概要
| 名称 | 表达式 | ||||
| 记录类型 | type | 名称 | is record | (名1 类型,名2 类型) | |
| 索引表 |
type | 名称 | is table of | 类型 | |
| index by | 类型 | ||||
| 嵌套表 | create | type | 名称 | as table of | 类型 |
| 复合类型嵌套表 | create | type | 名称 | as object | (名1 类型,名2 类型) |
| 可变数组 | create | type | 名称 | as array(长度) of | 类型 |
记忆
一级 : record、object、array(典型的并列关系,容易记忆,且能抓住重点,至于语法结果可以去推断,索引表和嵌套表相对规律性不强,可以当做特例放到二级记忆)
二级: record、object、array、index(table of 类型,table of index 类型),在基础记忆的基础上加上index,在把index当做特例处理展开就容易记忆了,如果放在一级记忆了,增加了一级记忆的负担,且使一级记忆的规律性不强。
三级:这级记忆可以通过多角度的展开分析,比如:
| 名称 | |
| 记录类型 | 在过程内使用 |
| 索引表 | |
| 嵌套表 | 在过程外也可以使用 |
| 复合类型嵌套表 | |
| 可变数组 |
。当然你可以有更多的规律去发掘和总结,这样更能丰富理解加强记忆。
练习
1
create table tb3(id ty1);
insert into tb3(id) values(ty1(1,1,1))
select * from tb3
declare
a ty1:=ty1(2,1,1);
begin
insert into tb3(id) values(a);
end;
![]()
2
create table tb1(id int,v1 int);
insert into tb1(id,v1) values(1,11)
insert into tb1(id,v1) values(2,13)
select * from tb1
declare
type type_reord is record(id int,v1 int);
v_temp type_reord;
begin
v_temp.id :=3;
v_temp.v1:=13;
insert into tb1(id,v1) values(v_temp.id,v_temp.v1);
end;
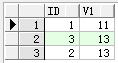
3
create table tb1(id int,v1 int);
insert into tb1(id,v1) values(1,11)
insert into tb1(id,v1) values(2,12)
select * from tb1
declare
type type_reord is record(id tb1.id%type,v1 tb1.v1%type);
v_temp type_reord;
begin
v_temp.id :=3;
v_temp.v1:=13;
--insert into tb1(id,v1) values(v_temp.id,v_temp.v1);
insert into tb1 values v_temp;
end;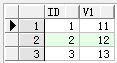
4
create table tb1(id int,v1 int);
insert into tb1(id,v1) values(1,11)
insert into tb1(id,v1) values(2,12)
select * from tb1
declare
type type_reord is record(id int,v1 int);
v_temp type_reord;
begin
v_temp.id :=3;
v_temp.v1:=13;
--insert into tb1(id,v1) values(v_temp.id,v_temp.v1);
insert into tb1 values v_temp;
end;
5 嵌套表
create or replace type type_table_row as table of int unique
create table tb1(id type_table_row,v1 int)nested table id store as id_type_table_row;
select * from tb1
insert into tb1(v1) values(1)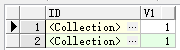
6 复合数据类型
create or replace type type_project as object(v1 int,v2 int);
create table tb1(id int, vs type_project)
insert into tb1(id,vs) values(1,type_project(11,21))
select * from tb1 ![]()
个人理解
这些结合本质上就是一些常用的结构,和语言的集合不起来,都相对的简单得多。因为表本身就是一种集合,这里只不过是一些特别的结构,方便使用。对语法的使用上可能没有语言的使用那么容易,不过知道了结构本质的思想,你就试着使用,用你理解和推断的语法去使用,往往就是好用的。我上面的实验中很多就是凭自己的推断做的实验(没有太阅读语法的细节),结果就好用了。
