演示动画来源于:https://www.cnblogs.com/onepixel/p/7674659.html
算法分类
插入类
- 插入排序
- 希尔排序
交换类
- 冒泡排序
- 快速排序
选择类
- 选择排序
- 堆排序
归并类
- 归并排序
排序算法的性能指标:
- 时间复杂度
- 空间复杂度
- 稳定性1
具体原理以及实现
插入排序
- 算法描述:
从数组的第一个元素开始,认定该元素已经被排序,然后取下一个元素,对于已经排序的元素序列中从后往前扫描,如果已经排序的某一个元素大于新元素,则将这个元素往后移一个位置,重复此操作,直至找到已排序的某元素小于等于这个新元素,然后将这个新元素插入到该元素的后面。然后遍历余下的数组;
- 从第一个元素开始,认定该元素已被排序
- 取下一个元素,对于已经排序的元素序列中从后往前扫描
- 如果已经排序的某一个元素大于新元素,则将这个元素往后移一个位置
- 重复上一操作,直至找到已排序的某元素小于等于这个新元素
- 将这个新元素插入到该元素的后面
- 继续遍历余下的数组
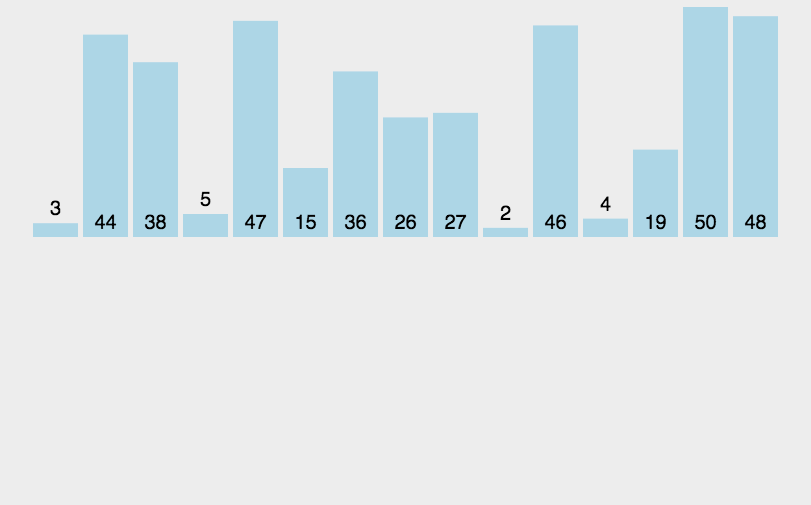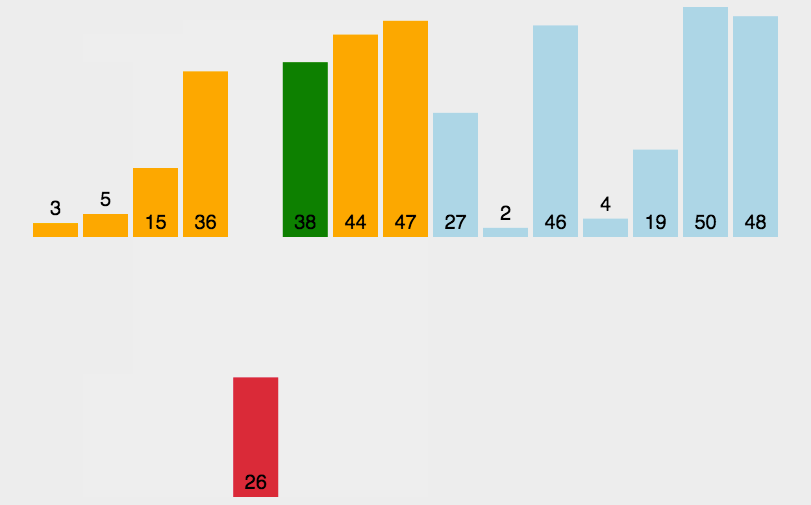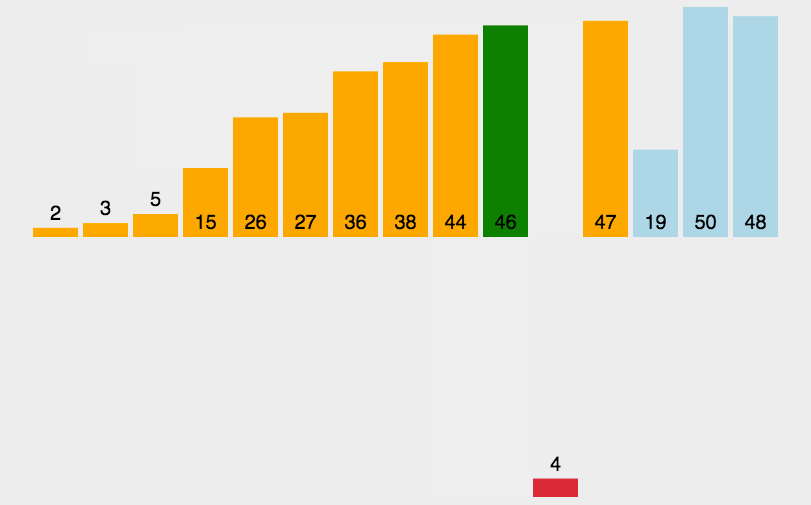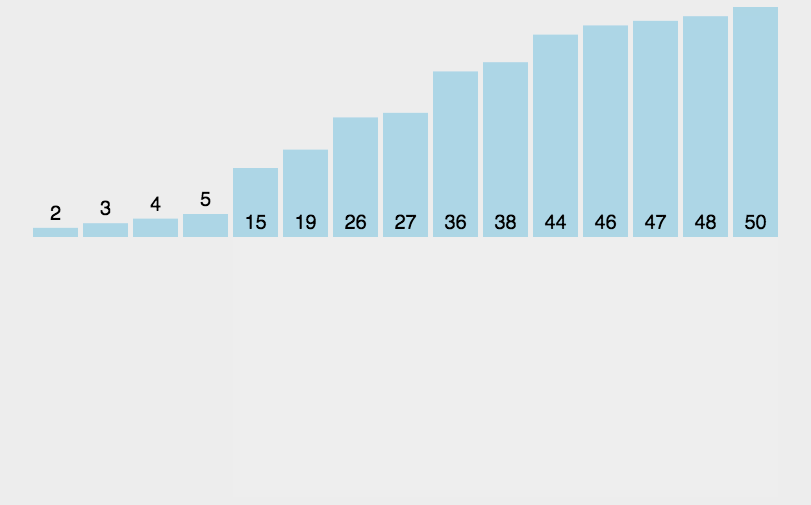
- 性能:
时间复杂度:O( )
空间复杂度:O(1)
稳定性:稳定 - 代码实现:
//插入排序
//传进来的是数组的首地址,以及数组的长度,返回的也是数组的首地址
int* InsertSort(int *a,int lena)
{
//preindex是指有序数组的索引,会随比较而发生变化,tmp是将要进行插入的元素
int preindex,tmp;
for (int i = 1; i < lena; i++)
{
//tmp初始化
tmp=a[i];
//初始化为i-1
preindex = i-1;
//插入前的比较
while(preindex>=0 &&a[preindex]>tmp)
{
a[preindex+1]=a[preindex];
preindex--;
}
//preindex现在就是那个小于等于新元素的位置,插入其后
a[preindex+1]=tmp;
}
return a;
}
希尔排序
- 算法描述:
又称为“缩小增量排序”,属于直接插入排序算法的一个升级版本,实现希尔排序需要手动或者动态的设置一个递减的增量数组,这个数组最后一个数必须是1, ,有了这个增量数组之后,就要对需要排序的数组b进行k次排序,每一次排序都要顺序对应用到一个增量;这个增量 的作用通俗一点来说就是对索引下标进行操作,如 进行插入排序, 进行比较…依次类推,直至无法再进行比较;然后再换下一个增量,直至结束;
-选择或者动态一个递减的增量序列
-进行k次排序
-每一次排序,对应一个a,分为若干排序小组,对于这若干个排序小组进行插入排序;
-遍历直至增量为1
增量数组为 5,2,1 注:此动图旨在帮助更好的理解这个算法,实际过程中是多组交替执行的
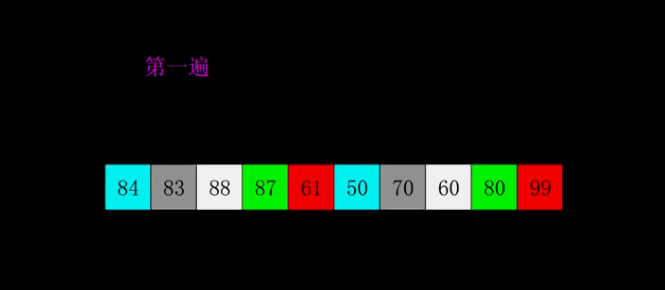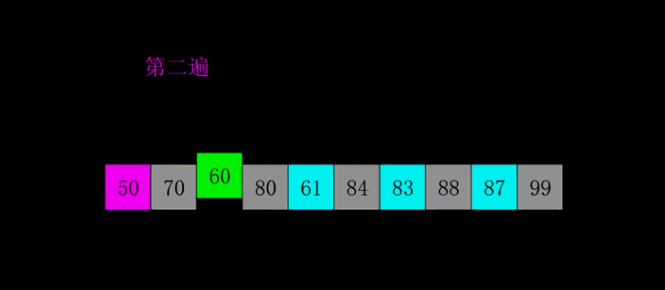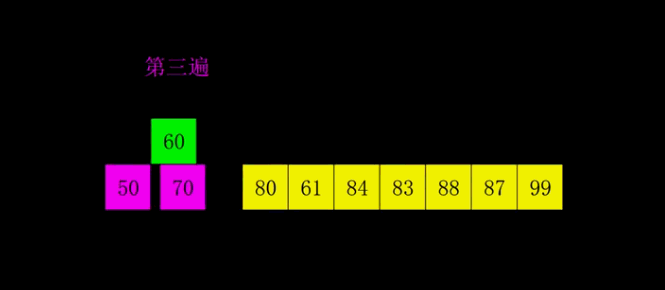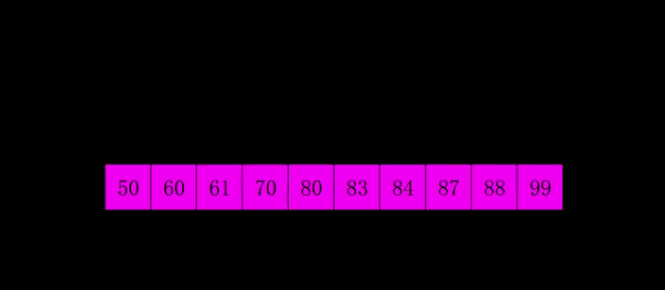
- 性能:
时间复杂度:O( )
空间复杂度:O(1)
稳定性:不稳定 - 代码实现:
//希尔排序
//传进来的是数组的首地址,以及数组的长度,返回的也是数组的首地址
int * ShellSort(int *a,int lena)
{
//对于增量序列,采用动态,不再手动设置
//k就是动态的增量
for (int k = lena/2; k >0; k=k/2)
{
//preindex是指有序数组的索引,会随比较而发生变化,tmp是将要进行插入的元素
int preindex,tmp;
for (int i = k; i < lena; i++)
{
//初始化tmp
tmp=a[i];
//初始化为i-k
preindex=i-k;
//插入前的比较
while(preindex>=0&&a[preindex]>tmp)
{
a[preindex+k]=a[preindex];
preindex-=k;
}
//preindex现在就是那个小于等于新元素的位置,插入其后
a[preindex+k]=tmp;
}
}
return a;
}
冒泡排序
- 算法描述:
这是一个比较笨但是又特别明了的一个算法,核心就是重复走n次,每一次遍历,都要比较相邻的两个元素,如果为逆序,那么则把元素交换位置,否则继续下一个比较,直至n躺走完
- 比较相邻的两个元素,如果为逆序,则交换
- 然后接着遍历,直至结束
- 重复以上步骤n次
2. 性能:
时间复杂度:O(
)
空间复杂度:O(1)
稳定性:稳定排序
3. 代码演示:
//冒泡排序
//传进来的是数组的首地址,以及数组的长度,返回的也是数组的首地址
int* BubbleSort(int *a,int lena)
{
int tmp;
for (int i = 0; i < lena-1; i++)
{
for (int j = 0; j < lena-1-i; j++)
{
if(a[j]>a[j+1])
{
tmp=a[j+1];
a[j+1]=a[j];
a[j]=tmp;
}
}
}
return a;
}
快速排序
- 算法描述:
快速排序是一个收益比较好的一个排序,其核心思想是对于每一次排序,均选择一个枢轴(pivot),然后小于枢轴的数放在左边,大于的数放在右边,然后进行对左边右边的数进行递归快速排序;
- 从数组中跳出一个元素作为枢轴
- 所有比枢轴小的元素放在枢轴左边,大的元素则放在枢轴右边
- 对左右均进行递归的快排
- 性能:
时间复杂度:O( )
空间复杂度:O( )
稳定性:不稳定排序 - 代码演示:
//快速排序
//传进来的是数组的首地址,以及开始结束的索引
void QuickSort(int *a, int left, int right)
{
//初始化,pivot是枢轴
int i = left, j = right, pivot;
//快速排序结束标志
if (i >= j)
return;
//每一次排序开始便初始化枢轴
pivot = a[i];
while (i < j)
{
while (i < j && a[j] > pivot)
j--;
a[i] = a[j];
while (i < j && a[i] <= pivot)
i++;
a[j] = a[i];
}
a[i] = pivot;
QuickSort(a, left, i);
QuickSort(a, i + 1, right-1);
}
选择排序
- 算法描述:
这是一个简单直白的排序方式,很切合一般人的思维,核心思想就是进行n-1次排序,每一次排序都选择一个最小值,然后将选好的最小值放入有序区(从索引0开始),然后开始对无序区接着排序,有序无序区均用同一个数组。
-初始化,有序区为空,无序区为a[0]…a[n-1]
-第i次排序,从a[i-1]开始一直到末尾,选出最小的一个,然后与a[i-1]互换
-重复n-1次
- 性能
时间复杂度:O( )
空间复杂度:O(1)
稳定性:不稳定排序 - 代码演示:
//选择排序
//传进来的是数组的首地址,以及数组的长度,返回的也是数组的首地址
int* SelectSort(int *a,int lena)
{
int minindex,tmp;
for (int i = 0; i < lena-1; i++)
{
minindex=i;
for (int j = i+1; j < lena; j++)
{
if(a[j]<a[minindex])
minindex=j;
}
tmp=a[i];
a[i]=a[minindex];
a[minindex]=tmp;
}
return a;
}
堆排序
- 算法描述
堆排序是利用了堆这种数据结构,因为堆本身就要满足堆积的性质:孩子结点的键值小于其父节点(本博客中使用这个性质)。那么就先初始化一个这样的大顶堆,,将次堆分为两部分,一部分是无序的大顶堆,另一部分就是有序的排列数组,然后将堆顶元素与无序的大顶堆最后一个元素交换,交换后的无序堆的最后一个归为有序数组;然后重复此操作;
-初始化大顶堆
-将堆顶的元素与无序区的最后一个元素交换
-交换后的无序区的最后一个元素,归为有序区
-重复n次

- 性质:
时间复杂度:O( )
空间复杂度:O(n)
稳定性:不稳定排序 - 代码演示:
//堆排序,代码来源于https://www.cnblogs.com/skywang12345/p/3602162.html#a42
//辅助函数,(最大)堆的向下调整算法
void maxHeapDown(int *a, int start, int end)
{
int c = start; // 当前(current)节点的位置
int l = 2 * c + 1; // 左(left)孩子的位置
int tmp = a[c]; // 当前(current)节点的大小
for (; l <= end; c = l, l = 2 * l + 1)
{
// "l"是左孩子,"l+1"是右孩子
if (l < end && a[l] < a[l + 1])
l++; // 左右两孩子中选择较大者,即m_heap[l+1]
if (tmp >= a[l])
break; // 调整结束
else // 交换值
{
a[c] = a[l];
a[l] = tmp;
}
}
}
//传进来的是数组的首地址,以及数组的长度
void HeapSort(int *a, int n)
{
int i, tmp;
// 从(n/2-1) --> 0逐次遍历。遍历之后,得到的数组实际上是一个(最大)二叉堆。
for (i = n / 2 - 1; i >= 0; i--)
maxHeapDown(a, i, n - 1);
// 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素
for (i = n - 1; i > 0; i--)
{
// 交换a[0]和a[i]。交换后,a[i]是a[0...i]中最大的。
tmp = a[0];
a[0] = a[i];
a[i] = tmp;
// 调整a[0...i-1],使得a[0...i-1]仍然是一个最大堆。
// 即,保证a[i-1]是a[0...i-1]中的最大值。
maxHeapDown(a, 0, i - 1);
}
}
归并排序
- 算法描述:
归并排序是建立在归并操作上的一种有效的排序方法;其总共有两个步骤,一是分割,二是集成;对于一个无序的序列,要递归的把当前序列平均分割为两半,然后对这个子序列在保持元素顺序的同时进行集成(归并)操作,最后将两个排序好的子序列合并为一个最终的排序的序列;
-把一个无序的序列平均分为两部分
-对于两个子序列分别采用归并排序(实质上就是递归)
-将两个排序的子序列合并为一个最终的排序的序列;
- 性能:
时间复杂度:O( )
空间复杂度:O(n)
稳定性:不稳定排序 - 代码演示:
//归并排序,代码来源于:https://blog.csdn.net/zpznba/article/details/83745205
//归并排序辅助函数
void Merge(int* arr, int l, int q, int r)
{
int n = r - l + 1; //临时数组存合并后的有序序列
int *tmp = new int[n];
int i = 0;
int left = l;
int right = q + 1;
while (left <= q && right <= r)
tmp[i++] = arr[left] <= arr[right] ? arr[left++] : arr[right++];
while (left <= q)
tmp[i++] = arr[left++];
while (right <= r)
tmp[i++] = arr[right++];
for (int j = 0; j < n; ++j)
arr[l + j] = tmp[j];
delete[] tmp; //删掉堆区的内存
}
//传进来的是数组的首地址,以及l是左索引,r是右索引
void MergeSort(int* arr, int l, int r)
{
if (l == r)
return; //递归基是让数组中的每个数单独成为长度为1的区间
int q = (l + r) / 2;
MergeSort(arr, l, q);
MergeSort(arr, q + 1, r);
Merge(arr, l, q, r);
}
总和代码
#include <iostream>
using namespace std;
struct SortFunction
{
//插入排序
//传进来的是数组的首地址,以及数组的长度
void InsertSort(int *a, int lena)
{
//preindex是指有序数组的索引,会随比较而发生变化,tmp是将要进行插入的元素
int preindex, tmp;
for (int i = 1; i < lena; i++)
{
//tmp初始化
tmp = a[i];
//初始化为i-1
preindex = i - 1;
//插入前的比较
while (preindex >= 0 && a[preindex] > tmp)
{
a[preindex + 1] = a[preindex];
preindex--;
}
//preindex现在就是那个小于等于新元素的位置,插入其后
a[preindex + 1] = tmp;
}
}
//希尔排序
//传进来的是数组的首地址,以及数组的长度
void ShellSort(int *a, int lena)
{
//对于增量序列,采用动态,不再手动设置
//k就是动态的增量
for (int k = lena / 2; k > 0; k = k / 2)
{
//preindex是指有序数组的索引,会随比较而发生变化,tmp是将要进行插入的元素
int preindex, tmp;
for (int i = k; i < lena; i++)
{
//初始化tmp
tmp = a[i];
//初始化为i-k
preindex = i - k;
//插入前的比较
while (preindex >= 0 && a[preindex] > tmp)
{
a[preindex + k] = a[preindex];
preindex -= k;
}
//preindex现在就是那个小于等于新元素的位置,插入其后
a[preindex + k] = tmp;
}
}
}
//冒泡排序
//传进来的是数组的首地址,以及数组的长度
void BubbleSort(int *a, int lena)
{
int tmp;
for (int i = 0; i < lena - 1; i++)
{
for (int j = 0; j < lena - 1 - i; j++)
{
if (a[j] > a[j + 1])
{
tmp = a[j + 1];
a[j + 1] = a[j];
a[j] = tmp;
}
}
}
}
//快速排序
//传进来的是数组的首地址,以及开始结束的索引
void QuickSort(int *a, int left, int right)
{
//初始化,pivot是枢轴
int i = left, j = right, pivot;
//快速排序结束标志
if (i >= j)
return;
//每一次排序开始便初始化枢轴
pivot = a[i];
while (i < j)
{
while (i < j && a[j] > pivot)
j--;
a[i] = a[j];
while (i < j && a[i] <= pivot)
i++;
a[j] = a[i];
}
a[i] = pivot;
QuickSort(a, left, i);
QuickSort(a, i + 1, right - 1);
}
//选择排序
//传进来的是数组的首地址,以及数组的长度
void SelectSort(int *a, int lena)
{
int minindex, tmp;
for (int i = 0; i < lena - 1; i++)
{
minindex = i;
for (int j = i + 1; j < lena; j++)
{
if (a[j] < a[minindex])
minindex = j;
}
tmp = a[i];
a[i] = a[minindex];
a[minindex] = tmp;
}
}
//堆排序,代码来源于https://www.cnblogs.com/skywang12345/p/3602162.html#a42
//辅助函数,(最大)堆的向下调整算法
void maxHeapDown(int *a, int start, int end)
{
int c = start; // 当前(current)节点的位置
int l = 2 * c + 1; // 左(left)孩子的位置
int tmp = a[c]; // 当前(current)节点的大小
for (; l <= end; c = l, l = 2 * l + 1)
{
// "l"是左孩子,"l+1"是右孩子
if (l < end && a[l] < a[l + 1])
l++; // 左右两孩子中选择较大者,即m_heap[l+1]
if (tmp >= a[l])
break; // 调整结束
else // 交换值
{
a[c] = a[l];
a[l] = tmp;
}
}
}
//传进来的是数组的首地址,以及数组的长度
void HeapSort(int *a, int n)
{
int i, tmp;
// 从(n/2-1) --> 0逐次遍历。遍历之后,得到的数组实际上是一个(最大)二叉堆。
for (i = n / 2 - 1; i >= 0; i--)
maxHeapDown(a, i, n - 1);
// 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素
for (i = n - 1; i > 0; i--)
{
// 交换a[0]和a[i]。交换后,a[i]是a[0...i]中最大的。
tmp = a[0];
a[0] = a[i];
a[i] = tmp;
// 调整a[0...i-1],使得a[0...i-1]仍然是一个最大堆。
// 即,保证a[i-1]是a[0...i-1]中的最大值。
maxHeapDown(a, 0, i - 1);
}
}
//归并排序,代码来源于:https://blog.csdn.net/zpznba/article/details/83745205
//归并排序辅助函数
void Merge(int* arr, int l, int q, int r)
{
int n = r - l + 1; //临时数组存合并后的有序序列
int *tmp = new int[n];
int i = 0;
int left = l;
int right = q + 1;
while (left <= q && right <= r)
tmp[i++] = arr[left] <= arr[right] ? arr[left++] : arr[right++];
while (left <= q)
tmp[i++] = arr[left++];
while (right <= r)
tmp[i++] = arr[right++];
for (int j = 0; j < n; ++j)
arr[l + j] = tmp[j];
delete[] tmp; //删掉堆区的内存
}
//传进来的是数组的首地址,以及l是左索引,r是右索引
void MergeSort(int* arr, int l, int r)
{
if (l == r)
return; //递归基是让数组中的每个数单独成为长度为1的区间
int q = (l + r) / 2;
MergeSort(arr, l, q);
MergeSort(arr, q + 1, r);
Merge(arr, l, q, r);
}
} Sort;
int main()
{
int a[5] = {5, 6, 2, 6, 1};
Sort.MergeSort(a,0,4);
for (int i = 0; i < 5; i++)
{
cout << a[i] << endl;
}
return 0;
}
该处的稳定性是指遇到相同内容的元素后,排序之后有关相同元素的顺序是否发生改变;例如原数据元素序列为: ,我们可以发现有两个5,而经过某排序后,序列为: 的为稳定排序,否则为不稳定排序 ↩︎
