,j,j+1);
flag=true;}
}
if(flag==false){
System.out.println("当前数组已有序,第"+i+"个位置");
break;
}
}}
public void swap(int[]data,int a,int b)
{ int temp=data[a];
data[a]=data[b];
data[b]=temp; }
}
插入排序
“插入”排序,需要联想到往一个已经有序(升序)的数组中插入元素。我们可以从后向前遍历这个有序数组,将待插入元素与数组中元素比较,如果待插入元素比已有序元素小,那么已有序元素需要往后移一位,腾出位置,如果待插入元素比已有序元素大,那么不需要再向前遍历了,待插入元素一定比前面的元素都大。这时将它放入正确的位置即可。
[补:核心思想:数据分为已排序区和未排序区。]
(1)直接插入
代码如下:
package Java;
//直接插入
//联想向一个已有序的数组插入元素
//最初数组第一个元素默认有序
public class DirectInsertition {
public void sort(int[] data)
{
//已排序末,默认初始为0
int already=0;
while (already<data.length-1)
{
//already+1为未排序元素区首,将该元素与已排序区从后之前比较
int j=already;
int value=data[already+1];
for(;j>=0;j--) {
if (value < data[j])
//如果未排序区首元素小于已排序区元素,已排序区元素需要往后挪一位腾出位置
{data[j+1]=data[j];}
else {break;}
}
data[j+1]=value;
already++;
}
}
}
时间复杂度:最好情况:O(n),(数组本身就是有序的了,内层循环只break)
最坏情况/平均:O(n^2)
[补:最坏情况:本身倒序。]
空间复杂度:没有开辟额外空间。O(1),原地排序。
稳定性:写的代码中,如果(value < data[j]),元素需要向后挪,如果(value >=data[j])是不需要挪动的,因此是稳定的。
如何优化:折半插入。
(2)折半插入
直接插入,在寻找当前元素插入的位置时,是对已排序区从后往前遍历(这样一来,如果当前元素小于已排序区元素,已排序区元素需要向后挪一位腾位置),为提高效率,考虑折半比较,第一次取数组长度的中间,因为已经是有序数组,如果当前元素小于中间元素,说明当前元素的插入位置在中间位置的左边,反之在右边。可以设置left,right,mid。递归调用,终止条件是什么呢?通过分析几个数组发现:要想确定插入位置,一定会经历一个left=right=mid的阶段(三个指针重合),接下来,会发现待插入元素小于mid,(不可能是大于mid的,如果大于mid是不会落在这一区间的)right=mid-1,那么left会大于right,即left>right,这时,只需要比较mid对应的元素和待插入元素,如果mid对应的元素大于待插入元素待插入元素应放在mid的前面;反之放后面。
(注意!!!写递归终止条件时注意边界情况,比如这里的right=-1会导致返回的插入位置值为-1,因此需要单独判断.)
代码如下:
package Java.InsertSort;
//折半插入
//递归调用
public class BinaryInsertionSort {
//传入已排序数组的末下标,返回正确位置
public int solution(int[] data,int already)
{ int left=0;
int right=already;
while (true)
{int save=data[already+1];
int mid=(left+right)/2;
// if(right==-1) return mid;
if(left>right){
if(data[mid]<save) return mid+1;
else return mid-1; }
if(data[mid]<save) left=mid+1;
else right=mid-1;
}}
public void sort(int[] data)
{
for(int i=1;i<data.length;i++)
{ int save=data[i];
int solution=solution(data,i-1);
for(int j=i-1;j>=solution;j--)
{
data[j+1]=data[j];
}
data[solution]=save;
}
}
}
时间复杂度:O(nlgn)
空间复杂度:O(1),没有额外开辟空间。
[改:时间、空间、稳定性均与直接插入排序相同,只是元素比较次数不同而已。]
(3)希尔排序
希尔排序又叫“缩小增量排序”,
以{1,22,8,4,2,7,18,12}为例,数组长度为8,首先增量gap=8/2=4,每次走4步,会得到{1,2},{22,7}{8,18},{4,12}四组,对这四组元素依次做插入排序,得到:{1,2},{7,22},{8,18},{4,12}(是需要在原数组上交换位置的),原数组变成{1,7,8,4,2,22,18,12}。
接下来缩小增量,gap=gap/2=2,每次走两步,得到{1,8,2,18},{7,4,22,12},对这两组元素依次做插入排序,得到:{1,2,8,18},{4,7,12,22},原数组变成{1,4,2,7,8,12,18,22}.
再缩小增量,gap=gap/2=1,每次走一步,得到即对{1,4,2,7,8,12,18,22}进行插入排序即可。
[补:可以自定义一个增量序列,不一定每次折半。]
代码如下:
package Java.InsertSort;
//希尔排序
public class ShellSort {
public void sort(int[] data)
{ int gap=data.length/2;
while(gap>=1)
{
//根据普通插入排序的思想,数组第一个元素默认为初始已排序区
//i从gap开始遍历,正好是未排序区第一个元素,
// 仍是插入排序,注意该组元素下标的跨度即可
for(int i=gap;i<data.length;i++)
{
int save=data[i];
//遍历已排序区
int j=i-gap;
for(;j>=0;j=j-gap)
{
if(save<data[j])
{ data[j+gap]=data[j]; }
else {break;}
}
data[j+gap]=save;
}
gap=gap/2;
}
}
}
时间复杂度:
最好:已经是有序数组:n(lg2)
最坏:倒序数组O(nlgn)
平均:O(nlgn)
空间复杂度:没有额外空间,原地排序O(1)。
稳定性:相等情况下不操作,稳定。
[改:时间复杂度:
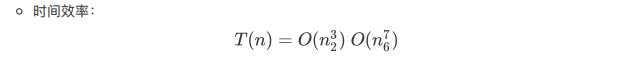
??? 不懂。
]
仍是插入排序,不过有分组,注意该组下标的跨度即可。
归并排序
归并排序,(升序)先分解,后合并。
以{1,5,3,2,7,4,11,8}为例,先分解成{1,5,3,2}和{7,4,11,8},再进行分解,分解成{1,5},{3,2},{7,4},{11,8},再进行分解,分解成{1},{5},{3},{2},{7},{4},{11},{8},
分解至变成一个元素一个元素的小数组后,开始进行合并,
先将{1}和{5}合并,需要开辟一个新的空间——长度为2的数组,遍历两个小数组,并放入合并结果数组中,结果为{1,5},同理,得到结果数组{2,3},{4,7},{8,11},再进行合并,开辟长度为4的数组空间,结果为{1,2,3,5}和{4,7,8,11},再进行合并,得到{1,2,3,4,5,7,8,11}排序完成。
分解可以用递归实现。可以这样想:传入的参数是数组,left和right,比如上面的例子,left=0,right=7,先计算分解点:int mid=(0+7)/2=3,然后继续进行分解,传入
a.0和mid(3),
b.mid+1(4)和right(7),
递归调用,传入a,会得到新的mid=1,这时可以对下标为0与下标为1的元素、下标为2与下标为3的元素开始合并了,调用写好的合并方法:merge(data,left,right)。即可完成第一次合并;接下来,再递归调用分解方法,就该是终止了,此时mid变为(0+1)/2=0,这时传入的参数会是0,0和1,1因此递归的终止条件为left==right。
在合并的过程中,可以在两个数组中分别设置两个指针,比较两个数组当前元素,哪个小就把哪个放入结果数组中,如果数组遍历完毕,(一定是某个先遍历完,不会同时遍历完的。)就把另一个数组中没遍历的元素依次放入结果数组。代码可以这样设计,如果数组A的元素小于数组B的元素,就把数组A的元素放入结果数组中,此时还要考虑数组A可能已经遍历完毕。
代码如下:
package Java;
//归并排序
public class MergeSort {
public void sort(int[] data) {
decomposition(data,0,data.length-1);
}
public void decomposition(int[] data, int left, int right)
//先分解
{
if(left==right) return;
int mid = (left + right) / 2;
decomposition(data, left, mid);
decomposition(data, mid + 1, right);
merge(data, left, right);}
//合并方法
public void merge(int[] data, int left, int right) {
int[] newArray = new int[right-left+1];
int mid = (left + right) / 2;
int a = left;
int b = mid + 1;
int k=0;
while (k!=newArray.length)
{if(data[a]<data[b])
{
newArray[k++]=data[a];
//如果左边的比较小,可能遇到左边已经遍历完毕的情况
if(a==mid)
{ for(;b<=right;b++)
{newArray[k++]=data[b];} }
a++;
}
else
{
newArray[k++]=data[b];
if(b==right)
{for(;a<=mid;a++)
{newArray[k++]=data[a];}
}
b++;
}}
for(int l=0;l<newArray.length;l++)
{
data[l+left]=newArray[l];}
}
}
归并排序效率高的原因在于不涉及交换,比较后是存在新开辟的结果数组中的。以空间换时间???
时间复杂度:O(nlgn)
空间复杂度:O(n)额外开辟了空间。
[补:尽管每次合并操作都需要申请额外的内存空间,但在合并完成之后,临时开辟的内存空间就被释放掉了,在任意时刻,CPU只会有一个函数在执行,也就只会有一个临时的内存空间在使用,临时内存空间最大也不会超过n个数据的大小。]
如何优化?
[典型题:如何在O(n)内寻找一个无序数组的第k大元素。]
选择排序
“选择”的意思是,遍历数组,从下标为0的元素开始,“选择”剩下区间中最小的元素,与初始元素交换。在“选择”的过程中,只保留下标,即找到区间中最小的元素的下标后,再与初始元素进行交换。
[补:只有索引的变化,没有交换元素。]
代码如下:
package Java;
//选择排序,升序
public class SelectionSort {
public void sort(int[] data)
{
for(int i=0;i<data.length-1;i++)
{
int min=i;
for(int j=i+1;j<data.length;j++)
{ if(data[j]<data[min])
{min=j;}}
int save=data[min];
data[min]=data[i];
data[i]=save;
}
}
}
时间复杂度:O(n^2)
空间复杂度:O(1) 没有开辟额外空间——原地排序。
稳定性,写的代码如果值相等是不进行交换的——稳定。
[改:
是不稳定的,记住一个例子{5,8,5,2,9}
]
优化:???
快速排序
快速排序和插入排序有点类似,也是有已排序区和未排序区。
普通的快排,先来个例子:以数组[0]为分区点,假设从1到i都是小于分区点的元素,从i+1到j都是大于分区点的元素,从j+1开始继续遍历到数组末,如果元素小于分区点,就将该元素于下标为i+1的元素交换,然后i++,即可保持【i表示比分区点小的区域的末元素】,如果元素大于分区点,就将j++,即可保持【j表示比分区点大的区域的末元素】。最后只需要将[i]与[0]对应的元素互换即可使原来下标为0的元素到正确的位置(因为比它小的元素都到它左边,比它大的元素都到它右边)。
那么想实现对数组的快速排序,只需要从数组[0]开始,遍历整个数组,将每个元素作为分区点,然后重复上述方法,为每个元素找到正确位置即可。代码如下:
[改:错了!!!并不是遍历数组,而是递归,继续对比它小的区间和比它大的区间进行快速排序,(怪不得我发现我的快排对值相等的情况排序存在问题。)]
[补:不能说错了。 之前有问:如果不用递归,如何实现快速排序? 哈哈哈哈我可真是太棒了。]
快速排序普通版 递归版:
package Java.QuickSort;
import java.util.Arrays;
//快速排序
public class PrimarySort {
public void sort(int[] data)
{
sort1(data,0,data.length-1);
}
public void sort1(int[] data,int p,int r)
{if(p>=r) return;
int partition=findSolution(data,p,r);
sort1(data,p,partition-1);
sort1(data,partition+1,r);
}
//错了!!!不是遍历数组为每一个元素寻找正确插入位置,而是递归调用快排
//对比分区点小的区间进行快排,对比分区点大的区间进行快排
public int findSolution(int[] data,int k,int m)
{ //总是以传进小数组的第一个元素为分区点
int pPoint = data[k];
int i = k;
for (int a = k+1; a <=m; a++) {
if (data[a] < pPoint) {
swap(data, i + 1, a);
i++;
}
}
swap(data,i,k);
return i;}
public void swap ( int[] data, int a, int b)
{
int temp = data[a];
data[a] = data[b];
data[b] = temp;
}
}
快速排序普通版 开空间 挨个遍历找正确位置版:
(这样写不适用于有值相等的数组)
package Java.QuickSort;
//快速排序
public class PrimarySort {
public void sort(int[] data)
{//从下标为0开始,为各元素寻找正确位置
for(int k=0;k<data.length;k++)
{int pPoint=data[k];
int i=k;
int j=k;
for(int a=k+1;a<data.length;a++) {
if (data[a] < pPoint) {
swap(data, i + 1, a);
i++;
} else {
j++;
}
}swap(data, i, k); }
}
public void swap(int[]data,int a,int b)
{
int temp=data[a];
data[a]=data[b];
data[b]=temp;
}
}
时间复杂度O(n^2)
[改:时间复杂度:O(nlgn) ]
空间复杂度O(1) 没有额外开辟空间。
稳定性:根据写的代码,如果值相等是不交换的,稳定。
优化:随机确定分区点,而不是第一个元素。
代码如下:
//优化:随机生成分区点
int pPointIndex=randomly(k,m);
swap(data,k,pPointIndex);
//优化:随机生成分区点
public int randomly(int k,int m)
{
return (int)(k+Math.random()*(m-k));
}
二路快排
刚刚的一路快排只有一个指向小于分区点末元素的指针是有用的,那个指向大于分区点末的指针其实并没有什么用。现在进行有两个指针,前面的指针i指向比分区点元素小的最后一个元素,后面的指针j指向比分区点元素大的第一个元素,两个指针同时开始移动,前面的向后走,后面的向前走,如果前面的指针指向的元素大于分区点元素,需要将这个元素与j-1指向的元素交换位置,并且j–,否则i++即可。如果后面的指针指向的元素小于分区点元素,需要将这个元素与i+1指向的元素交换位置,否则j–即可。
代码如下:
package Java.QuickSort;
//双路快排,两个指针
public class DualSort {
public void sort(int[] data)
{
for(int k=0;k<data.length;k++)
{
int i=k;
int j=data.length;
int value=data[k];
while (i+1!=j)
{
if(data[i+1]>value){
swap(data,i+1,j-1);
j--;
}
else {i++;}
if(i+1==j) break;
if(data[j-1]<value)
{
swap(data,j-1,i+1);
i++;
}
else{j--;}
}
swap(data,k,i);
}
}
public void swap(int[] data,int a,int b)
{
int temp=data[a];
data[a]=data[b];
data[b]=temp;
}
}
(易错 ! ! ! )在写双路快排时我发现了一个问题,遍历数组的每个元素,每次为当前元素找到正确的位置后,这个数组是变化了的,”遍历“的并不是初始数组,而是上一次改变某些元素位置后的新的数组,因此排序后的结果是错误的。可以每次存下该元素应该去的位置,最后统一赋值。
修改后的代码:(通过单元测试)
双路快排
package Java.QuickSort;
import java.lang.reflect.Array;
import java.util.Arrays;
//双路快排,两个指针
public class DualSort {
public void sort(int[] data) {
int[] result = new int[data.length];
int[] copyArray=Arrays.copyOf(data,data.length);
int[] copyArray2;
//为避免每次排序的都是上一次更新过的数组
for (int j = 0; j < data.length; j++) {
copyArray2=Arrays.copyOf(copyArray,copyArray.length);
result[findSolution(copyArray2, j)] = data[j];
}
for (int k = 0; k < data.length; k++) {
data[k] = result[k];
}
}
public int findSolution(int[] data, int k) {
swap(data, 0, k);
int i = 0;
int[] copyArray = Arrays.copyOf(data, data.length);
int j = copyArray.length;
int value = data[0];
while (i + 1 != j) {
if (copyArray[i + 1] > value) {
swap(copyArray, i + 1, j - 1);
j--;
} else {
i++;
}
if (i + 1 == j) break;
if (copyArray[j - 1] < value) {
swap(copyArray, j - 1, i + 1);
i++;
} else {
j--;
}
}
return i;
}
public void swap(int[] data, int a, int b) {
int temp = data[a];
data[a] = data[b];
data[b] = temp;
}
}
在单路快排递归版的启发下,写成双路快排递归版:
package Java.QuickSort;
import java.util.Arrays;
//双路快排,两个指针
//递归版
public class DualSort {
public void sort(int []data)
{sort1(data,0,data.length-1);}
public void sort1(int[] data,int k,int m)
{if(k>=m) return;
int partition=findSolution(data,k,m);
sort1(data,k,partition-1);
sort1(data,partition+1,m);
}
public int findSolution(int[] data, int k,int m) {
int i = k;
int j=m+1;
int value = data[i];
while (i + 1 != j) {
if (data[i + 1] > value) {
swap(data, i + 1, j - 1);
j--;
} else {
i++;
}
if (i + 1 == j) break;
if (data[j - 1] <= value) {
swap(data, j - 1, i + 1);
i++;
} else { j--; } }
swap(data,i,k);
return i;
}
public void swap(int[] data, int a, int b) {
int temp = data[a];
data[a] = data[b];
data[b] = temp;
}
}
堆排序
首先需要将数组变成堆,满足:每个根节点大于左子树,小于右子树。(那这个是什么数据结构??? ) 然后中序遍历堆,即可完成从小到大的排序。
[改:每个根节点大于左子树,小于右子树是二分搜索树。]
[改:]
先把数组变成堆,满足:每个根节点都不小于它的左右子树。然后依次取得堆顶,并保持堆结构。经过对每日总结[8]的回顾,需要注意以下几点:
(1)堆以数组形式存储。
(2)根大于左子树,小于右子树的是搜索二叉树,根不小于左右子树的是大顶堆。
写代码如下:(完球了,一星期前的思路已经忘光光了。从下周复习开始,每天写总结前必须复习上一次总结,难也要坚持。)
(回顾了以下上一篇发现调用了siftDown的那个heapify方法是错的哈哈哈哈,这下好了不想看了,等下次刷面经看到再总结堆排序吧。)
2.补充
通常排序的目的是快速查找。
**在相同数据集下推荐使用插入排序。**因为如果把执行一个赋值语句的时间粗略计为单位时间,冒泡排序k次交换操作,每次需要3个赋值语句,耗时3*k单位时间,而插入排序只需要k单位时间。而且插入排序的算法思路也有很大的优化空间。


3.de过 的那些bug的那些坑:
(1)排序中会遇到比较,比如插入排序,以{1,3,8,4}为例,{1,3,8}已经是有序数组,需要将元素4插入其中,从后向前遍历,4<8,需要将8向后挪一位,腾出位置,而这时的数组就变成了{1,3,8,8}如果写成if(data[j]<data[already+1]),already表示已排序区末,则already+1表示未排序区初,这时的already+1对应的元素变成了8,而不是我们未排序的那个4,因此,需要将4提前存起来,是与这个值比,而不是与那个下标对应的元素比。 特别容易错。
(2)写递归终止条件中要特别注意边界条件:<0??? >length???
比如折半插入中,如果用来标记已排序数组右端的right=-1,以{11,3}为例,其中{11}是有序数组,需要为"3"寻找位置,如果不单独判断它,从局部看,因为3<11,因此右端的right会跑到mid的左侧,变成-1,而mid=0,接下来right<left,需要确定插入位置了,因为3<11,插入位置为mid-1,即-1,出错。真是right=-1导致了返回插入数组的位置为-1,在折半插入中,比较后无非是left=mid+1,(left始终不会>already+1(最多=already+1),因此不涉及边界情况)和right=mid-1,只有right可能因为被减成-1,导致出错。
如果以{3,11}为例,不会出现这样的问题,因为执行的是left=mid+1.
(3)递归方法里面可别再"while"了,是想循环多少次 ???:
public void decomposition(int[] data, int left, int right)
{ int mid = (left + right) / 2;
while(mid!=left) {
decomposition(data, left, mid);
decomposition(data, mid + 1, right);
merge(data, left, right);}
}
`` `
需要用if() return;
