需要又快又好地网络?
AutoML地NAS似乎是一个非常好的方法,前段时间看了一点点,了解了一下,没有深究
最近急需得到又快又好地网络,木子王粟推荐了 EfficientNet
要看的东西比较多,这里主要介绍mobilenets和shufflenet吧
会另开两篇讲看到的知识蒸馏和NAS相关
MobileNets
MobileNetv1
MobileNetv2
MobileNetv3
文章再三提到 MobileNet
看到这个博客 和这个博客 讲的蛮清晰的
- 可分离卷积(depthwise separable convlution)
- 倒残差模块(Inverted Residuals)
- 线性瓶颈(Linear Bottleneck)
- h-wish激活函数
- SE模块
- 初始5x5卷积,最后提前池化
Mobilenetv1
groups convolution
群组卷积
CLASStorch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')

也就是将输入的fetures分为群组,然后分别对每个群组卷积然后连接(cat)到一起,in_channels和out_channels必须同时被groups整除
e.g.输入ci=32, 输出co=32,g=2
那么将输入分为2组,ci1=ci2=ci/g=16, 每组需要的卷积个数为ck1=ck2=co/g=16
ck1ci1=co1=16, ck2ci2=co2=16, concate则最后的输出即为co=32
但是,g=1时计算量为-输入特征层(32)*卷积核的个数(32),这么多个参数
而g=2时,计算量为-输入特征层(16)*卷积个数(16)*组数(2)
- 当
in_channel=groups,卷积就变成了所谓的depthwise convolution
此时的计算量为1* 1 *32,如果输入输出的feature一样的话
depthwise separable convolutions
深度可分离卷积
factorized convolutions which factorize a standard convolution into a depthwise convolution and a 1x1 convolution called a pointwise convolution
所谓深度可分离卷积就是一种因式分解卷积的形式,将标准卷积分解为depthwise convolution和pointwise convolution
- 实现过程和参数量
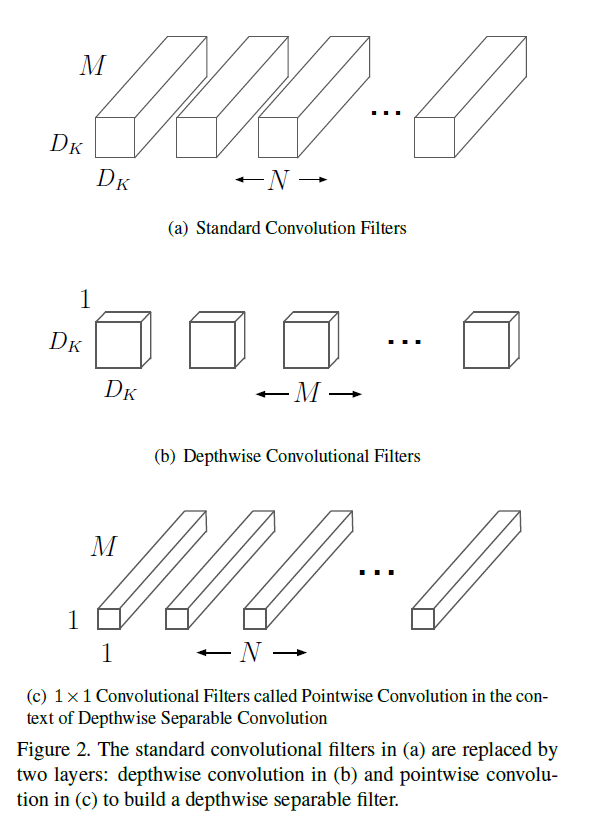
论文里面的图,大概就是说N个MDkDk的卷积可以分解为b)M个1 * Dk * Dk的卷积和c)N个M * 1 * 1的卷积两步卷积
这样,参数量就变为原来的好多分之一

- BN和激活函数

Inception models
具体得查看文献
- 使用
1x1卷积
This can be implemented with highly optimized general matrix multiply (GEMM) functions. Often convolutions are implemented by a GEMM but require an initial reordering in memory called im2col in order to map it to a GEMM.
实现时,1x1的卷积计算时有优化,可以节省计算时间
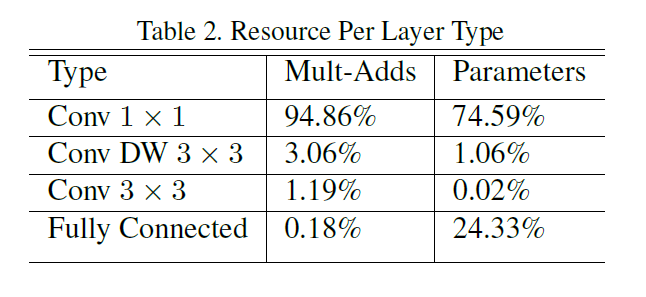
- 网络结构
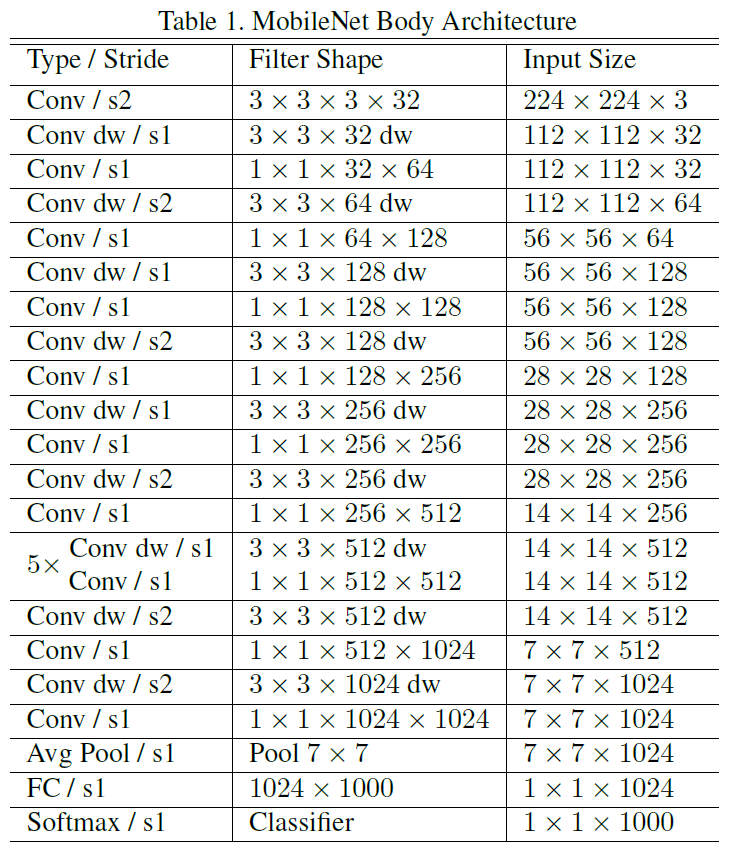
以上通过depthwise separable convolutions实现了在损失一点精度的同时大大减少了计算量,那么问题来了
Although the base MobileNet architecture is already small and low latency, many times a specific use case or application may require the model to be smaller and faster.
扫描二维码关注公众号,回复: 8702432 查看本文章
我们还想要smaller and faster怎么办?文章提出了一种思想,如下
global hyperparameters trade off latency and accuracy
improve accuracy are not necessarily making networks more efficient with respect to size and speed
这个latency指的是?
- FLOPs(具体计算?)== Mult-Adds
s应该小写,指的是计算量,指的是网络所有操作进行加法和乘法的操作数,但是实际上并不能代表实际操作的运算速度,即使是单独测试每种操作在实际硬件上的耗时也会有偏差,因为不同操作之间的组合也会有耗时 - 硬件实现耗时
- 超参
width multiplier and resolution multiplier
宽度倍率,即feature的通道数;分辨率倍率,指的是输入图像的分辨率
Many different approaches can be generally categorized into either compressing pretrained networks or
training small networks directly. This paper proposes a class of network architectures that allows a model developer to specifically choose a small network thatmatches the resource restrictions (latency, size) for their application
提供了一类网络可以根据你的应用匹配你的资源限制,例如延时和大小,很吸引人的点
他是怎样实现的呢?
也就是在baseline的基础上,width multiplier

这不是我们想到的基本思想。。。。
resolution multiplier

无力吐槽,但是正是由于他们对这个问题有这样一个思考,才有他能想到efficientNet的grid search方法寻找最优dwr的scale, 任何一个简单的思考都是有价值的
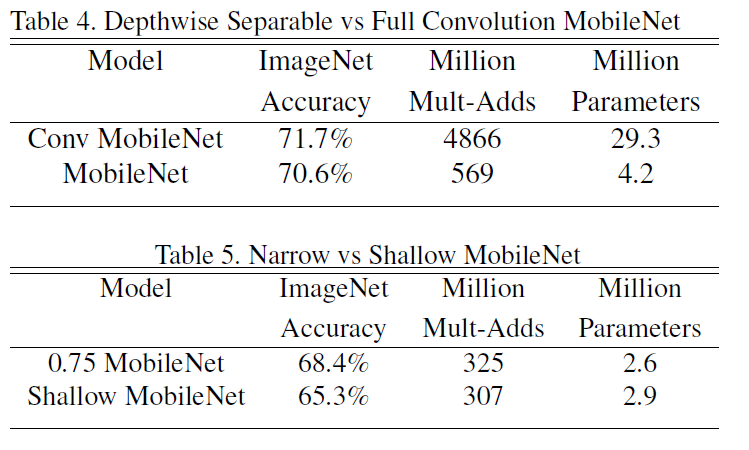
下面一个实验蛮有意思的:Narrow vs Shallow
- mobileNetv1总结
- 使用
depthwise separable convolutions其中的1x1的卷积减少了计算量,以及这样一个dw操作中BN和ReLu等操作的使用 - 对网络的宽度(w),深度(d)和分辨率®有了一点思考,后面的实验说明同样的计算量,可能宽度要优先于深度,存疑
mobileNetv2
文章名字就叫MobileNetV2: Inverted Residuals and Linear Bottlenecks
那么重点肯定就是Inverted Residuals 和 Linear Bottlenecks
反残差和线性瓶颈,不知所云啊,看文章
Our main contribution is a novel layer module: the inverted residual with linear bottleneck
- depthwise separable convolutions
首先v2沿用了这种好用的结构
- inverted residuals
借鉴了ResNet结构,提出反残差结构
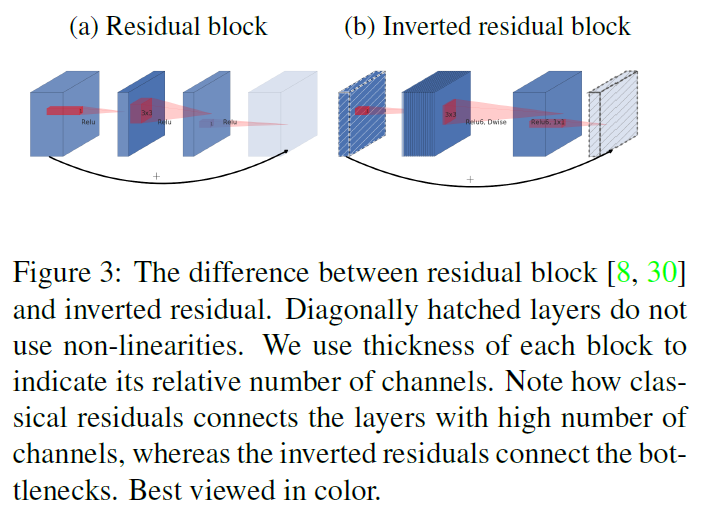
- 和resnet一样使用shortcuts的连接
- 但是在前后1x1卷积的时候扩充了卷积通道,故称之为inverted residual
Linear Bottlenecks
考虑ReLu激活函数在低维空间会导致信息大量缺失,所以最后一层改为线性激活函数
证明?
看原文3.2 Linear Bottlenecks
他认为所谓的manifold of interest,可以embedded到一个低维的子空间
我们可以通过width multiplier降低这个维度空间
然而,当我们的神经网络拥有非线性操作后
他做了一个实验

以上实验用一个随机变换T将输入,就是那个圈圈,变换成高维,再通过ReLu激活,然后再通过T‘变回原来维度,他证明维度越高这种信息的丢失就越少
神经网络最开始发明ReLu的时候就告诉大家,这个激活函数能够更加突出被激活的神经元,文章都说他更有效了,现在又说他对信息的丢失太严重了,ReLu太难了,当然这个实验并不是要说明这点,ReLu必然会导致信息的稀疏,但他的初衷是去除冗余,但是在这里是为了说明,低维时每一维都具有有效的信息,但是ReLu可能会将他们丢弃了
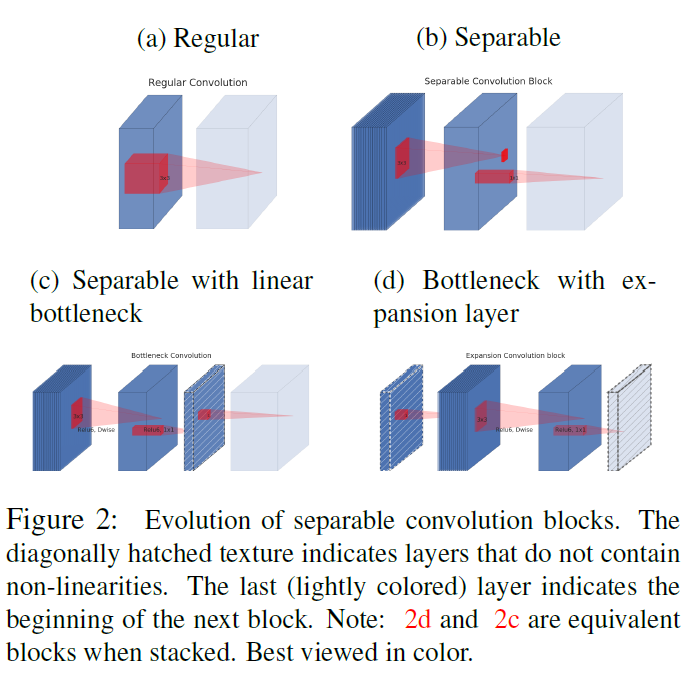
这里首先将1x1卷积后的激活函数变为线性激活,就是没有激活函数
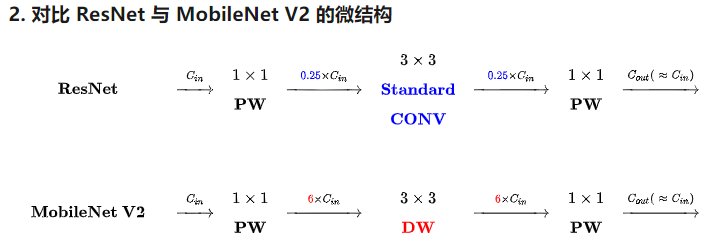
借知乎别人的图说明以上两点

好像文章结构就到这里了
直观看v2的参数比v1不是应该多好多?多了1x1卷积,后面的conv卷积通道还多了好几倍。。。。,还有shortcuts呢?
看看后面怎么圆。。。。
nature of our networks allows us to utilize much smaller input and output dimensions
expansion rate
也就是上面的t,文章为什么使用了常数?
In our experiments we find that expansion rates between 5 and 10 result in nearly identical performance curves, with smaller networks being better off with slightly smaller expansion rates and larger networks having slightly better performance with larger expansion rates.
因为实验证明过大带来的性能影响微乎其微
width multiplier
width multipliers of 0:35 to 1:4
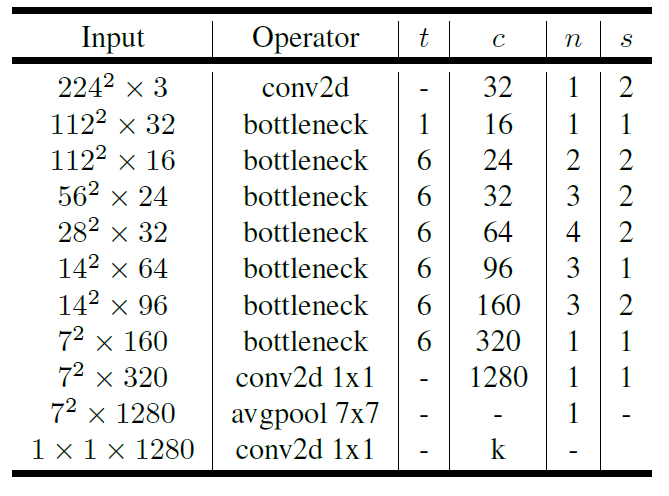
- 文章各网络结构
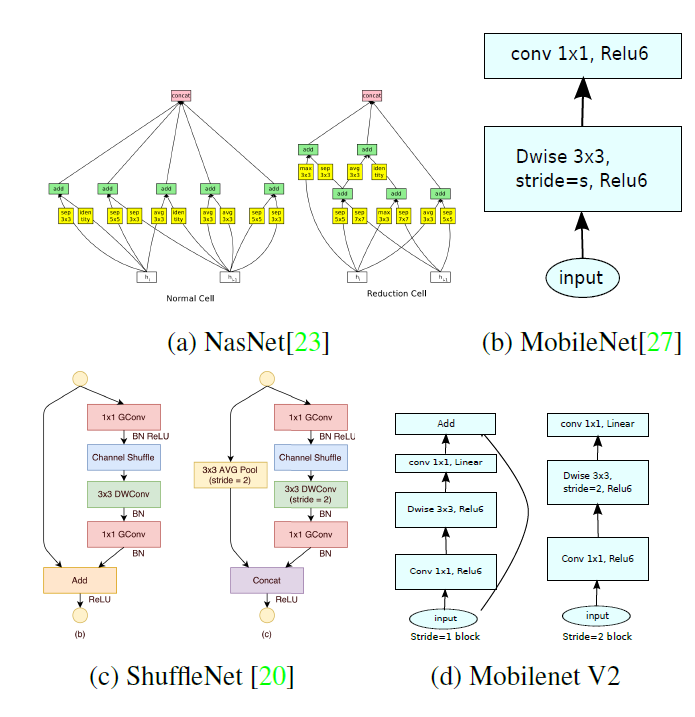
文章MobileNetv1,v2都看过了,shuffleNet待看,NasNet再说吧
最后好像还有证明,有机会再看一遍
