目录
一、简介
ElasticSearch:智能搜索,分布式的搜索引擎
是ELK的一个组成,是一个产品,而且是非常完善的产品,ELK代表的是:E就是ElasticSearch,L就是Logstach,K就是kibana
E:ElasticSearch 搜索和分析的功能 ES的底层就是Lucene,ES是分布式的
L:Logstach 搜集数据的功能,类似于flume(使用方法几乎跟flume一模一样),是日志收集系统
K:Kibana 数据可视化(分析),可以用图表的方式来去展示,文不如表,表不如图,是数据可视化平台

二、为什么不用Lucene?
因为Lucene有两个难以解决的问题,
1)数据越大,存不下来,就需要多台服务器存数据,Lucene不支持分布式的,那就需要安装多个Lucene,然后通过代码来合并搜索结果。这样很不好
2)数据要考虑安全性,一台服务器挂了,那么上面的数据不就消失了。ES是分布式的集群,每一个节点其实就Lucene,当用户搜索的时候,会随机挑一台,然后这台机器自己知道数据在哪,不用我们管这些底层
三、ES优点及作用
1.分布式的功能
2、数据高可用,集群高可用
3.API更简单,API更高级。
4.支持的语言很多,支持PB级别的数据
5.完成搜索的功能和分析功能,基于Lucene,隐藏了Lucene的复杂性,提供简单的API
作用:
1)全文检索:
类似 select * from product where product_name like '%牙膏%',百度效果(电商搜索的效果)
2)结构化搜索:
类似 select * from product where product_id = '1'
3)数据分析
类似 select count (*) from product
四、核心概念
1、NRT(Near Realtime)近实时:近实时,写入和查询数据是近实时的,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
2、 cluster集群:ES是一个分布式的系统,ES直接解压不需要配置就可以使用,在hadoop1上解压一个ES,在hadoop2上解压了一个ES,接下来把这两个ES启动起来。他们就构成了一个集群。配置文件的clustername 如果这个值是一样的就属于同一个集群,不一样的值就是不一样的集群。
3、Node节点:就是集群中的一台服务器
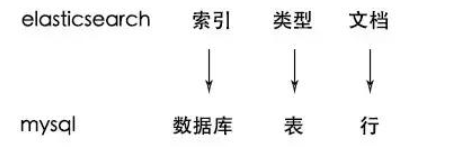
4、index 索引(索引库):使用Mysql或者Oracle的时候,为了区分数据,我们会建立不同的数据库,库下面还有表的。ES中的索引非传统索引的含义,ES中的索引是存放数据的地方,是ES中的一个概念词汇。index类似于我们Mysql里面的一个数据库 create database user; 好比就是一个索引库。
5、type类型:类型是用来定义数据结构的,在每一个index下面,可以有一个或者多个type,好比数据库里面的一张表。相当于表结构的描述,描述每个字段的类型。
6、document:文档就是最终的数据了,可以认为一个文档就是一条记录。是ES里面最小的数据单元,就好比表里面的一条数据
7、Field 字段:好比关系型数据库中列的概念,一个document有一个或者多个field组成。
8、shard:分片,一台服务器,无法存储大量的数据,ES把一个index里面的数据,分为多个shard,分布式的存储在各个服务器上面。
kafka:为什么支持分布式的功能,因为里面是有topic,支持分区的概念。所以topic A可以存在不同的节点上面。就可以支持海量数据和高并发,提升性能和吞吐量
9、replica:副本,为了保证数据的安全,引入了replica的概念,跟hdfs里面的概念是一个意思。在ES集群中,一模一样的数据有多份,能正常提供查询和插入的分片我们叫做 primary shard,其余的我们就管他们叫做 replica shard(备份的分片)
当我们去查询数据的时候,我们数据是有备份的,它会同时发出命令让我们有数据的机器去查询结果,最后谁的查询结果快,我们就要谁的数据(这个不需要我们去控制,它内部就自己控制了)
总结:
在默认情况下,我们创建一个库的时候,默认会帮我们创建5个主分片(primary shrad)和5个副分片(replica shard),所以说正常情况下是有10个分片的。
同一个节点上面,副本和主分片是一定不会在一台机器上面的,就是拥有相同数据的分片,是不会在同一个节点上面的。
所以当你有一个节点的时候,这个分片是不会把副本存在这仅有的一个节点上的,当你新加入了一台节点,ES会自动的给你在新机器上创建一个之前分片的副本。
五、举例理解
比如一首诗,有诗题、作者、朝代、字数、诗内容等字段,那么首先,我们可以建立一个名叫 Poems 的索引,然后创建一个名叫 Poem 的类型,类型是通过 Mapping 来定义每个字段的类型。
比如诗题、作者、朝代都是 Keyword 类型,诗内容是 Text 类型,而字数是 Integer 类型,最后就是把数据组织成 Json 格式存放进去了。


Keyword 类型是不会分词的,直接根据字符串内容建立反向索引,Text 类型在存入 Elasticsearch 的时候,会先分词,然后根据分词后的内容建立反向索引。keyword直接建立反向索引,text先分词,后建立反向索引。
六、ES安装、集群安装
七、ES分布式原理
在 Elasticsearch 中,是master-slave架构。节点是对等的,节点间会通过自己的一些规则选取集群的 Master,Master 会负责集群状态信息的改变,并同步给其他节点。

这样写入性能会不会很低???注意,只有建立索引和类型需要经过 Master,数据的写入有一个简单的 Routing 规则,可以 Route 到集群中的任意节点,所以数据写入压力是分散在整个集群的。
八、ElasticSearch常用api
1、索引操作
POST的方式进行修改数据,POST是局部更新数据,别的数据不动。PUT是全局更新
一、创建
#创建一个haha索引,索引名不能有大写字母
PUT /haha
PUT /indextest
{
"settings":
{
"number_of_replicas": 1,
"number_of_shards": 5
}
}
二、查询
#查看索引配置信息
GET indextest/_settings
GET poem,indextest/_settings
#查询所有
GET _all
#查看健康状态
GET _cat/health
#查询所有索引
GET _cat/indices
三、删除
DELETE /索引/类型/ID # 删除指定索引下的id
curl -XDELETE 'http://hdp-1:9200/search2/article2/1'
DELETE /haha #删除索引
POST blog/_close #关闭索引,无法进行插入数据
POST blog/_open #重新打开索引2、文档操作
一、创建
POST(PUT) /索引/类型/ID
{
//参数
}
curl -XPOST 'http://hdp-1:9200/search/article/1' -H 'Content-Type: application/json' -d '{
"title": "Test1",
"tags" : "test",
"summary" : "test",
"content" : "test1 content",
"pubtime":"0"
}'
POST(PUT) /poem/text/1 #可以不指定ID,会自动生成一个字符数字组合
{
"title":"静夜思",
"num":"4",
"author":"libai"
}
二、查询
GET /索引/类型/ID
curl -XGET 'http://hdp-1:9200/search2/article2/1'
--- 查询所有 linux6以后版本加json
curl -XGET 'http://hdp-1:9200/search2/article2/_search' -H 'Content-Type: application/json' -d '{
"query" : {
"match_all" : { }
}
}'
#查询指定索引类型id
GET /poem/text/1
#查询所有
GET _search
{
"query": {
"match_all": {}
}
}
HEAD poem/text/3 #存在返回200 ok 不存在返回404 not found
#GET poem/text/_mget #获取多个id的文档
{
"ids":["1","2"]
}
#查询某个索引下的文档
GET poem/_search3、term查询:
term查询用于查找指定字段中包含指定分词的文件,只有当查询分词和文档中的分词精确匹配时才被检索到。
如果没有使用ik分词器,中文i而一个字算一个词,只能单字查找
注意,经过分词后英文单词变成了小写,比如”Java”词项变成了”java“
GET blog/_search
{
"query": {
"term": {
"title": {
"value": "介"
}
}
}
}
#多个字段
GET poem/_search
{
"query": {
"terms": {
"title":
["夜","静"]
}
}
}4、match查询
与term精确查询不同,对于match查询,只要被查询字段中存在任何一个词项被匹配,就会搜索到该文档。
GET poem/text/_search
{
"query": {
"match": {
"title": "静si夜"
}
}
}重建新文档替换掉旧文档,版本会加1。created标识为 false,因为同索引同类型下已经存在同ID的文档。在ES内部,_version为1的文件已经被标记“删除”,并添加了一个完整的新文档。旧文档不会立即消失,但是不能再访问它。
更新字段值:
POST poem/text/4/_update
{
"script": {
"source": "ctx._source.title=\"jingyesi\""
}
}添加字段:(与更新区别在于字段是否存在)
POST poem/text/4/_update
{
"script": "ctx._source.posttime=\"2018-01-09\""
}查询更新
POST blog/_update_by_query{ "script": { "source": "ctx._source.category=params.category", "lang":"painless", "params":{"category":"git"} }, "query":{ "term": {"title":"git"} }}九、DSL语言
ES最主要是用来做搜索和分析的。所以DSL还是对于ES很重要的
下面我们写的代码都是RESTful风格
query DSL:domain Specialed Lanaguage 在特定领域的语言
#dsl match查询是一个标准查询
#查询名字为yellowgua,价格降序、分页
GET /product/mail/_search
{
"query": {
"match": {
"name": "yellowgua"
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
],
"from": 0, #0:第一个数据开始
"size": 2 #2:每页几条数据
}案例:搜索名称里面包含yellowgua的,并且价格大于25元的商品
相当于 select * form product where name like %yellowgua% and price >25;
如果需要多个查询条件拼接在一起就需要使用bool过滤:用来合并多个过滤条件查询结果的布尔逻辑,其中有:
must :多个查询条件的完全匹配,相当于 and。
must_not :多个查询条件的相反匹配,相当于 not。
should:至少有一个查询条件匹配,相当于 or。
这些参数可以分别继承一个过滤条件或者一个过滤条件的数组
十、路由机制
1、document路由到shard理解及原理
在es中,一个index会被分片,一个index中存在很多document,这个document存放在不同的shard,而一个document只能存在于一个primary shard中。当客户端创建一个document并存入es时,es内部就需要决定这个document存于那一个primary shard,这就是es中的document 路由分发。
2、路由算法
shard = hash(routing) % number_of_primary_shards
决定一个document在哪个shard上,最重要的一个值就是routing值,默认是_id,也可以手动指定,相同的routing值,产出的hash值一定是相同的。
我们可以在发送请求的时候,手动指定一个routing value,比如说:put /index/type/id?routing=user_id。手动指定routing value是很有用的,可以保证某一类document一定被路由到一个shard上去,那么在后续进行应用级别的负载均衡,以及提升批量读取的性能的时候是很有帮助的。
POST poem/text/6?routing=id #创建(routing value任意指定)
{
"title":"除夕",
"num":"10",
"author":"xin"
}
GET poem/text/6?routing=id #查询,需要带routing
DELETE poem/text/6?routing=id #删除,需要带routing十一、版本冲突
如果两个线程同时修改一个文档,这时就会发生冲突。
每个文档都有一个 _version 号,当文档被修改时版本号递增。我们可以利用 _version 号来确保 应用中相互冲突的变更不会导致数据丢失。通过指定想要修改文档的 version 号来达到这个目的。 如果该版本不是当前版本号,我们的请求将会失败。
#根据指定版本修改,如果版本不对,报错无法修改
PUT website/blog/1?version=1
{
"title":"adction",
"name":"wang"
}外部系统使用版本控制,Elasticsearch 中通过增加 version_type=external 方式指定外部版本号,如果外部版本号是否大于当前文档版本,则可以执行更新操作。
#5必须 >= 外部版本
PUT /website/blog/2?version=5&version_type=external
{
"title": "My first external blog entry",
"text": "Starting to get the hang of this..."
}十二、Mapping映射
索引(index)相当于数据库,类型(type)相当于数据表,映射(Mapping)相当于数据表的表结构。
ElasticSearch中的映射(Mapping)用来定义一个文档,可以定义所包含的字段以及字段的类型、分词器及属性等等。映射可以分为动态映射和静态映射。
1、动态映射:ElasticSearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
PUT map
GET map/_mapping #查看空的mapping
PUT map/it/1
{
"name":"mathbook",
"id":1,
"publictime":"2019-11-8"
}2、静态映射:创建index的时候指定各个字段类型等,自定义类型
PUT map
{
"mappings": {
"outdoor":{
"properties": {
"name":{"type": "text"},
"age":{"type": "long"},
"birthday":{"type": "date"}
}
}
}
}
GET map/_mapping