目录
多维数组做函数参数退化原因剖析
首先,要明白的是,之所以有退化这个问题,是编译器注重传递效率的结果,比如,将一个高维数组,作为函数参数传入,如果整个数组都传入的话,那会很慢,所以,只传内存的首地址,就快了许多了。这也是退化的原因。
但是,这还不是其退化的最本质的原因, 所有的一维和二维都是程序员人为的规定的,但对C/C++编译器来讲,内存永远是线性的!所有的一维二维,都是人为的,理解性的描述,

那就证明一下多维数组是按线性分布的,就将一个多维数组按一维的方式去打印,看结果如何:
void printfArray01(int *array, int size)
{
int i = 0;
for (i=0; i<size; i++)
{
printf("%d ", array[i]);
}
}
void main331()
{
int a[3][5];
int i, j, tmp = 1;
for (i=0; i<3; i++)
{
for (j=0; j<5; j++)
{
a[i][j] = tmp++;
}
}
//把二维数组 当成 1维数组 来打印 证明线性存储
printfArray01((int *)a, 15);
printf("hello...\n");
system("pause");
return ;
}显示结果:
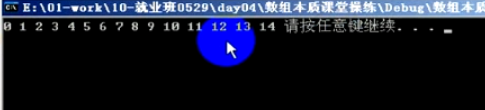
多维数组做函数参数,一般情况下只能表达到二维,如果是三维,在现实工程开发中,一般是没有意义的。
一般情况,一级指针代表一维,二级指针代表二维,如果有超过三级指针及三级以上的指针,则不代表几维的内存。。。。;产生这个线性的原因,是因为多维数组是线性排布的。
所以,再说一遍多维数组,比如a[3][10],其中,"[3]"部分是可以挖掉的,但"[10]"部分是不能挖掉的,因为后边这个觉得了首地址跳一次,往后推多少单元,在这个例子中就是,指向a的地址,往后跳一下,元素就往后跳10个元素,这个10就是低维的数组长度。
那么如何证明内存是线性的呢?
那么用线性的方式去打印一个二维数组,如果打印的顺序和存放数组的顺序一致,就说明内存也是线性分布的了。

多维数组指针做函数参数的完整退化过程:
//一维数组的退化过程
//int a[10] ===》int a[] ===> int *a
//多维数组的退化过程
//char buf[10][30] ===>
int printfArray(char buf[10][30]); //人为理解的
int printfArray(char buf[][30]); //4k (中间过渡一下)
int printfArray(int (*buf)[30]); //实际编译器是按这样的过程执行的buf本身是一个指针数组, 相当于:
{
int (*buf)[30]; //定义了一个变量
//数组指针的直接定义方式
}这里需要详细的记录一下了:对于一维数组来说,当指针做函数参数的时候退化成这个数组的首地址,即上面的"int *a",这个可以理解,只要找到了数组的首地址,不就把这个数组给找到了吗?所以,为了效率,退化就退化了;
当到多维数组的时候,指针做函数参数的时候如何找它的首地址呢?经过前几篇博客的铺垫,可以指定,多维数组,本质是一个数组指针,那么以buf为例,最低层是30个单元,那么按照数组指针的方式去找到对应的这第一个30单元的首地址,就可以了,那么buf是数组指针,(*buf)[30]是数组指针的直接定义方式(详见Record24)。
另外,多维数组,本质是数组指针,也不是指针的反复
那么,如何用呢?下面举一个例子,只用看函数开头就行了,直接就把二级指针给写成了上面的版本,写成最后那种版本,一看就知道是个老手了:
int spitString02( char *buf1, char c, char (*buf)[30], int *num)
{
int ret = 0;
char *p = NULL;
char *pTmp = NULL;
int ncount = 0;
if (buf1==NULL || num==NULL)
{
return -1;
}
//步骤1 初始化条件 pTmp,p都执行检索的开头
p = buf1;
pTmp = buf1;
do
{
//步骤2 strstr strchr,会让p后移 在p和pTmp之间有一个差值
p = strchr(p, c);
if (p == NULL) //没有找到则跳出来
{
break;
}
else
{
//挖字符串
strncpy(buf[ncount], pTmp, p-pTmp);
buf[ncount][p-pTmp] = '\0';
ncount++;
//步骤3 让p和pTmp重新初始化,达到检索的条件
pTmp = p = p + 1;
}
} while (*p != '\0');
//printf("ncout:%d\n", ncount);
*num = ncount;
return ret;
}数组的一级指针和二级指针再进行区分
char cbuf[30]; //cbuf(1级指针) 代表数组首元素的地址 。。。。&cbuf(二级指针)代表整个数组的地址
char array[10][30]; //array是二级指针这两个为例进行对比,cbuf是一个一维数组,array是一个多维数组,cbuf这个变量本身是个一级指针,所代表的是数组首元素的地址;array这个变量本身是二级指针。这里要着重讲一下:
"array+i",相当于 第i行的首地址,这同时也是个二级指针;
"(*(array + i))" ,相当于一级指针了就。因为(array+i)相当于二级指针,取对其“*”后,相当于回到了一级指针首地址了;
"(*(array + i)+j)", 如果,对首地址再加一(*(array + i)+j),相当于第i行第列的地址了;
" *((*(array + i))+j)", 如果继续再加上"*"号: *((*(array + i))+j),那么,这就相当于array[i][j]所存放的值了;
根据以上所总结的,要清楚的是,(array+0)本身代表的是第0行数组的首地址,(*(array+0)+0)代表是第0行数组的第0个元素的地址。(“*”符是地址的还原);那么*(*(array+0)+0)才是代表的是第0行数组的第0个元素的值!这才是多维数组的真相!
为啥说array是个二级指针呢,我的理解是,从值看,到array的时候(*(*(array+0)+0) ==》 (array+0)),的确已经传递了两次指针了(用了两次“*”号了)。
总体代码
#define _CRT_SECURE_NO_WARNINGS
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
void printfArray01(int *array, int size)
{
int i = 0;
for (i=0; i<size; i++)
{
printf("%d ", array[i]);
}
}
void main331()
{
int a[3][5];
int i, j, tmp = 1;
for (i=0; i<3; i++)
{
for (j=0; j<5; j++)
{
a[i][j] = tmp++;
}
}
//把二维数组 当成 1维数组 来打印 证明线性存储
printfArray01((int *)a, 15);
printf("hello...\n");
system("pause");
return ;
}demo03_多维数组做函数参数退化技术推演.c
//demo03_多维数组做函数参数退化技术推演.c
#include "stdio.h"
#include "string.h"
#include "stdlib.h"
//int a[10] ===int a[] int *a
//char buf[10][30] ===>
int printfArray(char buf[10][30]); //3k
int printfArray(char buf[][30]); //4k
int printfArray(int (*buf)[30]); //5k
//int spitString02( char *buf1, char c, char buf[10][30], int *num)
//int spitString02( char *buf1, char c, char buf[][30], int *num)
int spitString02( char *buf1, char c, char (*buf)[30], int *num)
{
int ret = 0;
char *p = NULL;
char *pTmp = NULL;
int ncount = 0;
if (buf1==NULL || num==NULL)
{
return -1;
}
//步骤1 初始化条件 pTmp,p都执行检索的开头
p = buf1;
pTmp = buf1;
do
{
//步骤2 strstr strchr,会让p后移 在p和pTmp之间有一个差值
p = strchr(p, c);
if (p == NULL) //没有找到则跳出来
{
break;
}
else
{
//挖字符串
strncpy(buf[ncount], pTmp, p-pTmp);
buf[ncount][p-pTmp] = '\0';
ncount++;
//步骤3 让p和pTmp重新初始化,达到检索的条件
pTmp = p = p + 1;
}
} while (*p != '\0');
//printf("ncout:%d\n", ncount);
*num = ncount;
return ret;
}
void main()
{
int ret = 0, i = 0;
char *buf1 = "abcdef,acccd,";
char c = ',';
char buf[10][30];
int num = 0;
ret = spitString02(buf1, c, buf, &num);
if (ret != 0)
{
printf("func spitString() err:%d\n", ret);
return ;
}
for (i=0; i<num; i++)
{
printf("%s\n", buf[i]);
}
system("pause");
}
