1.采集数据网站:51job前程无忧
为避免打广告嫌疑,自行前往官网查看
2.分析网站查询方式:

总体来说分为4种 ,如下图:

即按职位,分为全国和某省市;按公司名称,分为全国和某省市
3.先按全文(即职位)搜索,输入岗位,地点

最中确定链接为
"https://search.51job.com/list/"+地区编码+",000000,0000,00,9,99,"+"按全文输入的职位内容"但是要注意的是,当我们在 全文中输入中文时,链接就有点不一样了

仔细观察,有经验的话,会觉得这是最常见的url编码加密,但是仔细看又有点不一样,我们将销售拿出来借助代码加密:
from urllib.parse import quote,unquote
print(quote("销售"))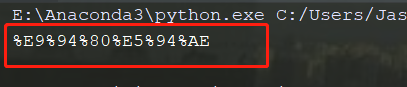

两者对比,发现除了进行url编码外,还稍微动了点手脚,每个%后面加了个25,我们直接replace就行了
print(quote("销售").replace("%","%25"))
现在两者参数一样了。
4.链接破解了,下面对网站数据进行分析:
F12检查元素和查看源码分析,数据都加载在页面中,直接提取就行了


请求第一页时顺便获取到总页数

type1,search_text,add = self.choose_type_add()
if type1 == "1":
encode_search_text = quote(str(search_text)).replace("%","%25")
url = self.bash_url.replace("#","000000").replace("$",str(encode_search_text))
#获取总页数
url = url.replace("page_num","1")
res = requests.get(url)
res.encoding = "gbk"
total_page = re.findall(r'<span class="td">共(\d+)页.*?</span>',res.text,re.S)
print(total_page)其他没什么问题,直接xpath定位即可
整体代码
# -*- coding: UTF-8 -*-
'''
@Author :Jason
51job数据采集
'''
import requests
import csv
from lxml import etree
from urllib.parse import quote_plus,quote,unquote
import re
import random
from time import sleep
class get_51job(object):
def __init__(self):
#这个url前面是固定的+ 地区+ 写死 + 输入词 + 页数 +固定部分
self.bash_url = "http://search.51job.com/list/"+"#"+",000000,0000,00,9,99,"+"$"+",2,"+"page_num"+".html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
self.proxies = random.choice([
{"HTTP": "http://我的代理"},
])
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36'}
def choose_type_add(self):
type1 = input("搜全文输入1,搜公司输入2:")
if type1 == "1":
search_text = input("请输入想要查询的职位等信息:")
add = input("请输入需要查询的地区:")
else:
search_text = input("请输入想要查询的公司信息:")
add = input("请输入需要查询的地区:")
return type1,search_text,add
def get_html(self):
type1,search_text,add = self.choose_type_add()
if type1 == "1":
with open('51job职位详情表.csv', 'a', newline='') as f:
f = csv.writer(f)
f.writerow(('职位', '公司', '工作地点', '薪水', '发布日期', '职位链接', '公司链接'))
encode_search_text = quote(str(search_text)).replace("%","%25")
start_url = self.bash_url.replace("#","000000").replace("$",str(encode_search_text))
#获取总页数
url = start_url.replace("page_num","1")
res = requests.get(url)
res.encoding = "gbk"
total_page = re.findall(r'<span class="td">共(\d+)页.*?</span>',res.text,re.S)
# print(total_page)
if total_page:
for page_num in range(0,int(total_page[0])):
res = requests.get(start_url.replace("page_num",str(page_num+1)))
sleep(2)
res.encoding = "gbk"
parseHtml = etree.HTML(res.text)
position_list = parseHtml.xpath('//div[@class="dw_table"]//div[@class="el"]/p/span[1]/a/@title')
company_name_list = parseHtml.xpath('//div[@class="dw_table"]//div[@class="el"]/span[1]/a/@title')
address_list = parseHtml.xpath('//div[@class="dw_table"]//div[@class="el"]/span[2]/text()')
salary_list = parseHtml.xpath('//div[@class="dw_table"]//div[@class="el"]/span[3]')
release_date_list = parseHtml.xpath('//div[@class="dw_table"]//div[@class="el"]/span[4]/text()')
job_url_list = parseHtml.xpath('//div[@class="dw_table"]//div[@class="el"]/p/span[1]/a/@href')
company_url_list = parseHtml.xpath('//div[@class="dw_table"]//div[@class="el"]/span[1]/a/@href')
try:
for i,p in enumerate(position_list):
print(p)
with open('51job职位详情表.csv', 'a', newline='') as f:
f = csv.writer(f)
f.writerow((position_list[i],company_name_list[i],address_list[i],
salary_list[i].text,release_date_list[i],job_url_list[i],
company_url_list[i]))
except Exception as e:
print(e)
finally:
pass
else:
print("没有相关职位!")
else:#这个是搜公名字
with open('51job公司职位详情表.csv', 'a', newline='') as f:
f = csv.writer(f)
f.writerow(('职位', '公司', '工作地点', '薪水', '发布日期', '职位链接', '公司链接'))
encode_search_text = quote(str(search_text)).replace("%", "%25")
start_url = self.bash_url.replace("#", "000000").replace("$", str(encode_search_text))
# 获取总页数
url = start_url.replace("page_num", "1")
print(url)
res = requests.get(url)
res.encoding = "gbk"
total_page = re.findall(r'<span class="td">共(\d+)页.*?</span>', res.text, re.S)
print(total_page)
if total_page:
for page_num in range(0, int(total_page[0])):
res = requests.get(start_url.replace("page_num", str(page_num+1)))
sleep(2)
res.encoding = "gbk"
parseHtml = etree.HTML(res.text)
position_list = parseHtml.xpath('//div[@class="dw_table"]//div[@class="el"]/p/span[1]/a/@title')
company_name_list = parseHtml.xpath('//div[@class="dw_table"]//div[@class="el"]/span[1]/a/@title')
address_list = parseHtml.xpath('//div[@class="dw_table"]//div[@class="el"]/span[2]/text()')
salary_list = parseHtml.xpath('//div[@class="dw_table"]//div[@class="el"]/span[3]')
release_date_list = parseHtml.xpath('//div[@class="dw_table"]//div[@class="el"]/span[4]/text()')
job_url_list = parseHtml.xpath('//div[@class="dw_table"]//div[@class="el"]/p/span[1]/a/@href')
company_url_list = parseHtml.xpath('//div[@class="dw_table"]//div[@class="el"]/span[1]/a/@href')
try:
print(position_list)
for i, p in enumerate(position_list):
with open('51job公司职位详情表.csv', 'a', newline='') as f:
f = csv.writer(f)
f.writerow((position_list[i], company_name_list[i], address_list[i],
salary_list[i].text, release_date_list[i], job_url_list[i],
company_url_list[i]))
except Exception as e:
print(e)
finally:
pass
else:
print("没有找到相关信息")
if __name__ == "__main__":
job51 = get_51job()
job51.get_html()唯一可能还需要做的就是做个地区的映射,暂时就不做了。需要的话可以自己去建个
此版本爬取日期为2019-12-23
声明: 采集仅源自个人兴趣爱好,数据集仅供个人使用,不涉及商用,侵权联系删除。
