文章目录
从redis源码看数据结构(二)字符串
作者今年大三,正在准备明年的春招,文章中有写得不对的,希望大家及时指出文章中的错误的地方,大家一起努力!
一,redis中的字符串
字符串是redis中最基本的数据结构,redis使用key作为存取value的唯一标识符,而key的通俗理解就是字符串,redis的字符串分为两类:
- 二进制安全 ----》是指字符串中的所有字符均可用256个字符编码
- 非二进制安全
key使用的是非二进制安全的
1.基本数据结构
Redis内部实现了字符串类型,由sds.h和sds.c定义。
// sds 类型 声明类型别名,可以这么理解
// typedef char *String
typedef char *sds;
// sdshdr 结构
struct sdshdr {
// buf 已占用长度
int len;
// buf 剩余可用长度
int free;
// 实际保存字符串数据的地方
char buf[];
};
可以看出,字符串在redis中的结构声明还是比较容易理解的,字符串类型在redis中是sds类型,在java中就是我们的String
// sds 类型 声明类型别名,可以这么理解
// typedef char *String
typedef char *sds;
实际上保存字符串内容的还是一个字符数组
// 实际保存字符串数据的地方
char buf[];
2.创建一个字符串
创建一个空串
/*
* 创建一个只包含空字符串 "" 的 sds
*
* T = O(N)
*/
sds sdsempty(void) {
// O(N)
return sdsnewlen("",0);
}
根据给定字符串创建sds
/*
* 根据给定字符串内容 ,创建 sds
* 如果 init 为 NULL ,那么创建一个 buf 内只包含 \0 终结符的 sds
*
* T = O(N)
*/
sds sdsnew(const char *init) {
size_t initlen = (init == NULL) ? 0 : strlen(init);
return sdsnewlen(init, initlen);
}
上面这两个方法是redis中创建字符串sds的函数,他们其实还是主要通过以下函数实现
init:传入的字符串
sds sdsnewlen(const void *init, size_t initlen) {
struct sdshdr *sh;
//分配内存
// O(N)
if (init) {
sh = zmalloc(sizeof(struct sdshdr)+initlen+1);
} else {
sh = zcalloc(sizeof(struct sdshdr)+initlen+1);
}
// 内存不足,分配失败
if (sh == NULL) return NULL;
sh->len = initlen;
sh->free = 0;
// 如果给定了 init 且 initlen 不为 0 的话
// 那么将 init 的内容复制至 sds buf(字符串内容存在于字符数组buf中)
// O(N)
if (initlen && init)
memcpy(sh->buf, init, initlen);
// 加上终结符
sh->buf[initlen] = '\0';
// 返回 buf 而不是整个 sdshdr
return (char*)sh->buf;
}
注意,如果不是空串就是init长度大于0,则需要将字符串内容存与字符数组buf,buf末端以’\0’结束
// 如果给定了 init 且 initlen 不为 0 的话
// 那么将 init 的内容复制至 sds buf(字符串内容存在于字符数组buf中)
// O(N)
if (initlen && init)
memcpy(sh->buf, init, initlen);
// 加上终结符
sh->buf[initlen] = '\0';
3.字符串拼接
将一个字符数组拼接到sds末尾
/*
* 将一个 char 数组拼接到 sds 末尾
*
* T = O(N)
*/
sds sdscat(sds s, const char *t) {
return sdscatlen(s, t, strlen(t));
}
看看sdscatlen这个函数,真正完成拼接,也可以完成两个sds的拼接
/*
* 按长度 len 扩展 sds ,并将 t 拼接到 sds 的末尾
* t:需要拼接的sds
* len:t长度
* T = O(N)
*/
sds sdscatlen(sds s, const void *t, size_t len) {
struct sdshdr *sh;
//当前sds长度
size_t curlen = sdslen(s);
// O(N)
// 数组扩容,对 sds 的 buf 进行扩展,扩展的长度不少于需要增加的空间长度
s = sdsMakeRoomFor(s,len);
//扩展失败
if (s == NULL) return NULL;
// 复制到sds末尾
// O(N)
memcpy(s+curlen, t, len);
// 更新 len 和 free 属性
// O(1)
sh = (void*) (s-(sizeof(struct sdshdr)));
//拼接后长度
sh->len = curlen+len;
//拼接后可用长度
sh->free = sh->free-len;
// 终结符
// O(1)
s[curlen+len] = '\0';
return s;
}
扩容函数
/*
* 对 sds 的 buf 进行扩展,扩展的长度不少于 addlen 。
*
* T = O(N)
*/
sds sdsMakeRoomFor(
sds s, //需要扩展的sds
size_t addlen // 需要增加的空间长度
)
{
//声明新旧sds
struct sdshdr *sh, *newsh;
//原sds buf剩余空间
size_t free = sdsavail(s);
//声明新旧长度
size_t len, newlen;
// 剩余空间可以满足需求,无须扩展
if (free >= addlen) return s;
//需要扩容,开始扩容流程
sh = (void*) (s-(sizeof(struct sdshdr)));
// 目前 buf 长度
len = sdslen(s);
// 新 buf 长度 = 旧buf长度 + 需要扩展的长度
newlen = (len+addlen);
// 如果新 buf 长度小于 SDS_MAX_PREALLOC 长度
// 那么将 buf 的长度设为新 buf 长度的两倍
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
// 新长度
newsh = zrealloc(sh, sizeof(struct sdshdr)+newlen+1);
//扩展失败
if (newsh == NULL) return NULL;
//计算新sh的可用长度
newsh->free = newlen - len;
return newsh->buf;
}
扩展大小是(原buf长度 + 拼接字符串的长度)* 2
// 目前 buf 长度
len = sdslen(s);
// 新 buf 长度 = 旧buf长度 + 需要扩展的长度
newlen = (len+addlen);
// 如果新 buf 长度小于 SDS_MAX_PREALLOC 长度
// 那么将 buf 的长度设为新 buf 长度的两倍
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
二,java中的字符串String
对于redis的sds咱们就研究到这里了,毕竟笔者也比较菜,所以我们还是回到我们的本职工作,搞好java
1.String类结构
String是一个不可变类,不可被继承,可以被序列化,可以比较大小,是一个有序字符的序列
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
//........
}
2. String数据结构定义
java中的String字符串对象,实际上也是一个字符数组
private final char value[];
注意,该字符数组是不可变数组,final修饰,是不可变的
再谈不可变
可能有人说下面这段代码不就可以反驳String是不可变类这个观点了吗?
String s = "ABCabc";
System.out.println("s = " + s);
s = "123456";
System.out.println("s = " + s);
输出:
s = ABCabc
s = 123456
这样String对象s不就改变了吗?其实不是这样的
首先创建一个String对象s,然后让s的值为“ABCabc”, 然后又让s的值为“123456”。 从打印结果可以看出,s的值确实改变了。那么怎么还说String对象是不可变的呢? 其实这里存在一个误区: s只是一个String对象的引用,并不是对象本身。对象在内存中是一块内存区,成员变量越多,这块内存区占的空间越大。引用只是一个4字节的数据,里面存放了它所指向的对象的地址,通过这个地址可以访问对象。
也就是说,s只是一个引用,它指向了一个具体的对象,当s=“123456”; 这句代码执行过之后,又创建了一个新的对象“123456”, 而引用s重新指向了这个心的对象,原来的对象“ABCabc”还在内存中存在,并没有改变。内存结构如下图所示:
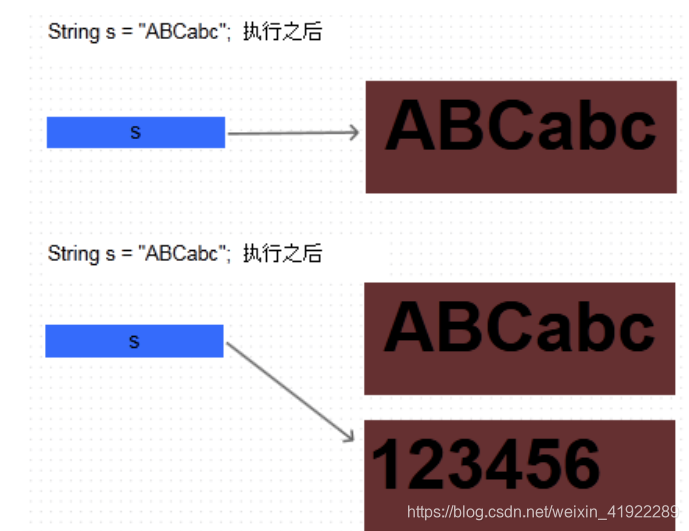
实际上ABCabc,和123456在jvm中是存放在字符串常量池中的一个String Table中的一个引用
3.构造方法
构造空串
public String() {
this.value = "".value;
}
指定字符数组构造
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
4.String常用方法
判断是否是空串和返回String长度
public int length() { //所以String的长度就是一个value的长度
return value.length;
}
public boolean isEmpty() { //当char数组的长度为0,则代表String为"",空字符串
return value.length == 0;
}
charAt函数,ChatAt是实现CharSequence 而重写的方法,是一个有序字符集的方法
//获取指定下标的字符
//T:O(1)
public char charAt(int index) {
//下标检查
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
//字符数组,直接按下标取字符
return value[index];
}
codePointAt函数
//返回String对象的char数组index位置的元素的ASSIC码(int类型)
public int codePointAt(int index) {
//检查下标
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
//返回指定位置字符的ASCII码
return Character.codePointAtImpl(value, index, value.length);
}
equals方法
- 先判断是否是同一对象
- 在判断是否是String类型
- 转为String后,先比较长度
- 最后一个字符一个字符的比较
//判断两个字符串对象的内容是否相同
public boolean equals(Object anObject) {
//先判断是否是同一个对象
if (this == anObject) {
return true;
}
//判断是否是String类型
if (anObject instanceof String) {
//转为String类型
String anotherString = (String)anObject;
//获取长度
int n = value.length;
//先判断长度是否相同
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
//一个字符一个字符的比较
while (n-- != 0) {
//只要不同就返回false
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
补充:关于java中equals和 ‘==’和hashcode的关系:
public static void main(String[] args) {
String s1 = "abc";
String str3 = new String("abc");
System.out.println(s1.equals(str3));//true
System.out.println(s1 == str3);//false
System.out.println(s1.hashCode() == str3.hashCode());//true
}
- 如果两个对象equals()方法相等则它们的hashCode返回值一定要相同,如果两个对象的hashCode返回值相同,但它们的equals()方法不一定相等。
- 两个对象的hashCode()返回值相等不能判断这两个对象是相等的(可能刚好出现哈希冲突,映射到哈希表的同一位置),但两个对象的hashcode()返回值不相等则可以判定两个对象一定不相等。
- 若 == 返回true(同一对象),则两边的对象的hashCode()返回值必须相等,若 == 返回false,则两边对象的hashCode()返回值可能相等,也可能不等
所以,java中重写equals也应尽量重写hashcode的原因如下:
当 equals 方法被重写时通常有必要重写 hashCode 方法来维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码,如果不这样做的话就会违反 hashCode 方法的常规约定,从而导致该类无法结合所有基于散列的集合一起正常运作,这样的集合包括 HashMap、HashSet、Hashtable 等。
hashCode 方法的常规约定如下:
- 程序执行期间只要对象 equals 方法比较操作所用到的信息没有被修改,则对这同一个对象无论调用多次 hashCode 方法都必须返回同一个整数。
- 如果两个对象根据 equals 方法比较是相等的则调用这两个对象中任意一个对象的 hashCode 方法都必须产生同样的整数结果。(对应上文中,两个对象equals()方法相等则它们的hashCode返回值一定要相同)
- 如果两个对象根据 equals 方法比较是不相等的,则调用这两个对象中任意一个对象的 hashCode 方法不一定要产生相同的整数结果(对应上文中,equals不同,hashcode可以相同可以不同)
忽略大小写的equals
public boolean equalsIgnoreCase(String anotherString) {
return (this == anotherString) ? true
: (anotherString != null)
&& (anotherString.value.length == value.length)
&& regionMatches(true, 0, anotherString, 0, value.length);
}
字符串比较的compareTo方法
public int compareTo(String anotherString) {
//当前String对象的长度
int len1 = value.length;
//参数即要比较对象的长度
int len2 = anotherString.value.length;
//取最小长度
int lim = Math.min(len1, len2);
//分别转为字符数组
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
//从较短字符串的第一个字符开始比较
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
//只要其实一个不相等,返回字符ASSIC的差值,int类型
if (c1 != c2) {
return c1 - c2;
}
k++;
}
//如果两个字符串同样位置的索引都相等,返回长度差值,完全相等则为0
return len1 - len2;
}
s1的ASII码是97 + 98 + 99
s2的ASII码是97 + 98 + 100
s1 < s2,所以返回-1
String s1 = "abc";
String s2 = "abd";
System.out.println("abc : " + Integer.valueOf(s1.compareTo(s2)));//-1
补充:Comparable 和 Comparator的理解
-
comparable是一个单方法的接口,支持当前对象和参数对象的比较
public interface Comparable<T> { public int compareTo(T o); }比较结果返回值
this < o //返回-1 this = o //返回0 this > o //返回1 -
comparator接口是多方法接口,也可以用来作为一个比较器,但是这个比较器是两个参数对象之间的比较
int compare(T o1, T o2);结果返回
o1 > o2 //返回1 o1 = o2 //返回0 o1 < o2 //返回-1 -
两个接口都可以用来实现自定义比较器
indexOf函数
//返回目标字符串的下标
public int indexOf(int ch) {
return indexOf(ch, 0);
}
//从fromIndex开始,找到ch的下标
public int indexOf(int ch, int fromIndex) {
//max:字符串长度
final int max = value.length;
//检查fromIndex
if (fromIndex < 0) {
fromIndex = 0;
} else if (fromIndex >= max) {
//没找到ch
return -1;
}
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) {
final char[] value = this.value;
//从fromIndex开始往后遍历,直到找到ch,返回ch下标
for (int i = fromIndex; i < max; i++) {
if (value[i] == ch) {
return i;
}
}
//没找到返回-1
return -1;
} else {
return indexOfSupplementary(ch, fromIndex);
}
}
subString方法
//字符串截取,[beginIndex,endIndex)
public String substring(int beginIndex, int endIndex) {
//检查beginIndex
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
//检查endIndex
if (endIndex > value.length) {
throw new StringIndexOutOfBoundsException(endIndex);
}
//截取长度
int subLen = endIndex - beginIndex;
//检查截取长度
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
//如果刚好是0到this.value.length,就返回本字符串对象
//否则新new一个String对象,保证String不可变类这个特性
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}
截取字符串实质还是字符数组的移动
public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
5.String真的不可变吗?
public static void main(String[] args) {
//反射
String s = "abc";
System.out.println("反射前:"+s);
try {
Field value = String.class.getDeclaredField("value");
value.setAccessible(true);
char[] v = (char[]) value.get(s);
v[0] = '5';
System.out.println("反射后:"+s);
} catch (Exception e) {
e.printStackTrace();
}
}
结果:
反射前:abc
反射后:5bc
通过反射,我们改变了底层的字符数组的值,实现了字符串的 “不可变” 性,这是一种骚操作,不建议这么使用,违反了 Java 对 String 类的不可变设计原则,会造成一些安全问题。
