我又来了,第二篇博客fighting,接着第一篇,这里讨论一下C/C++中float & double类型数据在内存中的存储方式,还是那句话如果有侵权,请联系删除,如果有错误,也欢迎大家指正,谢谢
IEEE规定
IEEE规定float & double类型的数据用三元组{S, E, M}表示,"S"用0和1分别表示正数和负数,尾数"M"用原码表示,阶码"E"用移码表示,还规定尾数域的最高有效位总是1,并且最高位不予存储(都是1也就不用浪费存储空间了)
float类型
单精度浮点数float(32bit)表示为:
SEEE EEEE EMMM MMMM MMMM MMMM MMMM MMMM
- 符号位(S)1 bit;
- 阶码(E)8 bit,阶码的偏移量为127(7FH);
- 尾数(M)23 bit,用小数表示,小数点放在尾数域的最前面.
所以 32bit 的单精度浮点数可表示为:
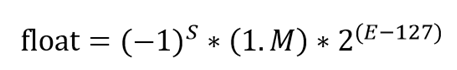
double类型
双精度浮点数double(64bit)表示为:
SEEE EEEE EEEE MMMM MMMM MMMM MMMM MMMM MMMM MMMM MMMM MMMM MMMM MMMM MMMM MMMM
- 符号位(S)1 bit;
- 阶码(E)11 bit,阶码的偏移量为1023(3FFH);
- 尾数(M)52 bit,用小数表示,小数点放在尾数域的最前面.
所以 64bit 的双精度浮点数可表示为:
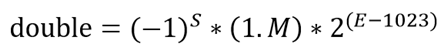
注意
- 当一个浮点数的尾数为0,不论其阶码为何值,或者当阶码的值遇到比他能表示的最小值还小时,不管其尾数为何值,计算机都把该浮点数看成零值,称为机器零;
- 当阶码E为全0且尾数M也为全0时,表示的真值为零,结合符号位S为0或1,有正零和负零之分;
- 当阶码E为全1且尾数M也为全0时,表示的真值为无穷大,结合符号位S为0或1,有正无穷和负无穷之分,故在32 bit浮点数表示中,要去除E用全0和全1(255)表示零和无穷大的特殊情况,因此,阶码E的取值范围变为1—254,指数的偏移量不选128(1000 0000B),而选127(0111 1111B),对于32 bit表示的浮点数,真正的指数值e为-126到+127,因此32 bit浮点数的范围为2的-126次方—2的127次方约等于10的-38次方—10的38次方,64 bit浮点数double与32 bit浮点数float推导方法相似
