目录
Hlog WALs和oldWALs
这里先介绍一下Hlog失效和Hlog删除的规则
HLog失效:写入数据一旦从MemStore中刷新到磁盘,HLog(默认存储目录在/hbase/WALs下)就会自动把数据移动到 /hbase/oldWALs 目录下,此时并不会删除
Hlog删除:Master启动时会启动一个线程,定期去检查oldWALs目录下的可删除文件进行删除,定期检查时间为 hbase.master.cleaner.interval ,默认是1分钟 ,删除条件有两个:
1.Hlog文件在参与主从复制,否的话删除,是的话不删除
2.Hlog文件是否在目录中存在 hbase.master.logcleaner.ttl 时间,如果是则删除
整体流程
pos 格式流程图下载地址:
链接:https://pan.baidu.com/s/1szhpVn7RyegE0yqQedACIA
提取码:ig9x
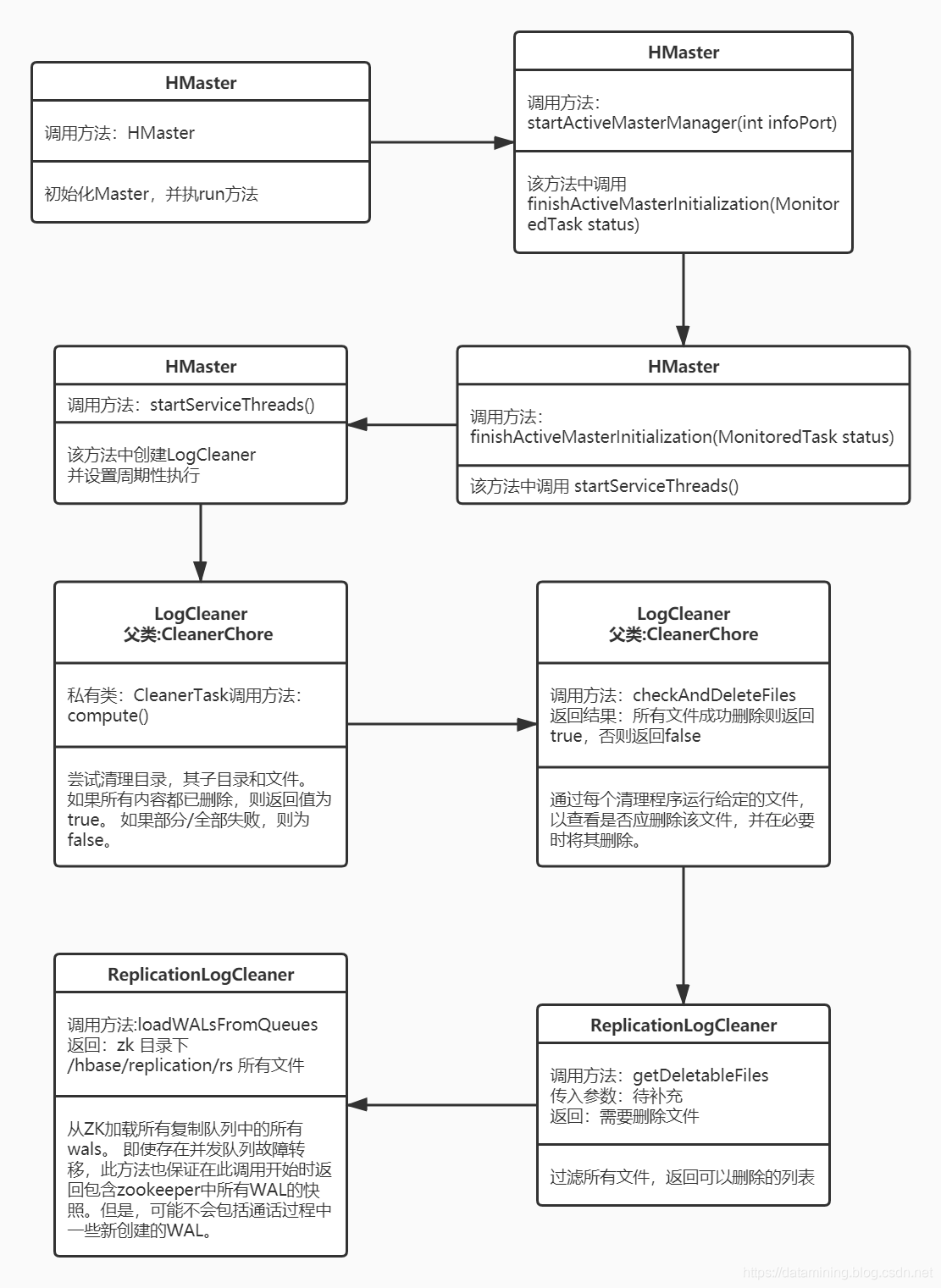
这里只介绍与wal相关的流程,一下介绍的代码都在上图中标记类名,方法名,以及说明,可以直接从源码中查看
HMaster 初始化
HMaster启动初始化 ,HMaster构造方法调用 startActiveMasterManager 方法
startActiveMasterManager 方法 调用 finishActiveMasterInitialization(status); 方法
在 finishActiveMasterInitialization 方法中会启动所有服务线程,代码段如下
// start up all service threads.
status.setStatus("Initializing master service threads");
startServiceThreads();startServiceThreads 方法代码如下,
/*
* Start up all services. If any of these threads gets an unhandled exception
* then they just die with a logged message. This should be fine because
* in general, we do not expect the master to get such unhandled exceptions
* as OOMEs; it should be lightly loaded. See what HRegionServer does if
* need to install an unexpected exception handler.
*/
private void startServiceThreads() throws IOException{
// Start the executor service pools
this.service.startExecutorService(ExecutorType.MASTER_OPEN_REGION,
conf.getInt("hbase.master.executor.openregion.threads", 5));
this.service.startExecutorService(ExecutorType.MASTER_CLOSE_REGION,
conf.getInt("hbase.master.executor.closeregion.threads", 5));
this.service.startExecutorService(ExecutorType.MASTER_SERVER_OPERATIONS,
conf.getInt("hbase.master.executor.serverops.threads", 5));
this.service.startExecutorService(ExecutorType.MASTER_META_SERVER_OPERATIONS,
conf.getInt("hbase.master.executor.serverops.threads", 5));
this.service.startExecutorService(ExecutorType.M_LOG_REPLAY_OPS,
conf.getInt("hbase.master.executor.logreplayops.threads", 10));
// We depend on there being only one instance of this executor running
// at a time. To do concurrency, would need fencing of enable/disable of
// tables.
// Any time changing this maxThreads to > 1, pls see the comment at
// AccessController#postCreateTableHandler
this.service.startExecutorService(ExecutorType.MASTER_TABLE_OPERATIONS, 1);
startProcedureExecutor();
// Initial cleaner chore
CleanerChore.initChorePool(conf);
// Start log cleaner thread
//获取定时日志清理时间,从系统配置获取,默认为10分钟
int cleanerInterval = conf.getInt("hbase.master.cleaner.interval", 60 * 1000);
this.logCleaner =
new LogCleaner(cleanerInterval,
this, conf, getMasterFileSystem().getOldLogDir().getFileSystem(conf),
getMasterFileSystem().getOldLogDir());
//将任务加入定时执行,时间间隔为 cleanerInterval ,该值在LogCleaner中已经设置为定时执行间隔
getChoreService().scheduleChore(logCleaner);
//start the hfile archive cleaner thread
Path archiveDir = HFileArchiveUtil.getArchivePath(conf);
Map<String, Object> params = new HashMap<String, Object>();
params.put(MASTER, this);
this.hfileCleaner = new HFileCleaner(cleanerInterval, this, conf, getMasterFileSystem()
.getFileSystem(), archiveDir, params);
getChoreService().scheduleChore(hfileCleaner);
serviceStarted = true;
if (LOG.isTraceEnabled()) {
LOG.trace("Started service threads");
}
if (!conf.getBoolean(HConstants.ZOOKEEPER_USEMULTI, true)) {
try {
replicationZKLockCleanerChore = new ReplicationZKLockCleanerChore(this, this,
cleanerInterval, this.getZooKeeper(), this.conf);
getChoreService().scheduleChore(replicationZKLockCleanerChore);
} catch (Exception e) {
LOG.error("start replicationZKLockCleanerChore failed", e);
}
}
try {
replicationZKNodeCleanerChore = new ReplicationZKNodeCleanerChore(this, cleanerInterval,
new ReplicationZKNodeCleaner(this.conf, this.getZooKeeper(), this));
getChoreService().scheduleChore(replicationZKNodeCleanerChore);
} catch (Exception e) {
LOG.error("start replicationZKNodeCleanerChore failed", e);
}
}定时执行
其中这段代码是对我们HLog进行处理,并加入调度定时执行
// Initial cleaner chore
CleanerChore.initChorePool(conf);
// Start log cleaner thread
//获取定时日志清理时间,从系统配置获取,默认为10分钟
int cleanerInterval = conf.getInt("hbase.master.cleaner.interval", 60 * 1000);
this.logCleaner =
new LogCleaner(cleanerInterval,
this, conf, getMasterFileSystem().getOldLogDir().getFileSystem(conf),
getMasterFileSystem().getOldLogDir());
//将任务加入定时执行,时间间隔为 cleanerInterval ,该值在LogCleaner中已经设置为定时执行间隔
getChoreService().scheduleChore(logCleaner);加入调度后会周期性执行 LogCleaner.chore() 方法(在父类CleanerChore中)
@Override
protected void chore() {
if (getEnabled()) {
try {
POOL.latchCountUp();
if (runCleaner()) {
if (LOG.isTraceEnabled()) {
LOG.trace("Cleaned all WALs under " + oldFileDir);
}
} else {
if (LOG.isTraceEnabled()) {
LOG.trace("WALs outstanding under " + oldFileDir);
}
}
} finally {
POOL.latchCountDown();
}
// After each cleaner chore, checks if received reconfigure notification while cleaning.
// First in cleaner turns off notification, to avoid another cleaner updating pool again.
if (POOL.reconfigNotification.compareAndSet(true, false)) {
// This cleaner is waiting for other cleaners finishing their jobs.
// To avoid missing next chore, only wait 0.8 * period, then shutdown.
POOL.updatePool((long) (0.8 * getTimeUnit().toMillis(getPeriod())));
}
} else {
LOG.trace("Cleaner chore disabled! Not cleaning.");
}
}上面代码中的runCleaner()方法就是将我们CleanerTask加入任务队列中
public Boolean runCleaner() {
CleanerTask task = new CleanerTask(this.oldFileDir, true);
POOL.submit(task);
return task.join();
}LogCleaner 日志清理类
LogCleaner类是清理日志数据,LogCleaner 父类 CleanerChore 类中的 私有类CleanerTask(该类继承RecursiveTask类,不做过多介绍,想了解的可以百度 ForkJoinTask ), 的 compute()方法是定时清理的关键,这里获取了所有oldWALs目录下的文件,并进行选择性删除
@Override
protected Boolean compute() {
LOG.trace("Cleaning under " + dir);
List<FileStatus> subDirs;
List<FileStatus> tmpFiles;
final List<FileStatus> files;
try {
// if dir doesn't exist, we'll get null back for both of these
// which will fall through to succeeding.
subDirs = FSUtils.listStatusWithStatusFilter(fs, dir, new FileStatusFilter() {
@Override
public boolean accept(FileStatus f) {
return f.isDirectory();
}
});
if (subDirs == null) {
subDirs = Collections.emptyList();
}
//获取oldWALs目录下文件
tmpFiles = FSUtils.listStatusWithStatusFilter(fs, dir, new FileStatusFilter() {
@Override
public boolean accept(FileStatus f) {
return f.isFile();
}
});
files = tmpFiles == null ? Collections.<FileStatus>emptyList() : tmpFiles;
} catch (IOException ioe) {
LOG.warn("failed to get FileStatus for contents of '" + dir + "'", ioe);
return false;
}
boolean allFilesDeleted = true;
if (!files.isEmpty()) {
allFilesDeleted = deleteAction(new Action<Boolean>() {
@Override
public Boolean act() throws IOException {
//files 是oldWALs目录下所有文件
return checkAndDeleteFiles(files);
}
}, "files");
}
boolean allSubdirsDeleted = true;
if (!subDirs.isEmpty()) {
final List<CleanerTask> tasks = Lists.newArrayListWithCapacity(subDirs.size());
for (FileStatus subdir : subDirs) {
CleanerTask task = new CleanerTask(subdir, false);
tasks.add(task);
//任务
task.fork();
}
allSubdirsDeleted = deleteAction(new Action<Boolean>() {
@Override
public Boolean act() throws IOException {
return getCleanResult(tasks);
}
}, "subdirs");
}
boolean result = allFilesDeleted && allSubdirsDeleted;
// if and only if files and subdirs under current dir are deleted successfully, and
// it is not the root dir, then task will try to delete it.
if (result && !root) {
result &= deleteAction(new Action<Boolean>() {
@Override
public Boolean act() throws IOException {
return fs.delete(dir, false);
}
}, "dir");
}
return result;
}上一步中调用了 checkAndDeleteFiles(files) 方法,该方法的作用是:通过每个清理程序运行给定的文件,以查看是否应删除该文件,并在必要时将其删除。输入参数是所有oldWALs目录下的文件
/**
* Run the given files through each of the cleaners to see if it should be deleted, deleting it if
* necessary.
* 通过每个清理程序运行给定的文件,以查看是否应删除该文件,并在必要时将其删除。
* @param files List of FileStatus for the files to check (and possibly delete)
* @return true iff successfully deleted all files
*/
private boolean checkAndDeleteFiles(List<FileStatus> files) {
if (files == null) {
return true;
}
// first check to see if the path is valid
List<FileStatus> validFiles = Lists.newArrayListWithCapacity(files.size());
List<FileStatus> invalidFiles = Lists.newArrayList();
for (FileStatus file : files) {
if (validate(file.getPath())) {
validFiles.add(file);
} else {
LOG.warn("Found a wrongly formatted file: " + file.getPath() + " - will delete it.");
invalidFiles.add(file);
}
}
Iterable<FileStatus> deletableValidFiles = validFiles;
// check each of the cleaners for the valid files
for (T cleaner : cleanersChain) {
if (cleaner.isStopped() || getStopper().isStopped()) {
LOG.warn("A file cleaner" + this.getName() + " is stopped, won't delete any more files in:"
+ this.oldFileDir);
return false;
}
Iterable<FileStatus> filteredFiles = cleaner.getDeletableFiles(deletableValidFiles);
// trace which cleaner is holding on to each file
if (LOG.isTraceEnabled()) {
ImmutableSet<FileStatus> filteredFileSet = ImmutableSet.copyOf(filteredFiles);
for (FileStatus file : deletableValidFiles) {
if (!filteredFileSet.contains(file)) {
LOG.trace(file.getPath() + " is not deletable according to:" + cleaner);
}
}
}
deletableValidFiles = filteredFiles;
}
Iterable<FileStatus> filesToDelete = Iterables.concat(invalidFiles, deletableValidFiles);
return deleteFiles(filesToDelete) == files.size();
}ReplicationLogCleaner 日志清理类
checkAndDeleteFiles方法中 又调用了 cleaner.getDeletableFiles(deletableValidFiles) ,getDeletableFiles方法在ReplicationLogCleaner类下,是判断哪些文件该删除,哪些不该删除,删除条件就是文章开头提出的是否在参与复制中,如果在参与则不删除,不在则删除。
注:所有在参与peer的数据都在 zookeeper 中 /hbase/replication/rs 目录下存储
比如在zookeeper目录下有这么个节点
/hbase/replication/rs/jast.zh,16020,1576397142865/Indexer_account_indexer_prd/jast.zh%2C16020%2C1576397142865.jast.zh%2C16020%2C1576397142865.regiongroup-0.1579283025645那么我们再oldWALs目录下是不会删除掉这个数据的
[jast@jast002 ~]$ hdfs dfs -du -h /hbase/oldWALs/jast015.zh%2C16020%2C1576397142865.jast015.zh%2C16020%2C1576397142865.regiongroup-0.1579283025645 256.0 M 512.0 M /hbase/oldWALs/jast015.zh%2C16020%2C1576397142865.jast015.zh%2C16020%2C1576397142865.regiongroup-0.1579283025645
@Override
public Iterable<FileStatus> getDeletableFiles(Iterable<FileStatus> files) {
// all members of this class are null if replication is disabled,
// so we cannot filter the files
if (this.getConf() == null) {
return files;
}
final Set<String> wals;
try {
// The concurrently created new WALs may not be included in the return list,
// but they won't be deleted because they're not in the checking set.
wals = loadWALsFromQueues();
} catch (KeeperException e) {
LOG.warn("Failed to read zookeeper, skipping checking deletable files");
return Collections.emptyList();
}
return Iterables.filter(files, new Predicate<FileStatus>() {
@Override
public boolean apply(FileStatus file) {
String wal = file.getPath().getName();
//包含文件则保留,不包含则删除
boolean logInReplicationQueue = wals.contains(wal);
if (LOG.isDebugEnabled()) {
if (logInReplicationQueue) {
//包含文件保留
LOG.debug("Found log in ZK, keeping: " + wal);
} else {
//不包含删除
LOG.debug("Didn't find this log in ZK, deleting: " + wal);
}
}
return !logInReplicationQueue;
}});
}上一步调用了 loadWALsFromQueues 方法,该方法作用是:获取所有在复制队列中的wals文件,并返回,
/**
* Load all wals in all replication queues from ZK. This method guarantees to return a
* snapshot which contains all WALs in the zookeeper at the start of this call even there
* is concurrent queue failover. However, some newly created WALs during the call may
* not be included.
*
* 从ZK加载所有复制队列中的所有wals。 即使存在并发队列故障转移,
* 此方法也保证在此调用开始时返回包含zookeeper中所有WAL的快照。
* 但是,可能不会包括通话过程中一些新创建的WAL。
*/
private Set<String> loadWALsFromQueues() throws KeeperException {
for (int retry = 0; ; retry++) {
int v0 = replicationQueues.getQueuesZNodeCversion();
List<String> rss = replicationQueues.getListOfReplicators();
if (rss == null || rss.isEmpty()) {
LOG.debug("Didn't find any region server that replicates, won't prevent any deletions.");
return ImmutableSet.of();
}
Set<String> wals = Sets.newHashSet();
for (String rs : rss) {
//加载zookeeper下,/hbase/replication/rs 目录下所有数据
List<String> listOfPeers = replicationQueues.getAllQueues(rs);
// if rs just died, this will be null
if (listOfPeers == null) {
continue;
}
//加载所有目录
for (String id : listOfPeers) {
List<String> peersWals = replicationQueues.getLogsInQueue(rs, id);
if (peersWals != null) {
wals.addAll(peersWals);
}
}
}
int v1 = replicationQueues.getQueuesZNodeCversion();
if (v0 == v1) {
return wals;
}
LOG.info(String.format("Replication queue node cversion changed from %d to %d, retry = %d",
v0, v1, retry));
}
}总结
至此我们可以发现,删除的过程就是定期执行删除文件线程,从oldWALs获取所有文件,如果在peer复制队列中则不进行副本删除,否则则删除
