转自公众号-AI圈终身学习。
一个人是孤独的,一群人是强大的,欢迎关注。
写在前面
前文我们介绍了简单有效的感知器,用它实现了一个线性分类器,并在鸢尾花数据集上取得不错的效果。您肯定懂得AI领域做分类任务的基本原理了。
如果您觉得迷迷糊糊也很正常,因为我们没有讲感知器的更新规则算法-梯度下降。
如果单单讲个梯度下降,您可能会看睡着。所以,我们一起来动手做一个AI领域的基础任务-回归任务。相信学完本文您就能懂线性单元和AI领域回归任务的基本原理了。
本文在整个文集中是承上启下的核心章节,会讲解目标函数、优化算法等。他们组成了通吃整个机器学习的基本套路,非常重要。希望您能坚持下来。
一、回归任务
考虑这样一个简单问题,假如我有几个朋友在互联网公司做AI工程师,他们的工龄与月薪关系如下:
| 朋友 | 工龄 | 月薪 |
|---|---|---|
| A | 5 | 55000 |
| B | 3 | 23000 |
| C | 8 | 76000 |
| D | 1.4 | 18000 |
| E | 10.1 | 114000 |
我们画个图看看:
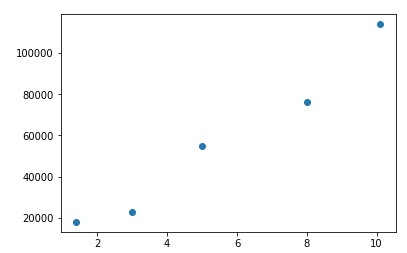
横坐标为工龄,纵坐标为月薪,我们可以看到有非常明显的线性增长关系。这也比较符合直觉,因为我们都知道一般来讲,工龄越长,工资越高,俗称资深互联网老兵。因此我们现在的问题是:
如何根据这些数据,判断一个工龄为9年的AI工程师,月薪是多少呢?
当然现实中影响因素会更复杂,可能有学历、公司、职级等因素影响。当然如果我们有这些数据,预测的结果会更加精准,但是现在我们可以先这样简化一下。这种输入x,预测一个不确定值y,就是回归问题。
那么问题来了,因为我们上文提到的感知器始终只能输出两个值,0或者1。所以这种问题怎么办呢?这个时候我们把感知器的激活函数修改成线性函数即可,这就是线性单元。
二、线性单元
线性单元结构和感知器完全一样,唯一不同的地方只是修改了激活函数部分。
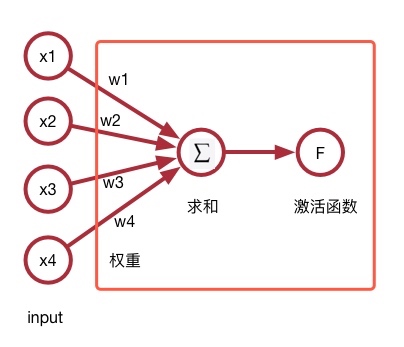
我们回忆一下用以分类任务的感知器的激活函数是阶跃函数:

我们把它改成线性函数即为线性单元:
这样我们的输出就不局限在0,1,而是一个实数了。接下来我们看看,输入五位朋友的工龄和薪水,模型是如何学习权重的。
三、线性单元的正向传播
我们已经知道,感知器和线性单元的输出结果都可以用这个公式表示:
本任务中共有5条数据,但是只有一个特征-工龄,权重个数与特征数量相等,所以我们只有一个权重和一个偏置项 ,因此线性单元输出为:
我们不可能直接得到最优的 ,一般我们的权重会初始化为0。但是此时预测的工资 为0,与真实的工资y相差甚远。因此现在我们最关心的问题是,如何取到合适的 值?
四、线性单元的权重更新
现在我们已经有了初始的输出值
以及真实的实际值
,人们常用下面的公式表示
的接近度:
是5条数据中1条样本的误差,我们叫做单个样本的误差。其中 ,是已知值,所以我们只需要学习到 使得预测的工资与真实工资尽可能接近。也就是使得 尽可能小,那么就达到我们的目的了。
所以现在我们的问题变成了求解这个方程的最小值,这就需要用到梯度下降优化算法。
4.1 梯度下降算法
我们在大一的时候学过函数 的极值点就是它的导数 的点。因此我们可以通过解方程 得到函数的极值点 。
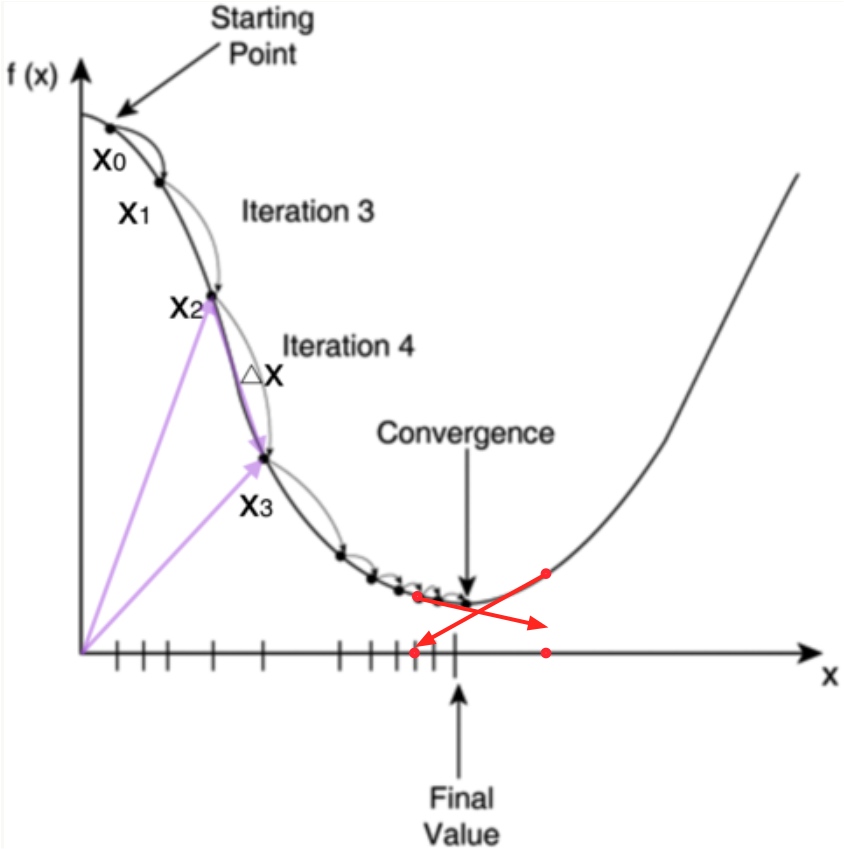
同理可以得到方程 的极值点。但是计算机是不会解方程的,怎么办呢?这里就要用到梯度下降了:
如图,
对应于我们任务的
,纵坐标
对应我们的
。我们的初始点是图上的
,然后每次迭代修改
为
:
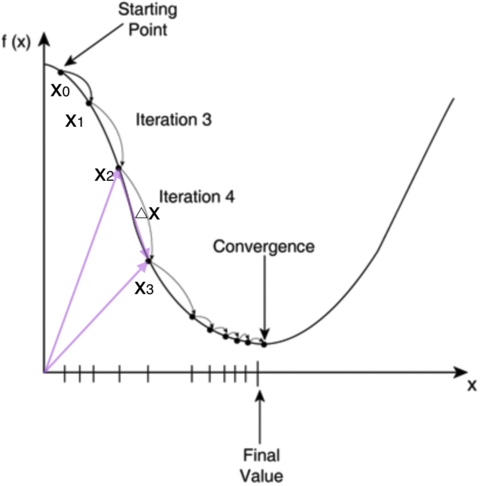
你会发现,修改后的误差值 一直在减小。为什么会这样呢?我们先解释下梯度是什么。我们以图中的线 为例,梯度是一个向量,它指向函数值上升最快的方向。因此梯度下降就是梯度的反方向,当然就是指向函数值下降最快的方向。我们每次沿着这个方向乘以一个步长去修改 的值,误差值 就会减小。
但是聪明的你会发现,这种方法很难走到函数的最小值点。因为我们的步长不可能刚刚好,如果步长过大,就会越过最小值点;如果步长过小,迭代会很慢而且容易陷入局部最小值再也出不来。步长又叫学习率,选择它是个技术活。
其实步长(学习率),我们在上一节的感知器中已经用过,就是更新规则里的 但是记不起来也没关系。我们现在开始讲解,最后会对比学习率对收敛的影响。
这里我们用公式表示下梯度下降算法,不要怕,很简单的,我们以工龄对应的权重 为例:
表示梯度, 的梯度,我们直接求导就行了:
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ \nabla{e(\math…
学过高数的同学应该都能推,很简单。如果看不懂梯度这部分推导也没关系,把最后一个等式记住就行,不影响阅读。所以现在我们得到的工龄特征对应权重 公式更新公式如下:
同理我们可以得到 的更新公式:
我们回顾下前两节的感知器更新规则:
他们是完全一样的,是不是感觉到满满的成就感。那么我们就来开始手撸代码吧。
五、手写线性单元预测工资
完整代码请参考GitHub: https://github.com/AIGroup-Z/deep-neural-network
5.1 训练数据准备
这里我们直接捏造前文表格中的数据,并捏造一个测试集:
| 朋友 | 工龄 | 月薪 |
|---|---|---|
| A | 5 | 55000 |
| B | 3 | 23000 |
| C | 8 | 76000 |
| D | 1.4 | 18000 |
| E | 10.1 | 114000 |
def get_training_dataset():
'''
训练集:捏造5个人的工作年限与对应的收入数据
'''
# 输入列表,每一项表示工作年限
x_train = [[5], [3], [8], [1.4], [10.1]]
# 期望的输出列表,月薪,注意要与输入一一对应
y_train = [55000, 23000, 76000, 18000, 114000]
return x_train, y_train
def get_test_dataset():
'''
测试集:捏造5个人的工作年限,用模型预测结果
'''
# 输入列表,每一项表示工作年限
x_test = [[1], [2], [4.3], [6.7], [9]]
return x_test
5.2 实现线性单元模型
我们总结下感知器和线性模型区别,看看两者哪些地方可以复用:
我们发现,感知器与线性单元除了激活函数完全相同,所以我们直接复用上一节感知器的代码就好了:

class LinearUnit(Perceptron):
def __init__(self, input_feature_num, activation=None):
self.activation = activation if activation else self.f
Perceptron.__init__(self, input_feature_num, self.activation)
def f(self, x):
return x
真爽。这样我们的线性单元就完全实现了。考虑到有些读者没有连贯读,我这里贴一下上文感知器Perceptron的代码。已经看过的同学跳过就好:
class Perceptron(object):
def __init__(self, input_feature_num, activation=None):
self.activation = activation if activation else self.sign
self.w = [0.0] * input_feature_num
self.b = 0.0
def predict(self, x):
'''
预测输出函数:
y_hat = f(wx + b)
'''
return self.activation(
np.dot(self.w, x) + self.b)
def sign(self, z):
'''
阶跃激活函数:
sign(z) = 1 if z > 0
sign(z) = 0 if z <= 0
'''
return int(z>0)
def fit(self, x_train, y_train, iteration=10, learning_rate=0.1):
# 训练函数
for _ in range(iteration):
for x, y in zip(x_train, y_train):
y_hat = self.predict(x)
self._update_weights(x, y, y_hat, learning_rate)
print(self)
def _update_weights(self, x, y, y_hat, learning_rate):
# 权重更新, 对照公式查看
delta = y - y_hat
self.w = np.add(self.w,
np.multiply(learning_rate * delta, x))
self.b += learning_rate * delta
def __str__(self):
return 'weights: {}\tbias: {}'.format(self.w, self.b)
5.3 模型训练-小试调参
回顾一下模型训练的流程:
准备数据->模型初始化->根据步长学习率更新权重
这里我们先用0.1的学习率看看迭代10轮后的模型:
x_train, y_train = get_training_dataset()
lu = LinearUnit(len(x_train[0]))
lu.fit(x_train, y_train, iteration=10, learning_rate=0.1)
我们看看每次迭代的权重变化:
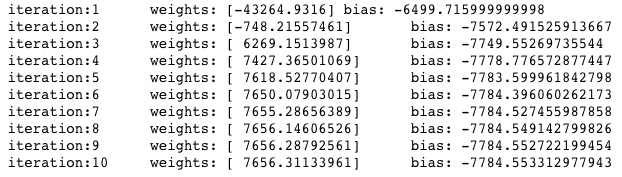
注意这里的每次迭代结果,是把所有的5条数据都跑了一遍,其实每次迭代会更新5次权重,所以一共更新了50次权重。我们发现差不多在第4次迭代的时候,就收敛了,即后边的迭代weights和bias都不再变化了。满心欢喜,此时我们作个图看看模型和数据拟合得怎么样:
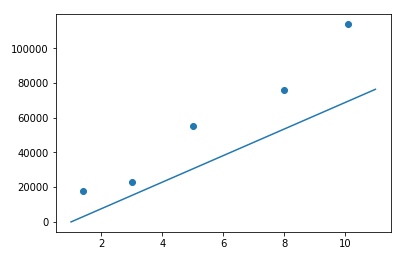
WTF??? 这偏得太多了吧。聪明的读者思考下,这是为什么呢?
这就是我们在梯度下降讲的步子太大问题,我们这次打印最后3轮所有权重更新的变化:

我们看到权重其实是在更新的,只是在这个学习率下,步子太大,损失函数会在极小值附近震荡,如图红色箭头部分:
现在我们降低学习率到0.01看看:
x_train, y_train = get_training_dataset()
lu = LinearUnit(len(x_train[0]))
lu.fit(x_train, y_train, iteration=10, learning_rate=0.1)

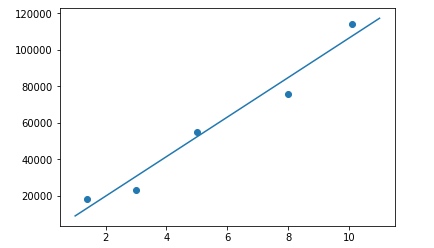
很棒,这就是我们差不多想要的模型了。
5.4 用模型去预测AI工程师工资
x_test = get_test_dataset()
prediction = []
for t in x_test:
prediction.append(lu.predict(t))
print('预测工作{}年的AI工程师\t月薪{}'.format(t, prediction[-1]))

我们画个图看看:
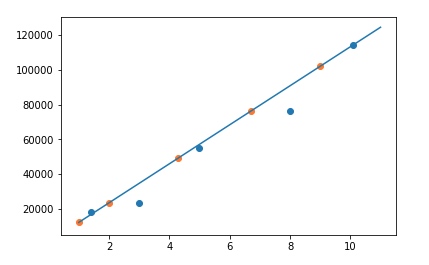
棒棒哒,工资这么高,加油干吧。
六、总结
本文为您介绍了适用于所有机器学习算法的基本套路,其实就只有两个部分:
- 模型 从输入特征x预测输出y的函数f(x)
- 目标函数 又叫损失函数,其取最值时的参数即为模型的最优参数。但是我们往往取不到最优值,只能取到局部最优值。
然后我们会用优化算法去取目标函数的最值。优化算法有很多,本文中的梯度下降只是一种。其实梯度下降算法主要有两种:
- 批梯度下降算法(Batch Gradient Descent, BGD)
- 随机梯度下降算法(Stochastic Gradient Descent, SGD)
他们的区别在于用多少条数据时,更新权重。聪明的你会发现,我们每遍历一条数据,就会更新一次权重,这就是随机梯度下降算法。其实起初大家都用批梯度下降算法,都是把样本当中的所有实际值和预测值的差值求和过后,再更新权重。但是这样计算代价太大,已经被淘汰了。另外有经验的同学知道,我们经常说的batch size设置成64,是两者的结合,就是用64条数据更新一次权重。
在机器学习中,算法并不重要,重要的是特征。比如本文中如果不止工龄这一种特征,还有公司、职级等,模型的性能会大大提升。而神经网络的优势在于可以自动学习提取哪些特征,降低人力成本,又能提高模型性能。
提前关注不迷路,敬请期待。
本文集暂定内容:
如果有任何问题。可以在公众号首页找到我们的组队学习群。

