文章目录
一、事务
1.事务引出
事务广泛用于订单系统、银行系统等多种场景。
例如:
A用户和B用户是银行的储户,现在A要给B转账500元,那么需要做以下几件事:
检查A的账户余额>500元;
A账户中扣除500元;
B账户中增加500元。
正常的流程走下来,A账户扣了500,B账户加了500;
那如果A账户扣了钱之后,系统出故障了,A会白白损失了500,而B也没有收到本该属于他的500。
以上的案例中,隐藏着一个前提条件:A扣钱和B加钱,要么同时成功,要么同时失败。事务的需求就在于此。
2.事务定义
事务是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。
例如,银行转帐工作:从一个帐号扣款并使另一个帐号增款,这两个操作要么都执行,要么都不执行。所以,应该把他们看成一个事务。
事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性。
那么至少需要三个步骤:
(1)检查账户1的余额高于或者等于100美元;
(2)从账户1余额中减去100美元;
(3)在帐户2余额中增加100美元。
begin;
update bank1 set money = money - 100 where id = 1;
此时没有commit,查询时数据不会发生变化,即体现了事物的隔离性。
update bank2 set money = money + 100 where id = 1;
commit;
此时两个表中的数据均发生变化,一个减少100,一个增加100。
以上两步操作组成一个完整的事务。
开启事务后每次执行SQL语句后不会自动提交,要提交才能操作成功。
3.事务的四大特性(ACID)
(1)原子性(Atomicity):
一个事务被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性。
(2)一致性(Consistency):
数据库总是从一个一致性的状态转换到另一个一致性的状态。
在前面的例子中,一致性确保了,即使在执行两条update语句之间时系统崩溃,银行账户中也不会损失100美元,因为事务最终没有提交,所以事务中所做的修改也不会保存到数据库中。
(3)隔离性(Isolation):
通常来说,一个事务所作的修改在最终提交以前,对其他事务是不可见的。
在前面的例子中,当执行完第一update语句、第四条语句还未开始时,此时有另外的一个账户汇总程序开始运行,则其看到帐户1的余额并没有被减去100美元。
在一个命令行中,开启一个事务
begin;
update goods set name = 'palyer' where id = 3;
未提交
在另一个命令行中执行另一个操作
update goods set name = 'Player' where id = 3;
此时会出现堵塞,因为前一个命令行未提交事务,即前一个在操作的时候,其他对该数据库的操作会被锁定,从而保证了数据的一致性。
(4)持久性(Durability):
一旦事务提交,则其所做的修改会永久保存到数据库。
此时即使系统崩溃,修改的数据也不会丢失。
4.事务操作
表的引擎类型必须是innodb类型才可以使用事务,这是mysql表的默认引擎。
开启事务:
语法:start transation;或者begin;
开启事务后执行修改命令,变更会维护到本地缓存中,而不维护到物理表中。
提交事务:
语法:commit;
将缓存中的数据变更维护到物理表中。
回滚事务:
语法:rollback;
放弃缓存中变更的数据。
练习:
现在操作在一个事务中1给2转100,同时另一个事务中1给3转100.
数据如下
+----+-----+
| id | num |
+----+-----+
| 1 | 100 |
| 2 | 200 |
| 3 | 0 |
+----+-----+
操作过程如图
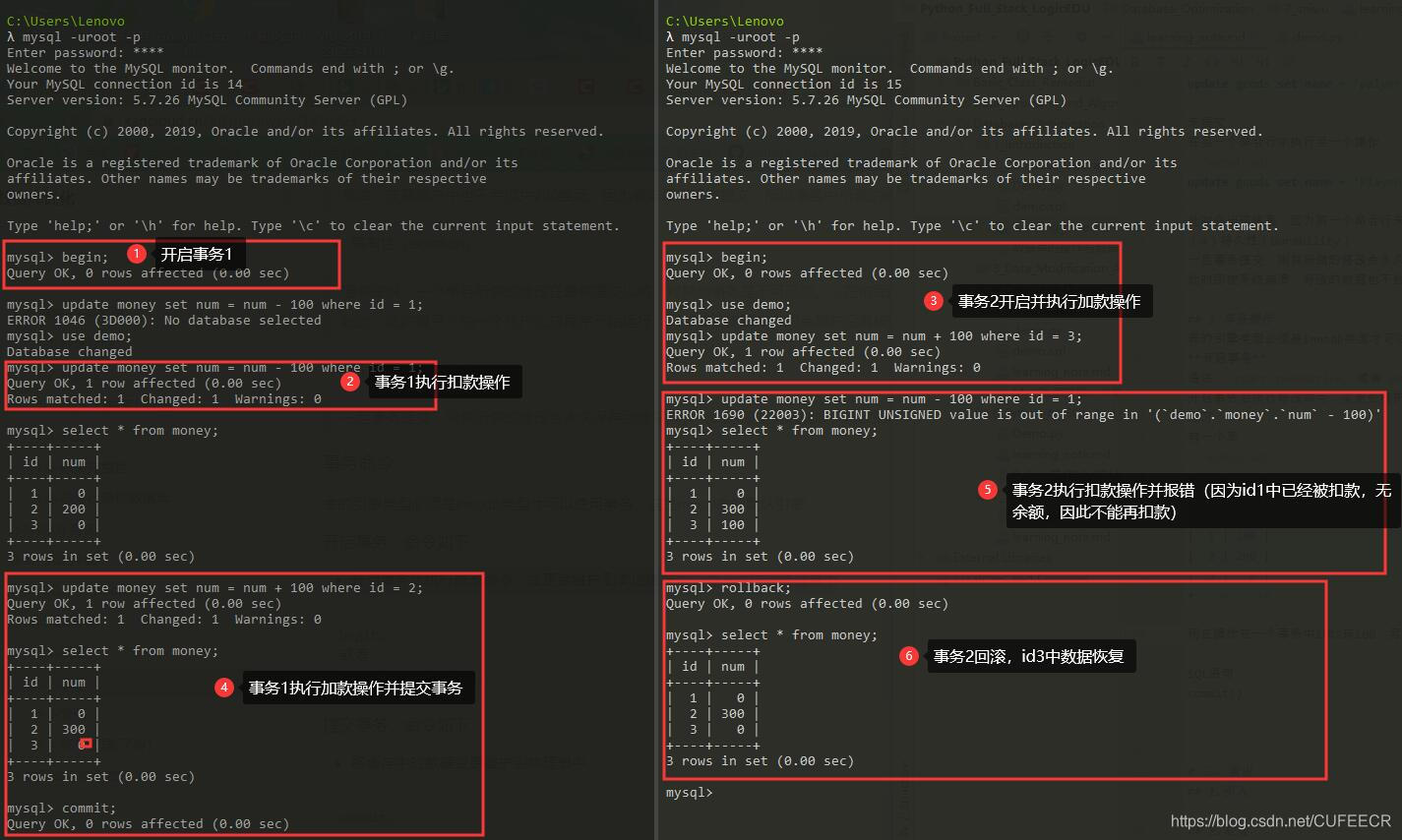
事务1提交后,事务2对id1的更改会报错,因此需要回滚,从而保证了数据的一致性。
修改数据的命令会自动的触发事务,包括insert、update、delete;
如果对数据库的操作涉及多次数据的修改,并且成功一起成功,否则一起会滚到之前的数据,需要在SQL语句中有手动开启事务。
二、索引
1.引入
在图书馆中是如何找到一本书的?
一般的应用系统对比数据库的读写比例在10:1左右(即有10次查询操作时有1次写的操作),而且插入操作和更新操作很少出现性能问题,遇到最多、最容易出问题还是一些复杂的查询操作,所以查询语句的优化显然是重中之重。
当数据库中数据量很大时,查找数据会变得很慢,所以引入索引进行优化。
2.定义
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
通俗地说,数据库索引就像一本书前面的目录,它们包含着对数据表里所有记录的引用指针。
索引的目的:
索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql。
索引原理:
生活中随处可见索引的例子,如词典、火车站的车次表、图书的目录等。它们的原理都是一样的,通过不断的缩小想要获得数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是我们总是通过同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂许多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。
如下图
索引使用的数据结构一般是B树。
索引分为:
- 单值索引:单个字段;
- 复合索引:多个字段;
- 唯一索引:列的值必须唯一,应用于身份证号、电话号等。
3.索引的使用
查看索引:
语法:show index from 表名;
show index from money;
打印
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| money | 0 | PRIMARY | 1 | id | A | 3 | NULL | NULL | | BTREE | | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.01 sec)
主键会自动创建索引;
创建索引:
语法:create index 字段名称 on 表名(字段名称(长度));
create index idx_num on money(num);
再查看索引
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| money | 0 | PRIMARY | 1 | id | A | 3 | NULL | NULL | | BTREE | | |
| money | 1 | idx_num | 1 | num | A | 2 | NULL | NULL | | BTREE | | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
如果指定字段是字符串,需要指定长度,建议长度与定义字段时的长度一致;
字段类型如果不是字符串,可以不填写长度部分。
创建唯一索引:
create unique index idx_num on money(num);
删除索引:
语法:drop index 索引名称 on 表名;
4.索引练习
创建测试表test:
create table test(title varchar(10));
使用python程序向表中加入十万条数据:
from pymysql import *
def main():
conn = connect(
host='127.0.0.1',
port=3306,
db='demo',
user='root',
passwd='root',
charset='utf8')
cur = conn.cursor()
for i in range(100000):
cur.execute('insert into test values("ts-%d")' % i)
conn.commit()
if __name__ == '__main__':
main()
开启运行时间监测:
set profiling=1;
查找第100000条数据:
select * from test where title='ts-99999';
打印
+----------+
| title |
+----------+
| ts-99999 |
+----------+
1 row in set (0.04 sec)
查看执行的时间:
show profiles;
打印
+----------+------------+-------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+-------------------------------------------+
| 1 | 0.03794450 | select * from test where title='ts-99999' |
+----------+------------+-------------------------------------------+
1 row in set, 1 warning (0.00 sec)
为表title_index的title列创建索引:
create index title_index on test(title(10));
再次执行查询语句:
select * from test where title='ts-99999';
打印
+----------+
| title |
+----------+
| ts-99999 |
+----------+
1 row in set (0.00 sec)
再次查看执行的时间:
show profiles;
打印
+----------+------------+---------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------------------+
| 1 | 0.03794450 | select * from test where title='ts-99999' |
| 2 | 0.26895350 | create index title_index on test(title(10)) |
| 3 | 0.00031875 | select * from test where title='ts-99999' |
+----------+------------+---------------------------------------------+
3 rows in set, 1 warning (0.00 sec)
显然,建立了索引后查询速度有了很大提升,即建立索引可以大幅提高查询效率。
适合建立索引的情况:
- 主键自动建立索引;
- 频繁作为查询条件的字段应该建立索引;
- 查询中与其他表关联的字段,外键关系建立索引;
- 在高并发的情况下创建复合索引;
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度 (建立索引的顺序跟排序的顺序保持一致)。
不适合建立索引的情况:
- 频繁更新的字段不适合建立索引;
- where条件里面用不到的字段不创建索引;
- 表记录太少,当表中数据量超过三百万条数据,可以考虑建立索引;
- 数据重复且平均的表字段,比如性别,国籍。
三、账户管理
在生产环境下操作数据库时,绝对不可以使用root账户连接,而是创建特定的账户,授予这个账户特定的操作权限,然后连接进行操作,主要的操作就是数据的crud。
MySQL账户体系:
根据账户所具有的权限的不同,MySQL的账户可以分为以下几种:
- 服务实例级账号:启动了一个mysqld,即为一个数据库实例;如果某用户如root,拥有服务实例级分配的权限,那么该账号就可以删除所有的数据库、连同这些库中的表;
- 数据库级别账号:对特定数据库执行增删改查的所有操作;
- 数据表级别账号:对特定表执行增删改查等所有操作;
- 字段级别的权限:对某些表的特定字段进行操作;
- 存储程序级别的账号:对存储程序进行增删改查的操作。
账户的操作主要包括创建账户、删除账户、修改密码、授权权限等。
授予权限:
需要使用实例级账户登录后操作,以root为例
主要操作包括:
(1)查看所有用户:
所有用户及权限信息存储在mysql数据库的user表中;
查看user表的结构:
use mysql;
desc user;
打印
+------------------------+-----------------------------------+------+-----+-----------------------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------------------+-----------------------------------+------+-----+-----------------------+-------+
| Host | char(60) | NO | PRI | | |
| User | char(32) | NO | PRI | | |
| Select_priv | enum('N','Y') | NO | | N | |
| Insert_priv | enum('N','Y') | NO | | N | |
| Update_priv | enum('N','Y') | NO | | N | |
| Delete_priv | enum('N','Y') | NO | | N | |
| Create_priv | enum('N','Y') | NO | | N | |
| Drop_priv | enum('N','Y') | NO | | N | |
| Reload_priv | enum('N','Y') | NO | | N | |
| Shutdown_priv | enum('N','Y') | NO | | N | |
| Process_priv | enum('N','Y') | NO | | N | |
| File_priv | enum('N','Y') | NO | | N | |
| Grant_priv | enum('N','Y') | NO | | N | |
| References_priv | enum('N','Y') | NO | | N | |
| Index_priv | enum('N','Y') | NO | | N | |
| Alter_priv | enum('N','Y') | NO | | N | |
| Show_db_priv | enum('N','Y') | NO | | N | |
| Super_priv | enum('N','Y') | NO | | N | |
| Create_tmp_table_priv | enum('N','Y') | NO | | N | |
| Lock_tables_priv | enum('N','Y') | NO | | N | |
| Execute_priv | enum('N','Y') | NO | | N | |
| Repl_slave_priv | enum('N','Y') | NO | | N | |
| Repl_client_priv | enum('N','Y') | NO | | N | |
| Create_view_priv | enum('N','Y') | NO | | N | |
| Show_view_priv | enum('N','Y') | NO | | N | |
| Create_routine_priv | enum('N','Y') | NO | | N | |
| Alter_routine_priv | enum('N','Y') | NO | | N | |
| Create_user_priv | enum('N','Y') | NO | | N | |
| Event_priv | enum('N','Y') | NO | | N | |
| Trigger_priv | enum('N','Y') | NO | | N | |
| Create_tablespace_priv | enum('N','Y') | NO | | N | |
| ssl_type | enum('','ANY','X509','SPECIFIED') | NO | | | |
| ssl_cipher | blob | NO | | NULL | |
| x509_issuer | blob | NO | | NULL | |
| x509_subject | blob | NO | | NULL | |
| max_questions | int(11) unsigned | NO | | 0 | |
| max_updates | int(11) unsigned | NO | | 0 | |
| max_connections | int(11) unsigned | NO | | 0 | |
| max_user_connections | int(11) unsigned | NO | | 0 | |
| plugin | char(64) | NO | | mysql_native_password | |
| authentication_string | text | YES | | NULL | |
| password_expired | enum('N','Y') | NO | | N | |
| password_last_changed | timestamp | YES | | NULL | |
| password_lifetime | smallint(5) unsigned | YES | | NULL | |
| account_locked | enum('N','Y') | NO | | N | |
+------------------------+-----------------------------------+------+-----+-----------------------+-------+
45 rows in set (0.00 sec)
主要字段说明:
Host表示允许访问的主机;
User表示用户名;
authentication_string表示密码,为加密后的值。
查看所有用户:
select host,user,authentication_string from user;
+-----------+---------------+-------------------------------------------+
| host | user | authentication_string |
+-----------+---------------+-------------------------------------------+
| localhost | root | *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B |
| localhost | mysql.session | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE |
| localhost | mysql.sys | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE |
| 127.0.0.1 | Tom | *6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9 |
| localhost | Tom2 | *6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9 |
+-----------+---------------+-------------------------------------------+
5 rows in set (0.00 sec)
(2)创建账户、授权
需要使用实例级账户登录后操作,以root为例
常用权限主要包括:create、alter、drop、insert、update、delete、select
如果分配所有权限,可以使用all privileges
语法:
grant 权限列表 on 数据库 to '用户名'@'访问主机' identified by '密码';
grant select on jingdong.* to 'Leo'@'localhost' identified by '123456';
--创建一个Mary的账号,密码为12345678,可以任意电脑进行链接访问, 并且对jd数据库中的所有表拥有所有权限
grant all privileges on jd.* to "Mary"@"%" identified by "12345678"
--刷新权限
flush privileges;
说明:
可以操作数据库的所有表,方式为:jingdong.*;
访问主机通常使用 百分号% 表示此账户可以使用任何ip的主机登录访问此数据库;
访问主机可以设置成 localhost或具体的ip,表示只允许本机或特定主机访问。
查看用户有哪些权限:
show grants for Leo@localhost;
打印
+---------------------------------------------------+
| Grants for Leo@localhost |
+---------------------------------------------------+
| GRANT USAGE ON *.* TO 'Leo'@'localhost' |
| GRANT SELECT ON `jingdong`.* TO 'Leo'@'localhost' |
+---------------------------------------------------+
2 rows in set (0.00 sec)
使用新创建的用户登录:
mysql -uLeo -p
查看数据库:
show databases;
打印
+--------------------+
| Database |
+--------------------+
| information_schema |
| jingdong |
+--------------------+
2 rows in set (0.00 sec)
进行删除操作
use jingdong;
drop table goods;
打印
ERROR 1142 (42000): DROP command denied to user 'Leo'@'localhost' for table 'goods'
报错,命令拒绝,因为只给Leo了查看权限,所以不能进行增加、修改、删除操作。
四、数据库存储引擎简介
1.MySQL体系结构:
- 连接层
- 服务层(核心)
- 存储引擎层
- 文件系统
如图:
服务层:
服务层是MySQL的核心,MySQL的核心服务层都在这一层,查询解析、SQL执行计划分析、SQL执行计划优化、查询缓存、以及跨存储引擎的功能都在这一层实现:存储过程,触发器,视图等。
下图是服务层的内部结构:
存储引擎层:
负责MySQL中数据的存储与提取。
服务器中的查询执行引擎通过API与存储引擎进行通信,通过接口屏蔽了不同存储引擎之间的差异。
MySQL采用插件式的存储引擎。MySQL为我们提供了许多存储引擎,每种存储引擎有不同的特点。我们可以根据不同的业务特点,选择最适合的存储引擎。
如果对于存储引擎的性能不满意,可以通过修改源码来得到自己想要达到的性能。例如阿里巴巴的X-Engine,为了满足企业的需求facebook与google都对InnoDB存储引擎进行了扩充。
2.存储引擎操作
查看存储引擎:
show engines;
打印
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
9 rows in set (0.01 sec)
查看默认的存储引擎:
show variables like '%storage_engines%';
打印
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| disabled_storage_engines | |
+--------------------------+-------+
1 row in set, 1 warning (0.00 sec)

欢迎大家加入群聊【python知识交流分享群】,进行技术交流:https://jq.qq.com/?_wv=1027&k=5m5AduZ

