文章目录
引言
想要快速掌握开发技能,提升开发水平,做一个优质的项目往往可以事半功倍,最近公司一直在研究rpa(机器人流程自动化),自己的老本行——java开发似乎变得生疏了一些,正好也快过年了,想利用年前的时间巩固一下java相关的知识,所以找了一个某机构比较好的项目,在这里以博客的形式记录下来,希望能够对大家有所帮助。(代码生成器也会抽时间更新一下,毕竟很久没更了。。。)
这是一个类似社交平台交流的项目,话不多说,我直接上图了,如下: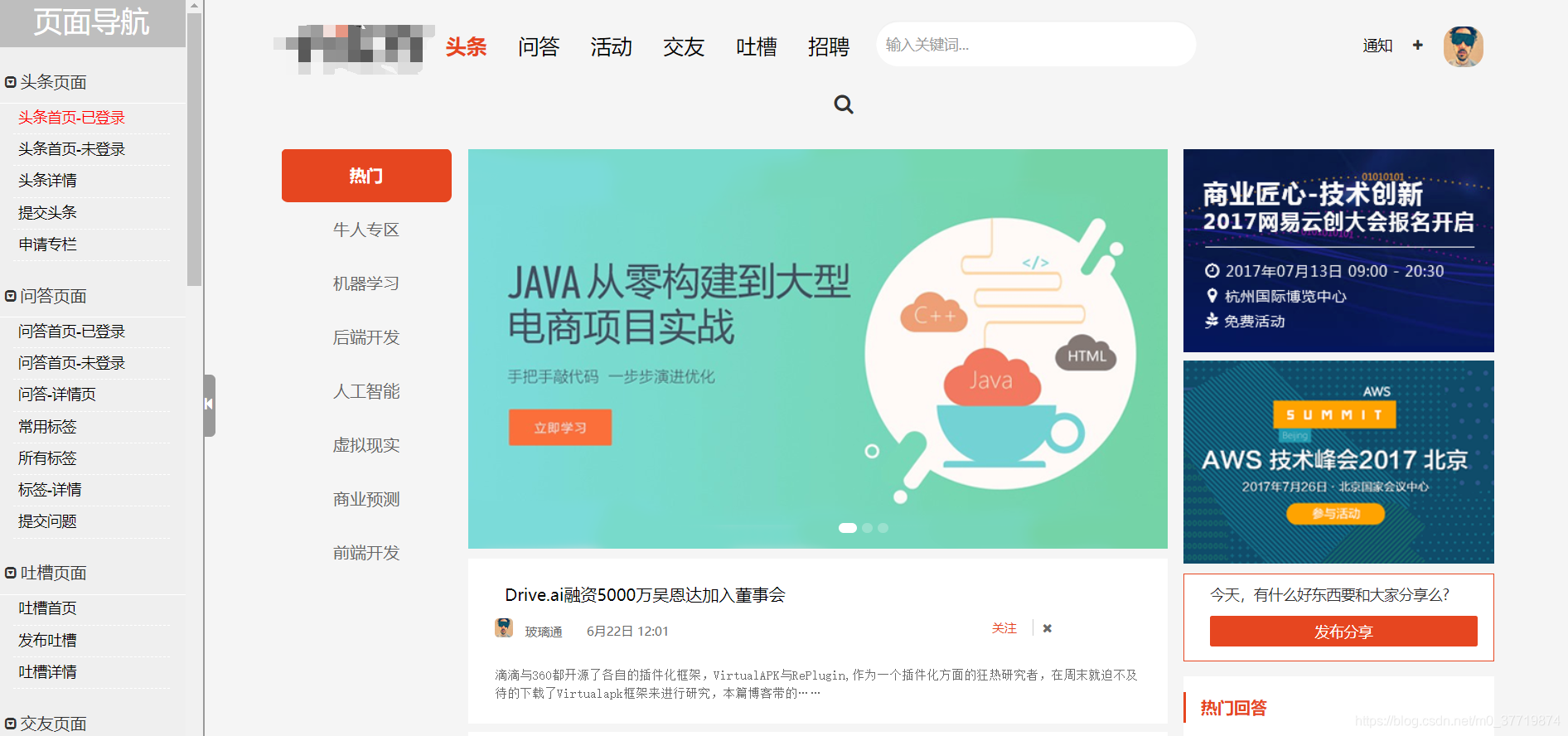
相信有的朋友已经知道这是哪个项目了,哈哈,看破不说破哦,这个项目运用的技术还是比较广泛的,比如springboot,springcloud,springdata,docker,elasticsearch,nodejs,vue等都是当下十分热门的技术。
docker创建mysql微服务
这个项目所有的服务都是使用docker镜像,然后运行相应的容器,docker的优点不用多说,使用方便,内存占用少,各种命令也可以轻松上手,
首先用docker先把mysql微服务搭建并运行起来。依次执行以下命令即可
#安装docker
yum install docker
#查询mysql镜像,选择一个
docker search mysql
#这里以mysql5.7为例
docker pull centos/mysql-57-centos7
#运行镜像(-di 后台运行 --name 命名 -p 访问的端口:映射的端口 -e 设密码)
docker run -di --name=mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root centos/mysql-57-centos7
成功执行完以上命令之后,mysql微服务就初步建立起来了,使用navicat可以成功连接。
父工程搭建
数据库搭建完毕后,首先来搭建maven父工程项目,因为是微服务项目,势必会有很多不同的服务模块,所以需要一个总的父工程把每个微服务整合到一起,同时可以把公共的maven依赖集成到父工程当中,避免冗余代码,整体会显得干净利落。
在这里我们抛弃eclipse,拥抱idea,做微服务项目eclipse实在有些不便,关于idea的下载和破解对于一个程序员来说都是基操了,不多赘述。
打开idea,创建maven项目,不需要选择模板,因为父工程只需要一个pom文件即可,步骤如下:
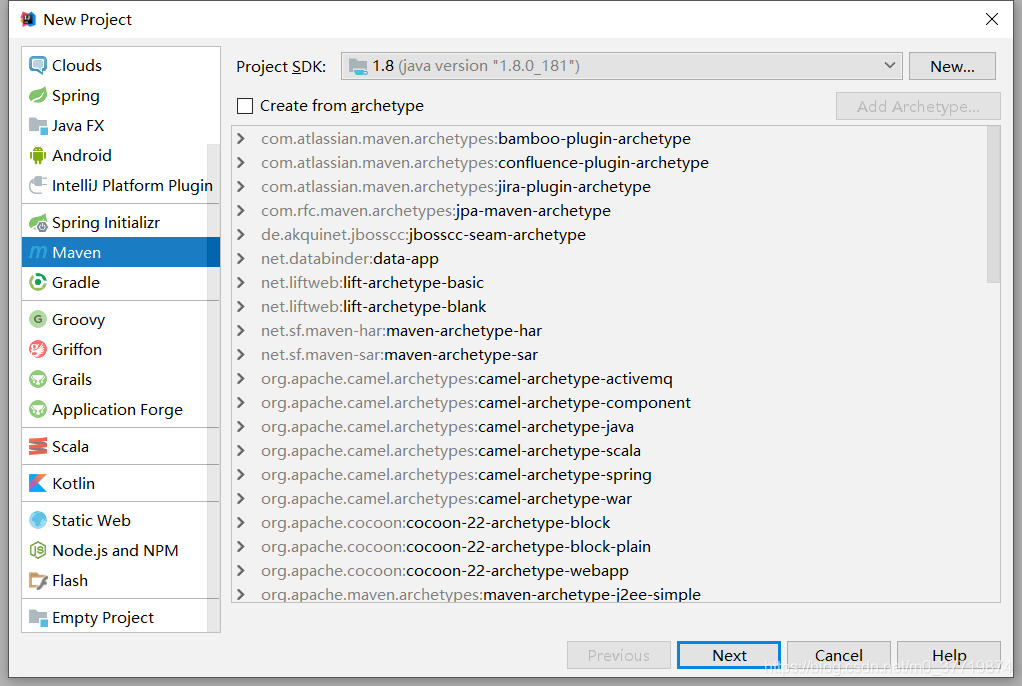
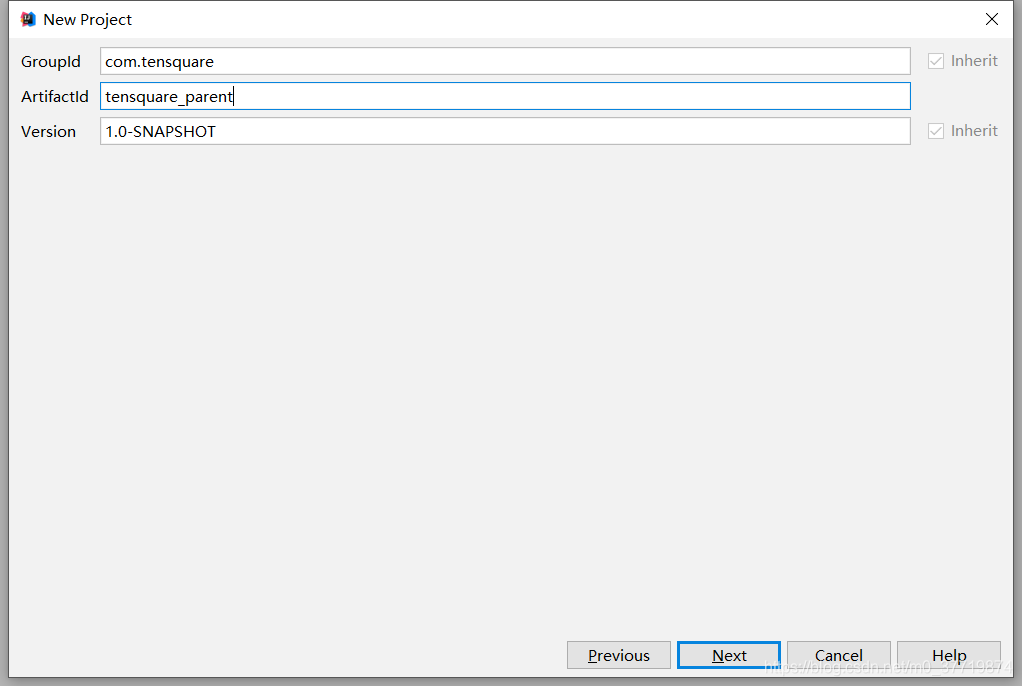
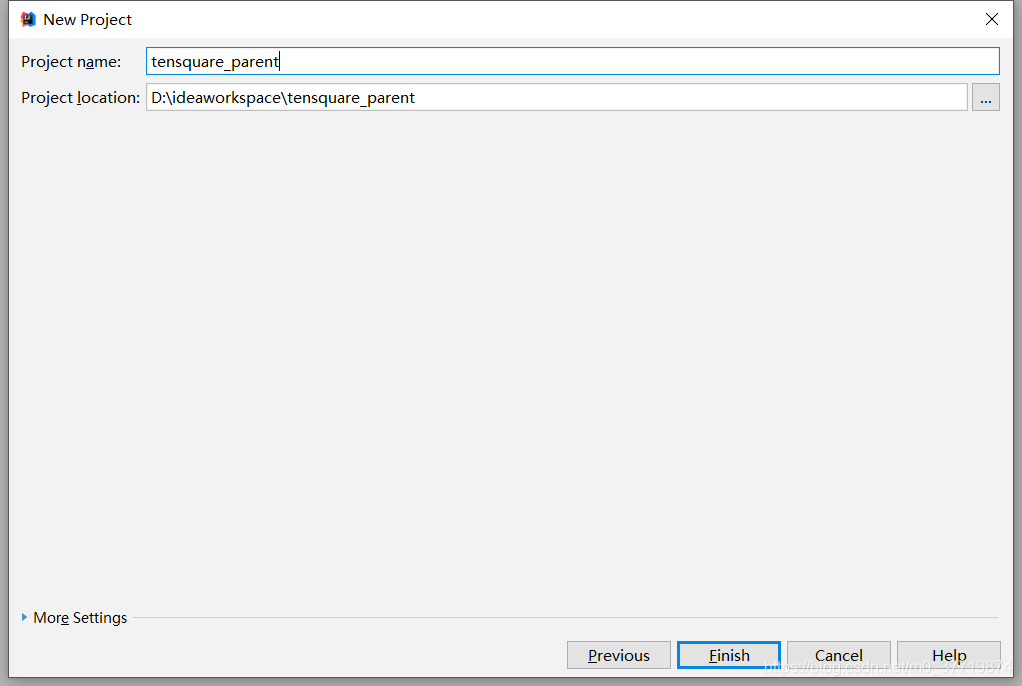
父工程目录结构如下所示:
src目录对于父工程来说没有用处,因为父工程内并不会写代码,可以二话不说直接删除掉。
&esmp;接下来需要修改一下pom文件,如下:
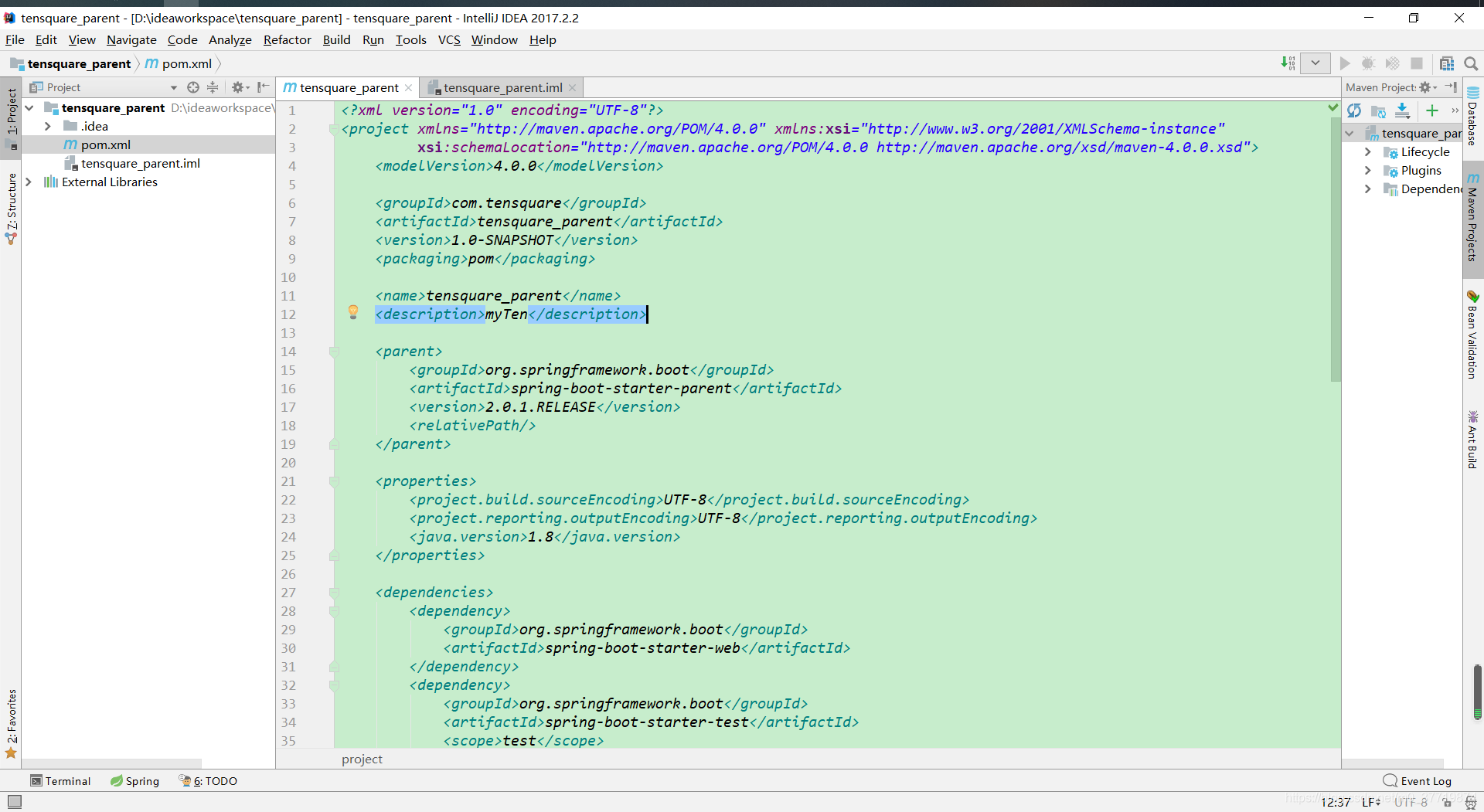
pom文件的内容如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tensquare</groupId>
<artifactId>tensquare_parent</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>pom</packaging>
<name>tensquare_parent</name>
<description>myten</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.1.RELEASE</version>
<relativePath/>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</pluginRepository>
<pluginRepository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
</project>
这样一来,父工程就基本搭建完毕了,其中 pluginRepositories 标签内的内容为spring官方的插件仓库,如果有jar包更新,会自动下载,如果不进行配置,并不会自动下载,建议凡是微服务相关的项目都在后面配置上去。
创建公共子模块
微服务通常是一个庞大的项目,所以有很多公共的类或工具类可以抽取出来供所有的服务使用,所以公共子模块的创建还是很有必要的,公共子模块本身不需要运行,所以同样不需要选择模板,一个普通的java应用即可,创建步骤如下所示:
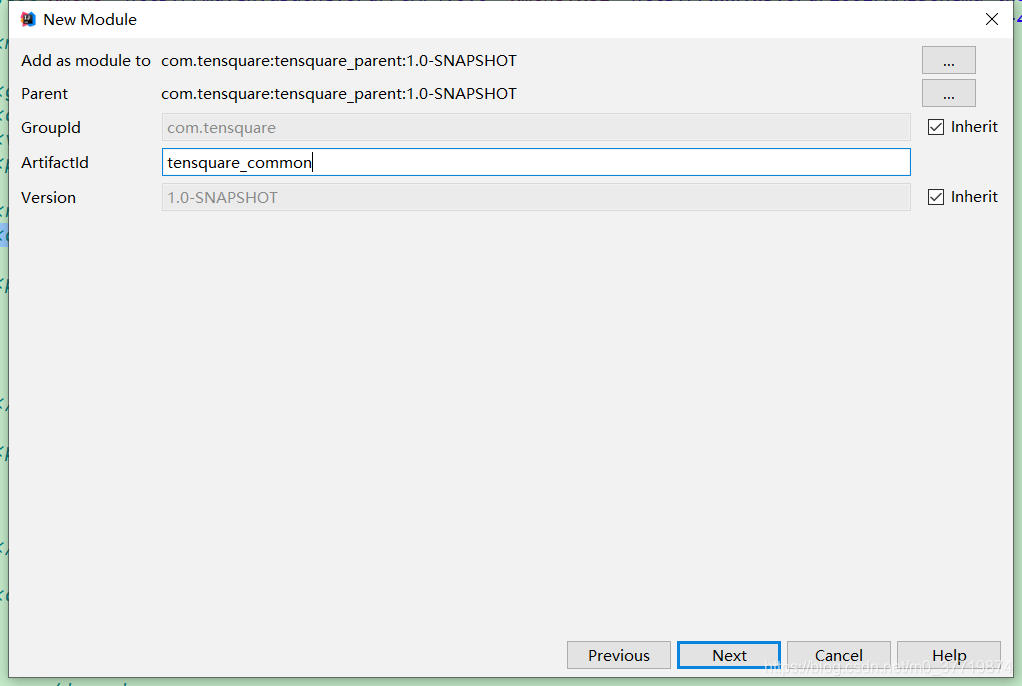
finish之后,整体项目结构如下:
无论是什么项目,都需要实体类来方便开发者进行数据处理与交互,在这里我们在java文件夹下创建entity包,然后分别创建Result实体类,PageResult实体类和StatusCode实体类,Result主要用来封装返回响应结果,PageResult是分页实体,StatusCode主要存储静态状态码,实体类代码如下:
package entity;
public class Result {
//返回的标志
private boolean flag;
//状态码
private Integer code;
//消息内容
private String message;
//数据内容
private Object data;
public Result(boolean flag, Integer code, String message, Object data) {
this.flag = flag;
this.code = code;
this.message = message;
this.data = data;
}
public Result() {
}
public boolean isFlag() {
return flag;
}
public void setFlag(boolean flag) {
this.flag = flag;
}
public Integer getCode() {
return code;
}
public void setCode(Integer code) {
this.code = code;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public Object getData() {
return data;
}
public void setData(Object data) {
this.data = data;
}
}
package entity;
import java.util.List;
public class PageResult<T> {
private long total;
private List<T> rows;
public PageResult(long total, List<T> rows) {
this.total = total;
this.rows = rows;
}
public PageResult(long total) {
this.total = total;
}
public long getTotal() {
return total;
}
public void setTotal(long total) {
this.total = total;
}
public List<T> getRows() {
return rows;
}
public void setRows(List<T> rows) {
this.rows = rows;
}
}
package entity;
public class StatusCode {
public static final int OK = 20000;//成功
public static final int ERROR = 20001;//失败
public static final int LOGINERROR = 20002;//用户名或密码错误
public static final int ACCESSERROR = 20003;//权限不足
public static final int REMOTEERROR = 20004;//远程调用失败
public static final int REPERROR = 20005;//重复操作
}
由于我们的项目是分布式项目,所以唯一标识例如数据库的主键字段也需要使用分布式id,这里我们使用推特的“雪花算法“来生成id,英文名 snowflake,他是一个64位的唯一标识,首位固定为0,前41位根据时间戳生成,往后10位根据工作机器id生成,最后12位生成随机的12位数,每秒能生成大约26个不同的id,非常强大,性能出色。如果一瞬间超过了26万,那就需要使用消息队列等相关技术去解决了。
有兴趣的朋友可以研究一下,代码如下:
package util;
import java.lang.management.ManagementFactory;
import java.net.InetAddress;
import java.net.NetworkInterface;
/**
* <p>名称:IdWorker.java</p>
* <p>描述:分布式自增长ID</p>
* <pre>
* Twitter的 Snowflake JAVA实现方案
* </pre>
* 核心代码为其IdWorker这个类实现,其原理结构如下,我分别用一个0表示一位,用—分割开部分的作用:
* 1||0---0000000000 0000000000 0000000000 0000000000 0 --- 00000 ---00000 ---000000000000
* 在上面的字符串中,第一位为未使用(实际上也可作为long的符号位),接下来的41位为毫秒级时间,
* 然后5位datacenter标识位,5位机器ID(并不算标识符,实际是为线程标识),
* 然后12位该毫秒内的当前毫秒内的计数,加起来刚好64位,为一个Long型。
* 这样的好处是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和机器ID作区分),
* 并且效率较高,经测试,snowflake每秒能够产生26万ID左右,完全满足需要。
* <p>
* 64位ID (42(毫秒)+5(机器ID)+5(业务编码)+12(重复累加))
*
* @author Polim
*/
public class IdWorker {
// 时间起始标记点,作为基准,一般取系统的最近时间(一旦确定不能变动)
private final static long twepoch = 1288834974657L;
// 机器标识位数
private final static long workerIdBits = 5L;
// 数据中心标识位数
private final static long datacenterIdBits = 5L;
// 机器ID最大值
private final static long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 数据中心ID最大值
private final static long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// 毫秒内自增位
private final static long sequenceBits = 12L;
// 机器ID偏左移12位
private final static long workerIdShift = sequenceBits;
// 数据中心ID左移17位
private final static long datacenterIdShift = sequenceBits + workerIdBits;
// 时间毫秒左移22位
private final static long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private final static long sequenceMask = -1L ^ (-1L << sequenceBits);
/* 上次生产id时间戳 */
private static long lastTimestamp = -1L;
// 0,并发控制
private long sequence = 0L;
private final long workerId;
// 数据标识id部分
private final long datacenterId;
public IdWorker() {
this.datacenterId = getDatacenterId(maxDatacenterId);
this.workerId = getMaxWorkerId(datacenterId, maxWorkerId);
}
/**
* @param workerId 工作机器ID
* @param datacenterId 序列号
*/
public IdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 获取下一个ID
*
* @return
*/
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
// 当前毫秒内,则+1
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
// 当前毫秒内计数满了,则等待下一秒
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
// ID偏移组合生成最终的ID,并返回ID
long nextId = ((timestamp - twepoch) << timestampLeftShift)
| (datacenterId << datacenterIdShift)
| (workerId << workerIdShift) | sequence;
return nextId;
}
private long tilNextMillis(final long lastTimestamp) {
long timestamp = this.timeGen();
while (timestamp <= lastTimestamp) {
timestamp = this.timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
/**
* <p>
* 获取 maxWorkerId
* </p>
*/
protected static long getMaxWorkerId(long datacenterId, long maxWorkerId) {
StringBuffer mpid = new StringBuffer();
mpid.append(datacenterId);
String name = ManagementFactory.getRuntimeMXBean().getName();
if (!name.isEmpty()) {
/*
* GET jvmPid
*/
mpid.append(name.split("@")[0]);
}
/*
* MAC + PID 的 hashcode 获取16个低位
*/
return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);
}
/**
* <p>
* 数据标识id部分
* </p>
*/
protected static long getDatacenterId(long maxDatacenterId) {
long id = 0L;
try {
InetAddress ip = InetAddress.getLocalHost();
NetworkInterface network = NetworkInterface.getByInetAddress(ip);
if (network == null) {
id = 1L;
} else {
byte[] mac = network.getHardwareAddress();
id = ((0x000000FF & (long) mac[mac.length - 1])
| (0x0000FF00 & (((long) mac[mac.length - 2]) << 8))) >> 6;
id = id % (maxDatacenterId + 1);
}
} catch (Exception e) {
System.out.println(" getDatacenterId: " + e.getMessage());
}
return id;
}
}
ok,现在整体的项目结构如图:
小结
好了,就写到这里吧,这次主要讲述了三个内容:docker运行MySQL容器;maven父工程的创建,依赖的引入;公共子模块的创建以及相关的实体和工具类,下次更新会介绍基础模块相关的内容,感谢您的观看!
