1、函数Max()的优化
SQL:EXPLAIN select max(payment_date) from payment;
优化之前:查询大概需要4ms。
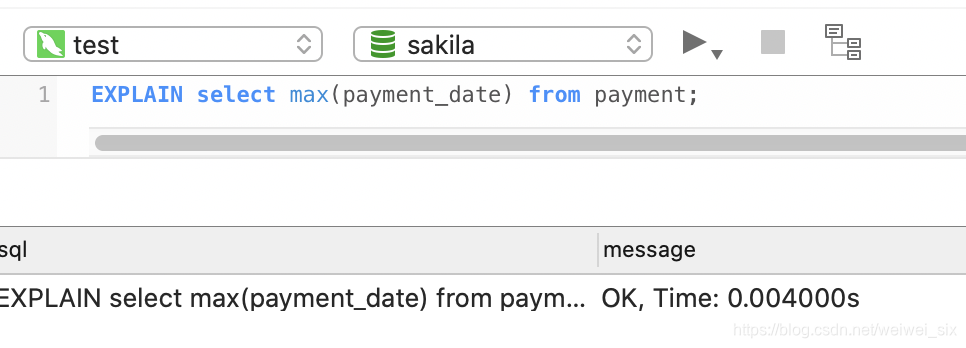
执行计划是这样的。

type为all。是最差的。
给字段payment_date 加上索引。查询几乎不耗时。
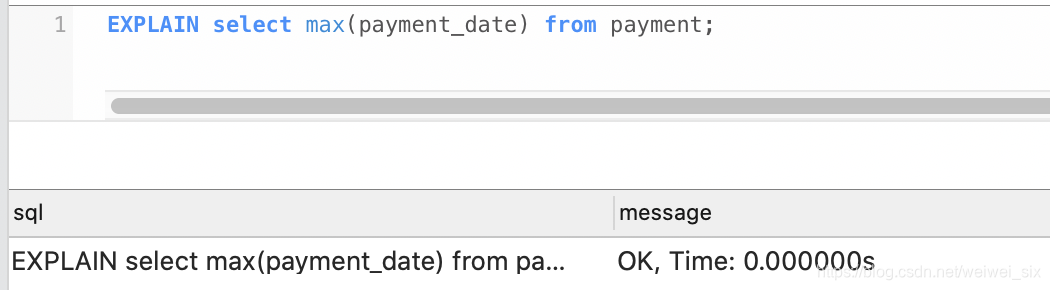
执行计划:

红字圈起来的意思是已经不能再进一步优化了。type也为null了。
2、函数Count()的优化
需求:在一条SQL中同时查处2006年和2007年电影的数量
SQL:select count(*) from film where release_year='2006' or release_year='2007';
查看执行计划:
mysql> explain select count(*) from film where release_year='2006' or release_year='2007';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | film | NULL | ALL | NULL | NULL | NULL | NULL | 1000 | 19.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
可以看到filtered值有19.00;表示满足条件记录的值只有百分之19。换成下面这种写法。
mysql> explain select count(release_year='2006' or null) as '06films',count(release_year='2007' or null) as '07films' from film;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | film | NULL | ALL | NULL | NULL | NULL | NULL | 1000 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)
3、group by优化
在 mysql中,当无法使用索引时,GROUP BY 有两种策略实现分组:临时表和文件排序。
mysql> explain select actor.first_name,actor.last_name,count(*) from film_actor f inner join actor using(actor_id) group by f.actor_id \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 200
filtered: 100.00
Extra: Using temporary; Using filesort
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: f
partitions: NULL
type: ref
possible_keys: PRIMARY,idx_fk_film_id
key: PRIMARY
key_len: 2
ref: sakila.actor.actor_id
rows: 27
filtered: 100.00
Extra: Using index
2 rows in set, 1 warning (0.00 sec)
可以看到 1.row 的 Extra: Using temporary; Using filesort。就是使用了这个。这样会很耗费性能。
mysql> explain select actor.first_name,actor.last_name,c.cnt
-> from actor inner join (
-> select actor_id,count(*) as cnt from film_actor group by actor_id
-> )as c using(actor_id) \G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: actor
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 200
filtered: 100.00
Extra: NULL
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
partitions: NULL
type: ref
possible_keys: <auto_key0>
key: <auto_key0>
key_len: 2
ref: sakila.actor.actor_id
rows: 27
filtered: 100.00
Extra: NULL
*************************** 3. row ***************************
id: 2
select_type: DERIVED
table: film_actor
partitions: NULL
type: index
possible_keys: PRIMARY,idx_fk_film_id
key: PRIMARY
key_len: 4
ref: NULL
rows: 5462
filtered: 100.00
Extra: Using index
3 rows in set, 1 warning (0.00 sec)
这样就避免了文件排序和临时表。
4、优化limit分页
Limit常用于分页处理,时长会伴随order by从句使用,因此大多时候回使用Filesorts这样会造成大量的IO问题。
例如LIMIT 1000,20这样的查询,这时MySQL 需要查询10020条记录然后只返回最后20条,前面10000条记录都将彼抛弁,这样的代价非常高。 如果所有的页面被访问的频率都相同,那么这样的查询平均需要访问半个表的数据。 要优化这种查询,要么是在页面中限制分页的数量,要么是优化大偏移量的性能。
优化此类分页查询的一个最简单的办法就是尽可能地使用索引覆盖扫描,而不是查询所有的列。 然后根据需要做一次关联操作再返回所需的列。
需求:查询影片id和描述信息,并根据主题进行排序,取出从序号50条开始的5条数据。
mysql> explain select film_id,description from sakila.film order by title limit 50,5 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1000
filtered: 100.00
Extra: Using filesort
1 row in set, 1 warning (0.00 sec)
优化步骤1:
使用有索引的列或主键进行order by操作,因为大家知道,innodb是按照主键的逻辑顺序进行排序的。可以避免很多的IO操作。
mysql> explain select film_id,description from sakila.film order by film_id limit 50,5 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: index
possible_keys: NULL
key: PRIMARY
key_len: 2
ref: NULL
rows: 55
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
可以看到走了索引的话就不会引起文件排序了。
优化步骤2、记录上次返回的主键, 在下次查询时使用主键过滤。(说明:避免了数据量大时扫描过多的记录)
上次limit是50,5的操作,因此我们在这次优化过程需要使用上次的索引记录值。
mysql> explain select film_id,description from sakila.film where film_id >55 and film_id<=60 order by film_id limit 1,5 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: NULL
rows: 5
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
可以看到 rows 只有5了。
