单机存在的的问题
在一台机器上部署单个Redis节点,存在哪些问题?
- 机器故障,数据丢失。
- 容量瓶颈,单台机器内存有限。
- 性能瓶颈
- 无法高可用
针对单机存在的问题,Redis也提供了多种集群方案:
- 主从复制
- 哨兵模式
- 集群
该篇博客主要针对“主从复制”做一下简单记录。
主从复制
将节点的角色分为Master和Slave,主机和从机。
Master主要负责数据的写入,并且同步数据到Slave。
Slave负责做数据的持久化备份,并且负责客户端对数据的读取。
主从复制可以做到:
- 读写分离
- 容灾备份
环境搭建
主机8001
主机关闭AOF,尽量少的触发RDB持久化,提升性能,持久化任务交给从机去做。
# 任意IP可访问
bind 0.0.0.0
# 端口
port 8001
# 守护进程运行
daemonize yes
# 单机器运行多个Redis服务必须指定不同pidfile
pidfile /var/run/redis_8001.pid
# 日志文件,端口号区分
logfile "8001.log"
# rdb文件
dbfilename dump8001.rdb
# 基础目录
dir /app/redis/8001/
# 访问密码设置
requirepass 123
从机 8002
单机启动三个Redis服务来模拟集群,实际需要三台物理机器,IP端口配置好即可。
# 任意IP可访问
bind 0.0.0.0
# 端口
port 8002
# 守护进程运行
daemonize yes
# 单机器运行多个Redis服务必须指定不同pidfile
pidfile /var/run/redis_8002.pid
# 日志文件,端口号区分
logfile "8002.log"
# rdb文件
dbfilename dump8002.rdb
# 基础目录
dir /app/redis/8002/
# 启用AOF持久化
appendonly yes
# 主机IP、端口
replicaof 127.0.0.1 8001
# 主机访问密码
masterauth 123
从机8003
和从机8002配置一致,端口号区分。
启动三个Redis服务,加载8001~8003不同的配置文件,查看进程看服务是否均启动成功。

服务正常启动则表示集群搭建成功,接下来开始测试。

主从复制测试
1、分别连接不同的服务
redis-cli -p 8001 auth 123 //主机访问需要密码
redis-cli -p 8002
redis-cli -p 8003
2、查看各节点的Replication信息。
主机8001
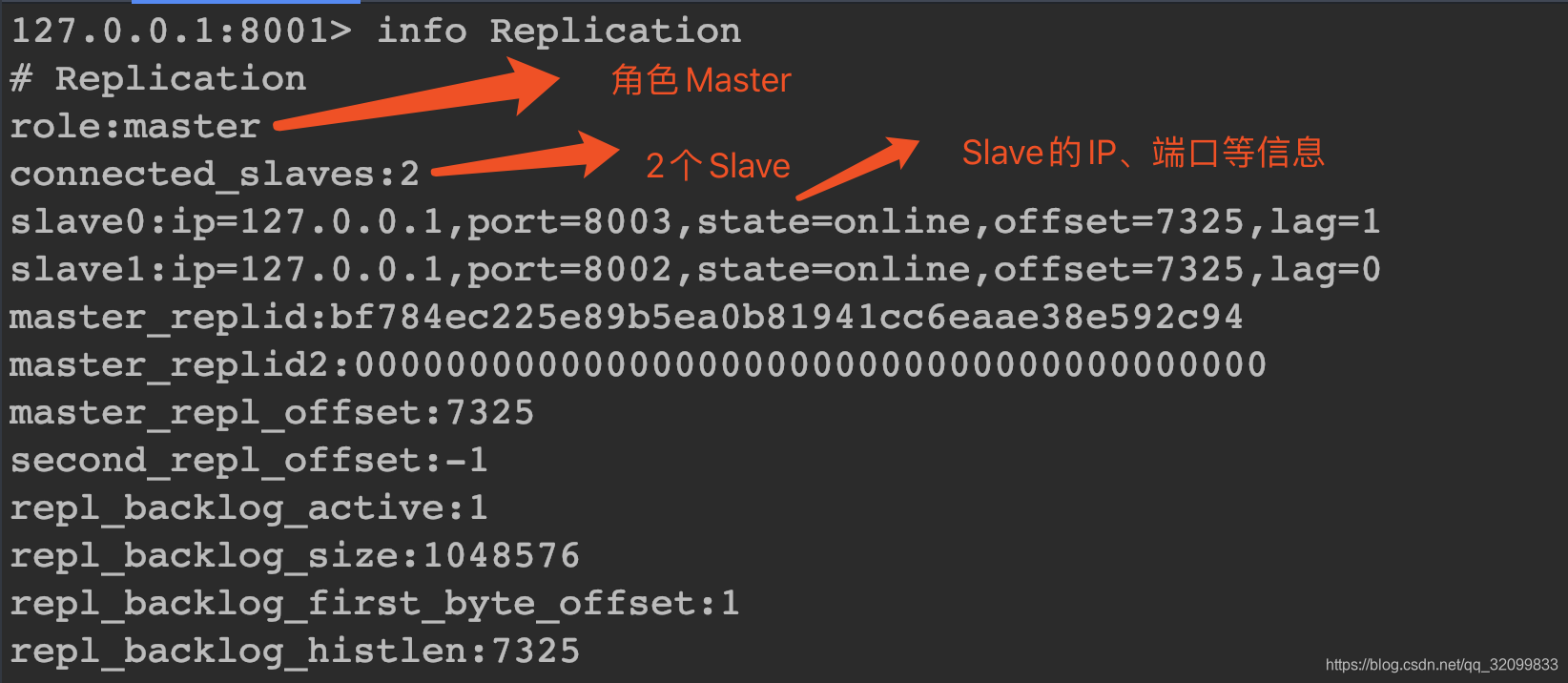
从机8002
8003类似,不展示。
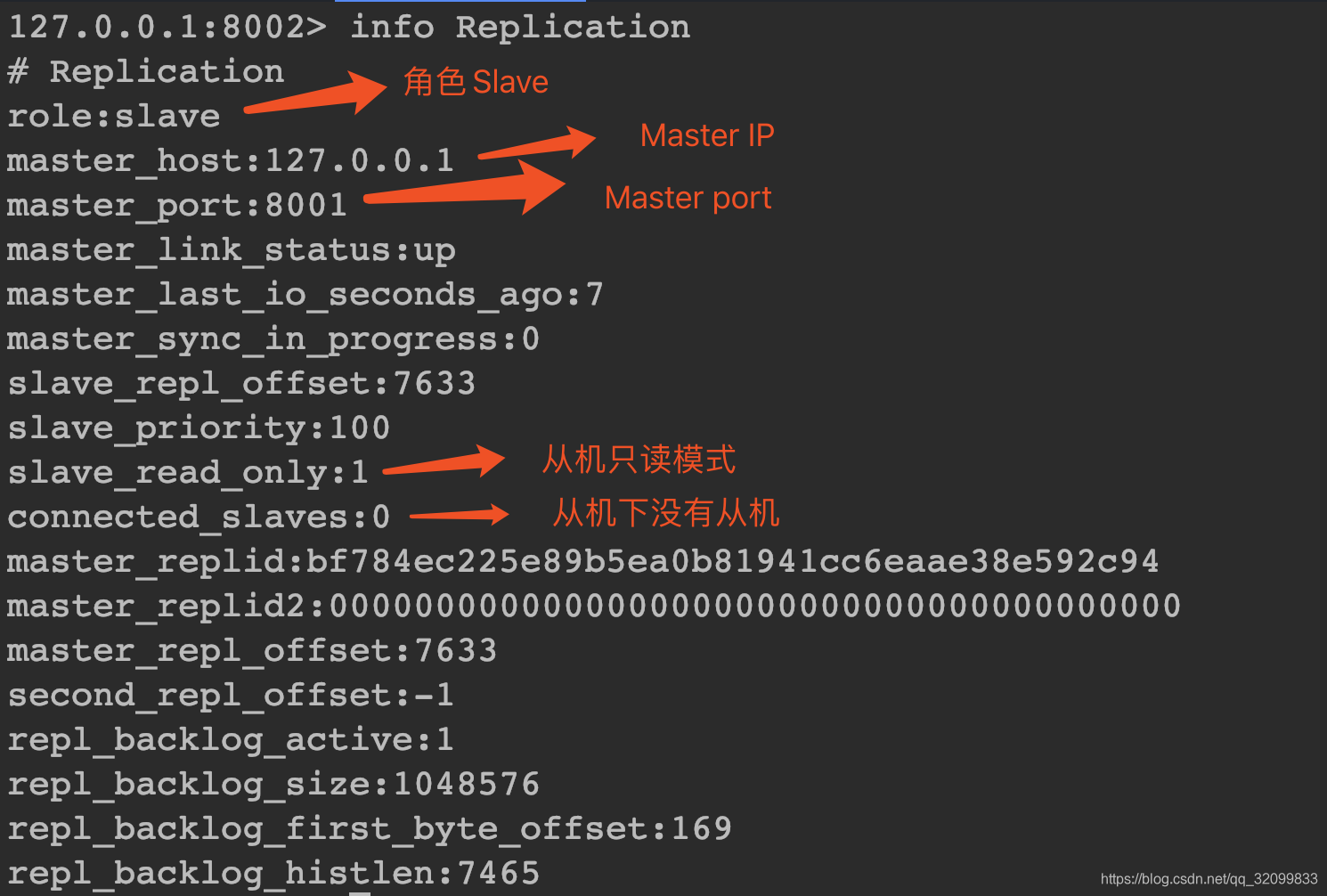
Master、Slave信息没有问题,写点数据测试一下。
3、往Master中写入数据,Slave读取数据,正常。
127.0.0.1:8001> set name hello
OK
127.0.0.1:8002> get name
"hello"
127.0.0.1:8003> get name
"hello"
4、Slave尝试写入数据,异常。
127.0.0.1:8002> set name world
(error) READONLY You can't write against a read only replica.
不能对只读副本进行写操作。
忘了从什么版本开始,Redis默认Slave为只读,不能写入数据,如果需要对Slave进行写操作,可以修改配置文件:
slave-read-only no
但是强烈建议不要这么做,因为主从复制数据流是单向的,从机写入的数据并不会同步到其他从机和主机,会出现数据不一致的问题。
复制过程
Redis主从复制分为两种:全量复制、增量复制。
全量复制
全量复制一般发生在Slave初始化阶段,Slave节点数据为空,为了和Master数据同步,Slave需要将Master上的所有数据都复制一份,大致步骤如下:
- Slave连接Master,发送SYNC命令,进行数据数据同步。
- Master接收到SYNC命名后,执行BGSAVE命令异步生成RDB文件并使用缓冲区记录此后执行的所有写命令。
- 异步执行BGSAVE的期间,Master将自身的runId标识和offset偏移量发送给Slave保存。
- Master执行完BGSAVE后,向Slave发送快照文件,并在发送期间继续记录被执行的写命令。
- Slave收到快照文件后丢弃所有旧数据,载入收到的快照。
- Master快照发送完毕后开始向Slave发送缓冲区中的写命令。
- Slave完成对快照的载入,开始接收命令请求,并执行来自Master缓冲区的写命令,后面就是增量复制了。
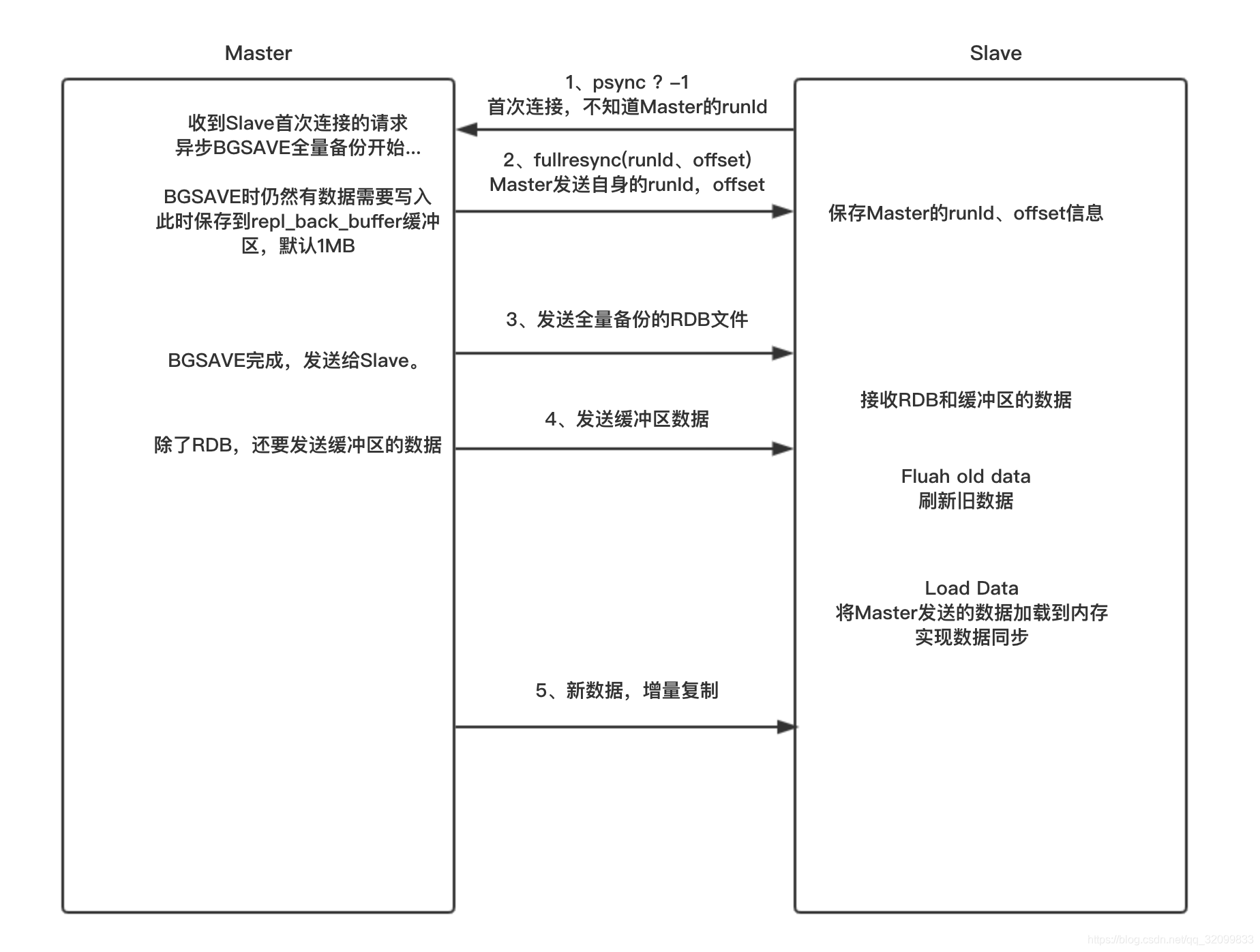
增量复制
Master每执行一次写操作,就将命令发送一份给所有Slave,Slave将增量数据写入,完成和Master的增量同步。
有盘复制和无盘复制
Master将数据保存到RDB文件中,然后发送给Slave,如果Master磁盘空间有限,可以采用无盘复制。
无盘复制将由Master开启一个Socket直接将RDB发送给Slave,无盘复制要求网络状况非常好。
runId和Offset
runId是由Redis生成的节点唯一标识,Offset是偏移量。
可以通过info server和info replication查看:
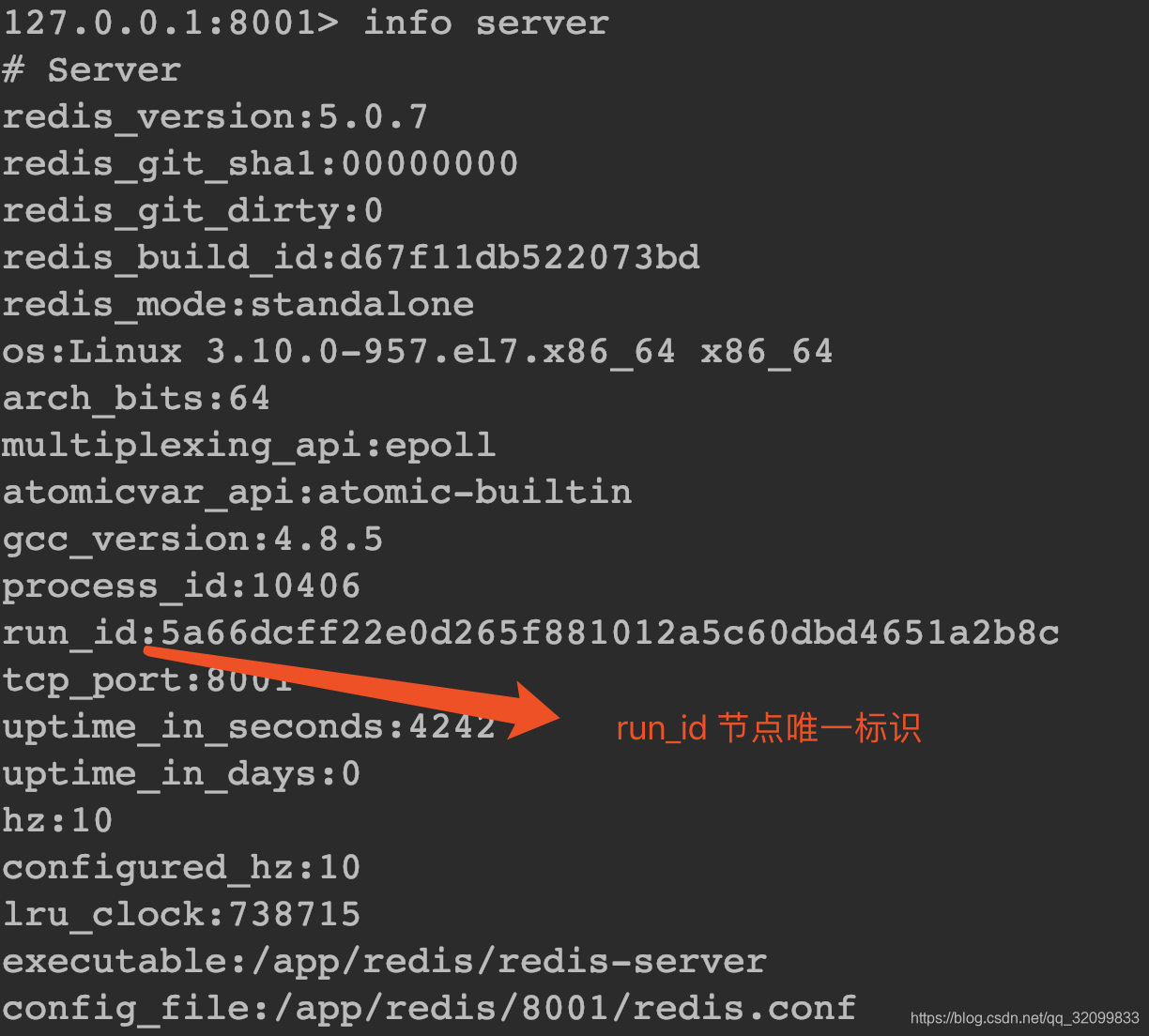
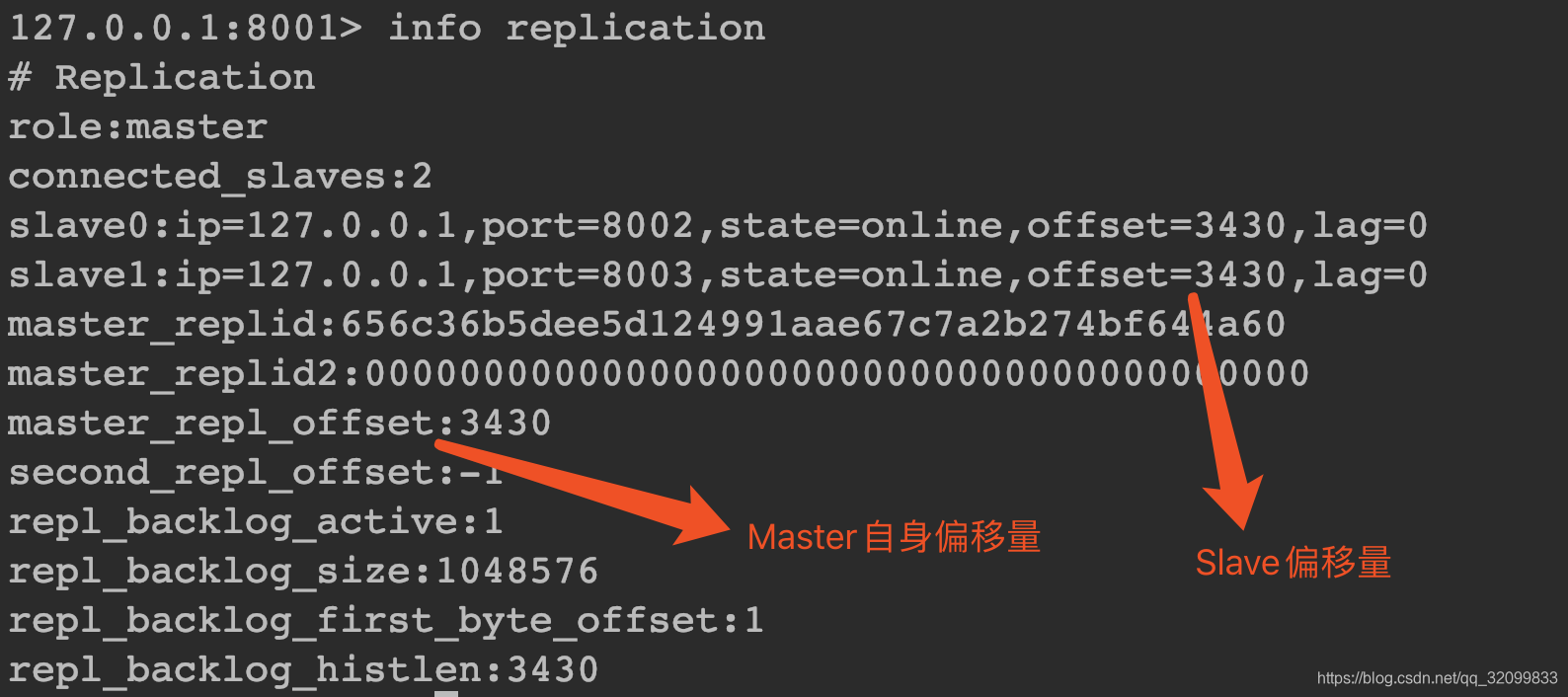
Offset的作用:
Master与Slave主从复制期间,总有意外情况发生,比如网络问题导致Slave掉线,掉线的这一段时间Slave就丢失了数据,需要和Master重新同步,但是如果每次同步都全量复制,Master压力就太大了,为了减少同步开销,Master通过Slave的Offset偏移量来判断是否需要进行全量复制。
Master在做主从复制的期间,会将数据写入一份到缓冲区repl_back_buffer,该缓冲区默认配置为1MB大小,可以把它看做是一个队列,达到1MB最先写入的数据会被丢弃。
如果Slave的Offset通过计算,确定丢失的数据在1MB缓冲区大小内,那么Master只需要将缓冲区的数据发送给Slave,做一个增量复制即可,如果Offset计算丢失的数据大于1MB的缓冲区,就意味着需要进行全量复制。
说白了,Offset的作用就是为了Master判断是否要为Slave做全量复制用的。
主从复制要点
- Redis采用异步复制,不会阻塞服务,Master发送数据给Slave时,仍然可以应答写操作。
- Slave在接收Master数据时,仍然可以用旧数据应答读操作。
- 为了提升Master的写性能,一般会关闭Master的持久化功能,可能导致Master重启后数据是空的,这时进行主从复制可能会导致Slave数据清空。
特点
- 一个Master可以有多个Slave
- 一个Slave只能有一个Master
- 数据流式单向的,Master >> Slave
- 数据读写分离、从机容灾备份
缺点
- Master只能有一台,写性能存在瓶颈。
- Master宕机后无法写入数据。
- Master与Slave之间同步存在延迟,业务繁忙、Slave节点过多问题更严重。
- 数据拷贝多份,无法做分布式存储。
