孩子不仅是父母的镜子,还是父母的影子。厉害的父母,孩子也往往不会太差。
FCN
- Demo: https://github.com/shelhamer/fcn.berkeleyvision.org
- Last Edited: Mar 29, 2019 9:08 AM
- Tags: FCN
- 论文地址: https://arxiv.org/pdf/1411.4038.pdf
前言
- 全称:Fully Convolution Networks
- 特点:多次特征融合提高分割准确性。
- 改进:将全连接改为卷积。
对于一般的分类CNN网络,如VGG和ResNet,都会在网络的最后加入一些全连接层,经过Softmax后就可以获得类别概率信息。但是这个概率信息是一维的,即只能标识整个图片的类别,不能标识每个像素点的类别,所以这种全连接方法不适合与图片分割。
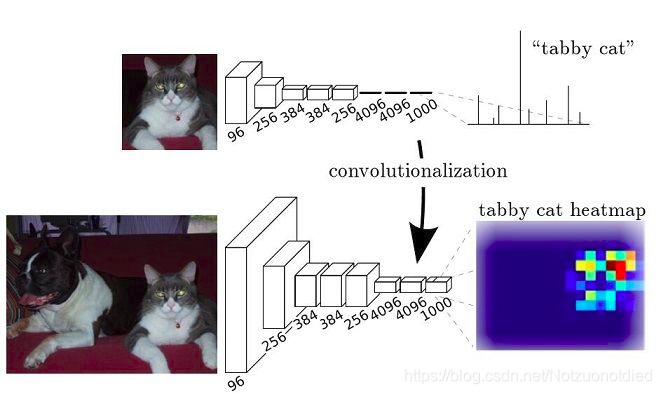
而FCN提出可以把后面几个全连接都换成卷积,这样就可以获得一张2维的feature map,后接Softmax获得每个像素点的分类信息,从而解决了分割问题,如下图所示:
网络结构
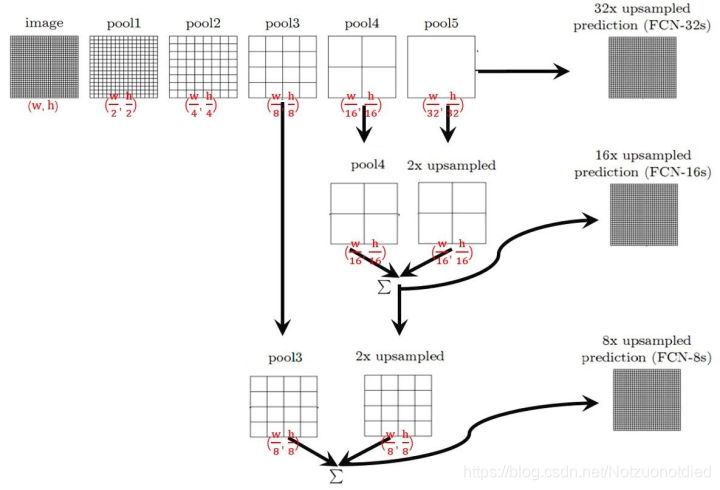
图片image经过多个conv和一个Max Pooling变为Pool1 Feature,宽高变为原来的
;Pool1 Feature经过多个conv和一个Max Pooling变为Pool2 Feature,宽高变为
;同理,直到Pool5 Feature,宽高变为
。
对于FCN-32s,直接对Pool5 Feature进行32倍上采样获得32xUpsampled Feature,再对32xUpsampled Feature每个点做Softmax Prediction获得32xUpsampled Feature Prediction(即分割图)。对于FCN-16s,首先对Pool5 Feature进行2倍上采样获得2xUpsampled Feature,再把Pool4 Feature和2xUpsampled Feature逐点相加,然后对相加的Feature进行16倍上采样,并Softmax Prediction,获得16xUpsampled Feature Prediction。对于FCN-8s,首先进行Pool4+2xUpsampled Feature逐点相加,然后又进行Pool3+2xUpsampled逐点相加,即进行更多次特征融合。具体过程与16s类似,不再赘述。
效果对比
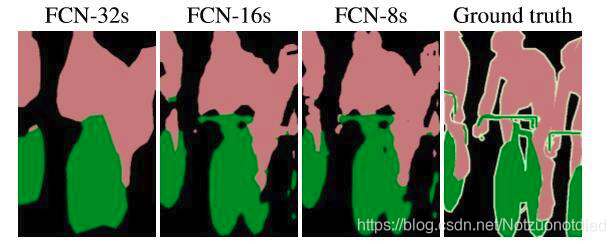
作者在原文种给出3种网络结果对比,明显可以看出效果:FCN-32s < FCN-16s < FCN-8s,即使用多层feature融合有利于提高分割准确性。
缺点
- 是得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
- 忽略高分辨率的特征图肯定会导致边缘信息的丢失。
- 是对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
