紧接上一次。
这次是对于spark安装的总结。
首先便是下载spark。

从官网上可以找到用户提供Hadoop环境的安装包,另外值得一提的是用户也可以无需自己安装hadoop而是选择原装包括了hadoop的安装包。

放入虚拟机之后解压缩,修改权限,之后就可以开始配置了。
配置文件需要配置slaves(用于分布式配置,我只填入master的地址,所以也是伪分布吧)和spark-env.sh
slaves文件设置Worker节点而spark-env.sh需要填入的内容为:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath) export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop # hadoop配置目录 export SPARK_MASTER_IP=192.168.1.100 # 根据自己主机地址修改


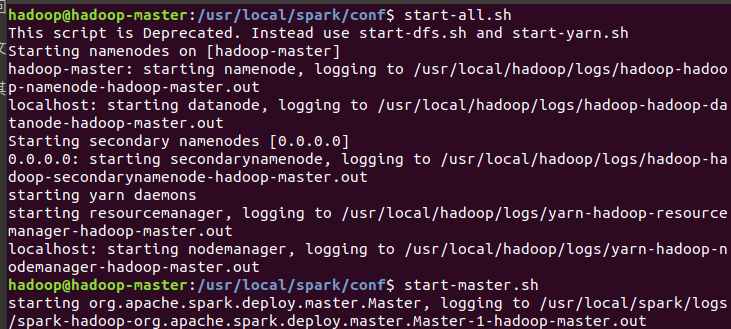
完成后启动hadoop和spark即可。
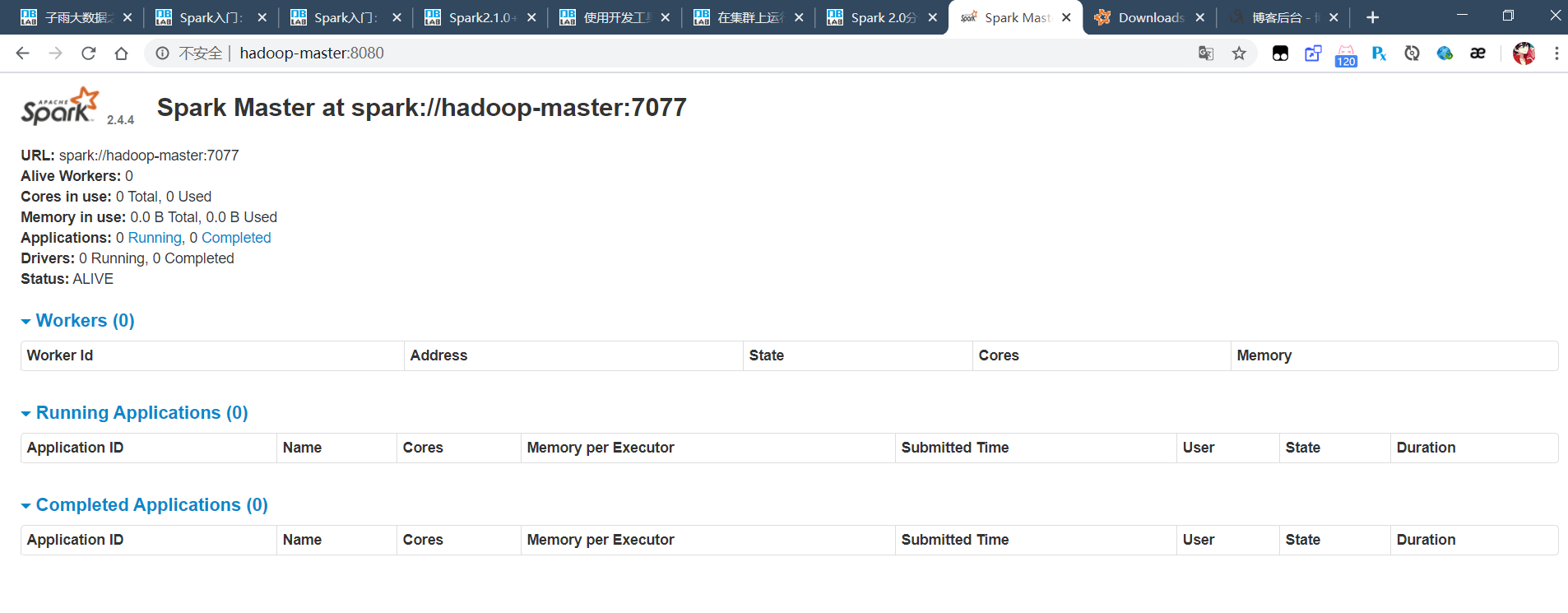
之后可以在虚拟机外部访问。