目录
(3)lag(col,n)、lead(col,n)、ntile(n) 、first_value()、last_value() 分析函数的使用
一、Oracle--数据迁移备份
Oracle--备份和恢复,导入与导出
在项目过程中:
开发环境(测试环境) -----上线-----> 生产系统,生产环境
程序,业务逻辑,口径 -----上线-------> 生产环境
制定上线方案
上线:就是迁移
从开发库导出 ------------>导入生产库
oracle数据导入导出的方法:
(1)、命令的方式导入与导出
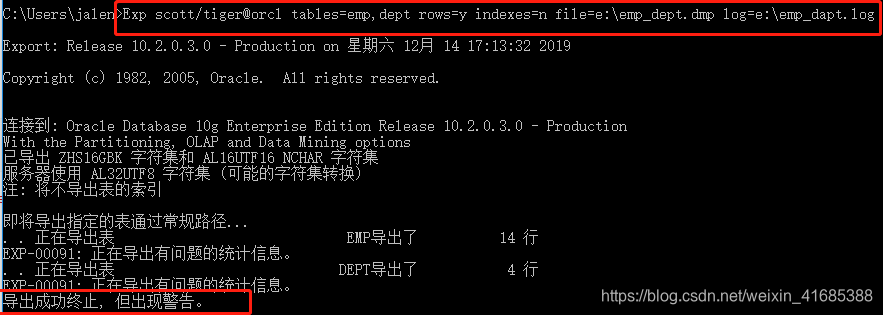
- 语句:Exp scott/tiger@orcl tables=emp,dept rows=y indexes=n file=e:\emp_dept.dmp log=e:\emp_dapt.log
- 解释:导出 用户/密码@服务名 表=表1,2 记录=导出 索引=不导出 数据地址=e:\emp_dept.dmp 日志地址=e:\emp_dapt.log
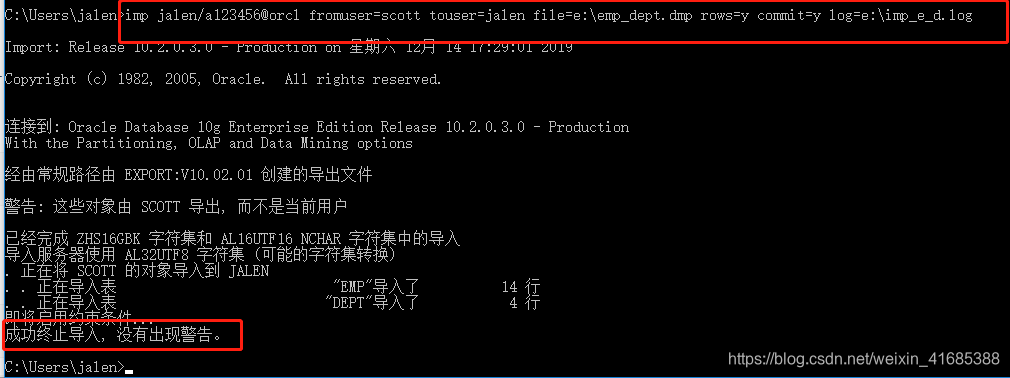
- 语句:imp jalen/a123456@orcl fromuser=scott touser=jalen file=e:\emp_dept.dmp rows=y commit=y log=e:\imp_e_d.log
- 解释:导入 用户/密码@服务名 来自于=用户 导到=用户 文件地址=e:\emp_dept.dmp 记录=导入 提交事务=是 日志地址=...
| 参数 |
说明 |
| BUFFEER |
用来取数据行的缓冲区的大小,单位为字节。 |
| FILE |
导出数据存储的文件名。DMP |
| COMPRESS |
导出 是否应该 压缩有碎片的 段成一个 范围,这将会 影响STORAGE 子句。选项:Y 或 N。 |
| GRANTS |
导出时否要导出数据库对象上的授权。选项:Y 或 N。 |
| INDEXES |
是否要导出表上的索引。选项:Y 或 N。 |
| ROWS |
是否应导出行。如它为‘N’,那么在导出文件中仅生成数据库对象的 DDL。选项:Y 或 N。 |
| CONSTRAINTS |
是否导出表的约束,选项:Y 或 N。 |
| FULL |
如设为‘Y’,那么将执行一个整个数据库导出操作。如果不设置,默认值为 N。选项:Y 或 N。 |
| OWNER |
要导出的一系列数据库帐号,然后执行这些帐号的 USER 导出操作。 |
| TABLES |
要导出的一系列表;执行这些表的 TABLE 导出操作。 |
| LOG |
导出日志将要写入的文件的名字 |
(2)、SQLPLUS导入,执行sql脚本(增删改)
C:\Users\jalen>SQLPLUS scott/tiger@orcl
SQL> @e:\smpl_ora_ok.sql
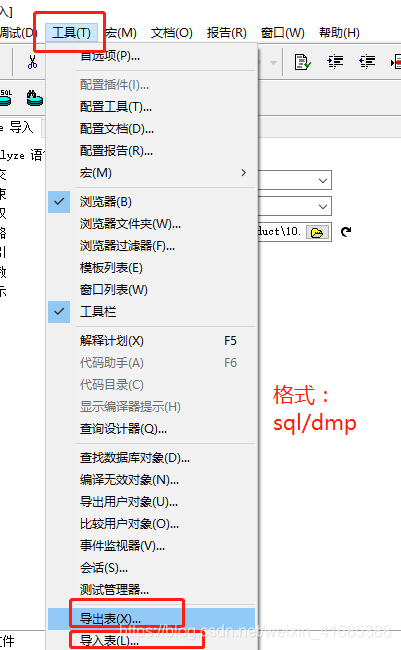
(3)、PL/SQL客户端导入与导出
Oracle导出 -------- 后缀名为DMP
SQL插入------后缀名为SQL
案例:
erp.dmp 源数据文件 ------导入到scott用户
使用system给scott用户授权 DBA角色
C:\Users\Administrator>sqlplus system/a123456@orcl
SQL> grant dba to scott;
授权成功。
SQL> exit
C:\Users\jalen>imp scott/tiger@orcl fromuser=erp touser=scott file=e:\erp.dmp rows=y commit=y log=c:\imp_erp.log
二、Oracle--case when 行转列
case when 语法结构
case 列名
when 条件值1 then 选项1
when 条件值2 then 选项2.......
else 默认值 end
-- Oracle 行列转换
-- 数据,使用scott用户的emp表数据
select * from scott.emp t where rownum<=50;
-- 表字段说明:
-- empno, ename, job, mgr, hiredate, sal, comm, deptno
-- 员工编号,员工姓名,岗位,领导编号,入职日期,薪资,奖金,部门编号
-- 需求:查询scott.emp表中,每个部门的人数,并进行行转列显示
select
max(case when deptno=10 then total else 0 end) "10",
max(case when deptno=20 then total else 0 end) "20",
max(case when deptno=30 then total else 0 end) "30"
from (select deptno,count(*) total from scott.emp group by deptno);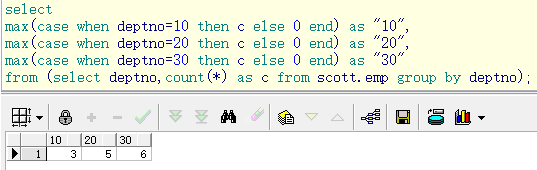 ·
·
三、Oracle数据合并(存在则更新,不存在就插入)
-- Merge into
MERGE INTO table_name alias1
USING table|view|sub_query alias2
ON (join condition)
WHEN MATCHED THEN UPDATE SET col1 = col_val1, col2 = col2_val
WHEN NOT MATCHED THEN INSERT (column_list) VALUES (column_values);
案例:
---创建表
create table jalen.test_merge_A(
empno number,
ename varchar2(30),
sal number);
---创建表
create table jalen.test_merge_B(
empno number,
ename varchar2(30),
sal number);
------插入数据
insert into test_merge_A values(1122,'AA',1500);
insert into test_merge_A values(1133,'BB',1600);
insert into test_merge_A values(1144,'CC',1700);
insert into test_merge_A values(1155,'DD',1800);
insert into test_merge_B values(1144,'DD',2500);
insert into test_merge_B values(1166,'EE',5000);
insert into test_merge_B values(1177,'FF',3000);
insert into test_merge_B values(1122,'AA',3000);
-----查看数据
select * from test_merge_A;
select * from test_merge_B;
--将B表的数据合并到A表,如果存在则更新,如果不存在则插入
merge into test_merge_A a
using test_merge_B b
on (a.empno=b.empno)
when matched then update set a.ename=b.ename,a.sal=b.sal
when not matched then insert (a.empno,a.ename,a.sal) values (b.empno,b.ename,b.sal);
-----查看数据
select * from test_merge_A;四、Oracle递归用法
递归语法:
select [level],column,expr... from table
[where condition]
start with condition
connect by [prior column1 = column2 向下
| column1 = prior column2]; 向上
伪列 level 用于返回层次查询的层次(1:根行 2:第2级行 3:第3级行...)
start with 用于指定层次关系查询的根行 ;决定了爬树的起点
connect by 用于指定父行和子行的关系 当定义父行和子行的关系时,必须使 用prior关键字,决定了爬树的方向:
prior 用于指定哪个是父级列
案例:
-- Oracle 递归查找
-- 数据,使用scott用户的emp表数据
select * from scott.emp t where rownum<=50;
-- 表字段说明:
-- empno, ename, job, mgr, hiredate, sal, comm, deptno
-- 员工编号,员工姓名,岗位,领导编号,入职日期,薪资,奖金,部门编号
-- 需求1:向上递归查出empno=7369的所有上级领导的编号和姓名
-- 7369-->7902-->7566--> 7839
select empno,ename from scott.emp
start with empno = 7369
connect by empno = prior mgr;
-- 需求2:向下递归查出7839的所有‘10’部门的下属及层级
select empno,ename,deptno from scott.emp
where deptno = 10
start with empno = 7839
connect by prior empno = mgr;五、分析(窗口)函数
分析函数是Oracle专门用于解决复杂报表统计需求的功能强大的函数,
它可以在数据中进行分组然后计算基于组的某种统计值,并且每一组的每一行都可以返回一个统计值
1、分析函数语法
function_name(<argument>,<argument>...) over(<partition_Clause><order by_Clause><windowing_Clause>);
function_name():函数名称
argument:参数
over( ):开窗函数
partition_Clause:分区子句,数据记录集分组,group by...
order by_Clause:排序子句,数据记录集排序,order by...
windowing_Clause:开窗子句,定义分析函数在操作行的集合,三种开窗方式:rows、range、Specifying
注:使用开窗子句时一定要有排序子句!!!2、常见分析函数的使用说明
数据案例使用Oracle的scott用户下自带的emp表和dept表
(1)、聚合、累计类型分析函数使用
--(1)count(...) over(...) ;求各部门员工数
select
distinct e.deptno deptno,
d.dname dname,
count(*)over(partition by e.deptno,d.dname) totar
from scott.emp e join scott.dept d on e.deptno=d.deptno;
--(2)sum(...) over(...);求各部门员工递加的工资总和
select
ename,
deptno,
sum(sal) over(partition by deptno order by ename) sum_sal
from scott.emp;
--(3)avg(...) over(...);求各部门的平均工资
select
distinct deptno,
avg(sal)over(partition by deptno) avg_sal
from scott.emp;
--(4)min(...)/max(...)over(...);求各职位的最低和最高薪资
select
distinct job,
min(sal)over(partition by job) min_sal,
max(sal)over(partition by job) max_sal
from scott.emp;(2)、排名类型分析函数使用
--(1)、整体排名:rank()/row_number()/dense_rank() over(...);按照薪资降序整体排名
select emp.* ,
rank()over(order by sal desc) rank, --占空排名,跳跃排名,如 1-2-2-4-5
row_number()over(order by sal desc) row_number,--顺序递增(减)排名,如 1-2-3-4-5
dense_rank()over(order by sal desc) dense_rank --不占空排序,如1-2-2-3-4
from scott.emp;
--(2)、组内排名:rank()/row_number()/dense_rank() over(...);按照各部门内部薪资降序排名
select emp.* ,
rank()over(partition by deptno order by sal desc) rank, --占空排名,跳跃排名,如 1-2-2-4-5
row_number()over(partition by deptno order by sal desc) row_number,--顺序递增(减)排名,如 1-2-3-4-5
dense_rank()over(partition by deptno order by sal desc) dense_rank --不占空排序,如1-2-2-3-4
from scott.emp; (3)lag(col,n)、lead(col,n)、ntile(n) 、first_value()、last_value() 分析函数的使用
lag(列名,往前的行数n,[行数为null时的默认值,不指定为null]) --往前第n行
lead(列名,往后的行数n,[行数为null时的默认值,不指定为null]) --往后第n行
first_value取分组内排序后,截止到当前行,第一个值。
last_value取分组内排序后,截止到当前行,最后一个值。
ntile(n) 把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,ntile返回此行所属的组的编号
--(1)、 lag(col,n)、lead(col,n)使用
select ename,hiredate,
lag(hiredate,2,null) over(order by sal) lag,--往前第2行的值
lead(hiredate,2) over(order by sal) lead --往后第2行的值
from scott.emp;
--组内取往前/往后第n行的值
select ename,hiredate,
lag(hiredate,1,null) over(partition by deptno order by hiredate) lag,
lead(hiredate,1) over(partition by deptno order by hiredate) lead
from scott.emp; --(2)、first_value()、last_value()的使用
select ename,first_value(salary) over() from scott.emp;
select ename,first_value(salary) over(order by sal desc) from scott.emp;
select ename,first_value(salary) over(partition by job) from scott.emp;
select ename,first_value(salary) over(partition by job order by sal desc) from scott.emp;
select ename,last_value(ename) over() from scott.emp;
select ename,last_value(ename) over(order by sal desc) from scott.emp;
select job,ename,last_value(ename) over(partition by job) from scott.emp;
select job,ename,sal,last_value(ename) over(partition by job order by sal desc) from scott.emp;--(3)、ntile(n)使用
-- 按照薪资降序整体分成3组
select ename,sal,ntile(3) over(order by sal desc) from scott.emp;
-- 给个部门按照薪资降序分为2组
select deptno,ename,sal,ntile(2) over(partition by deptno order by sal desc) from scott.emp;还有更多分析函数,使用过程中再去查找使用吧!!!
有用的点一下关注,更多关于数据分析/大数据/数据库操作的知识相互交流学习!!!
