1.决策树
如下图所示的流程图就是一个决策树,长方形代表判断模块(decision block)某维特征,椭圆形成代表终止模块(terminating block)得到的标签,表示已经得出结论,可以终止运行。
决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类。

以 04.朴素贝叶斯分类 中用到的数据为例 描述决策树的构建过程

数据简单描述:
- 1、特征维度为2维(病症、职业),标签(疾病)
- 2、病症这维特征有2个属性值
打喷嚏、头痛 - 3、职业特征有4个属性值
护士、农夫、建筑工人、教师 - 4、标签(疾病)有3个值
感冒、过敏、脑震荡
决策树是从内部结点(某维特征)开始往下生长,如果长成叶结点(只有1个类别)不在往下生长,否则会一直生长下去直到长成叶结点或者是用完了所有内部结点(所有特征都用完了)
选择病症做根结点生长

选择职业做根结点生长
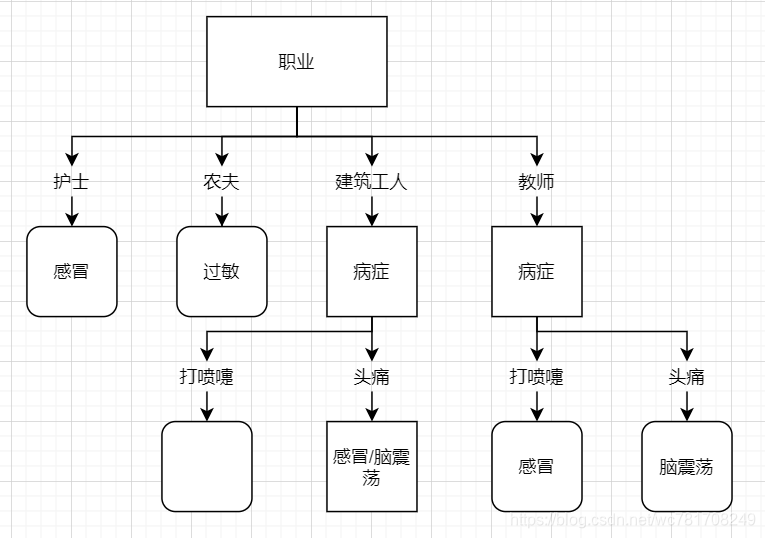
我们发现构建的树并不一样,那到底以哪个特征作为根结点开始生长?可以使用信息增益
2.香农熵
集合信息的度量方式称为香农熵或者简称为熵(entropy),这个名字来源于信息论之父克劳德·香农。
熵定义为信息的期望值。在信息论与概率统计中,熵是表示随机变量不确定性的度量。如果待分类的事物可能划分在多个分类之中,则符号
的信息定义为 :
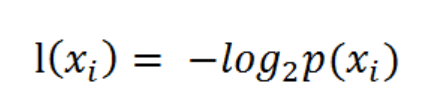
其中
是选择该分类的概率。上述式中的对数以2为底,也可以
为底(自然对数)。
通过上式,我们可以得到所有类别的信息。为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值(数学期望),通过下面的公式得到:
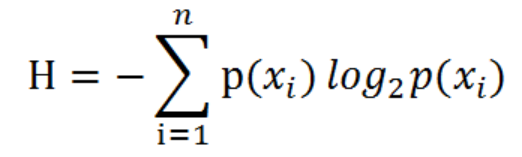
其中 是分类的数目。熵越大,随机变量的不确定性就越大。
当熵中的概率由数据估计(特别是最大似然估计)得到时(概率由频率代替,根据大数定律,频率会接近于概率),所对应的熵称为经验熵(empirical entropy)。
训练数据集D,则训练数据集D的经验熵为
,
表示其样本容量,及样本个数。设有K个类
,
为属于类
的样本个数,因此经验熵公式就可以写为 :
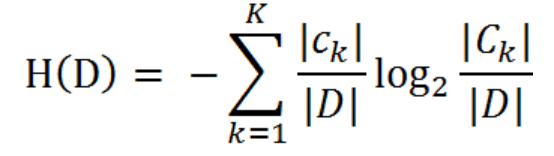
根据这个公式我们可以计算上面数据的经验熵:
3.信息增益
在讲解信息增益定义之前,我们还需要明确一个概念,条件熵。
条件熵
表示在已知随机变量
的条件下随机变量
的不确定性,随机变量X给定的条件下随机变量Y的条件熵(conditional entropy)
,定义为
给定条件下
的条件概率分布的熵对
的数学期望:

同理,当条件熵中的概率由数据估计(特别是极大似然估计)得到时(使用频率代替概率),所对应的条件熵称为条件经验熵(empirical conditional entropy)。
信息增益是相对于特征而言的。所以,特征A对训练数据集D的信息增益
,定义为集合D的经验熵
与特征A给定条件下D的经验条件熵
之差,即:

一般地,熵
与条件熵
之差称为互信息(mutual information)。决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
设特征A有n个不同的取值
,根据特征A的取值将D划分为n个子集
,
为
的样本个数。记子集
中属于
的样本的集合为
,即
,
为
的样本个数。于是经验条件熵的公式可以些为:
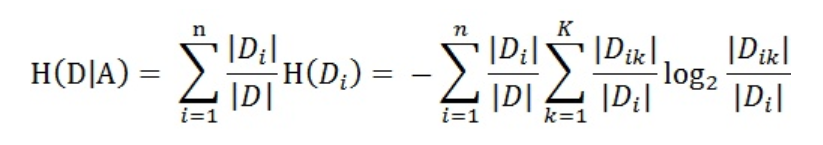
以病历数据数据为例
取特征A为病症,取值为
,根据取值划分子集为
则信息增益为:
按照上述方式计算取特征为职业对应的信息增益为:
因为职业对应的信息增益最大,因此取职业作为结点构建决策树
4.决策树生成
构建决策树的算法有很多,比如C4.5、ID3和CART,这些算法在运行时并不总是在每次划分数据分组时都会消耗特征。由于特征数目并不是每次划分数据分组时都减少,因此这些算法在实际使用时可能引起一定的问题。
决策树生成算法递归地产生决策树,直到不能继续下去未为止。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,即出现过拟合现象。过拟合的原因在于学习时过多地考虑如何提高对训练数据的正确分类,从而构建出过于复杂的决策树。解决这个问题的办法是考虑决策树的复杂度,对已生成的决策树进行简化。
5.实例
iris分类
"""
Author:wucng
Time: 20200113
Summary: 决策树对iris数据分类
源代码: https://github.com/wucng/MLAndDL
参考:https://cuijiahua.com/blog/2017/11/ml_3_decision_tree_2.html
"""
from math import log2
import numpy as np
import pandas as pd
from collections import Counter
import operator
import pickle,os
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
def loadData(dataPath,sep=","):
df = pd.read_csv(dataPath,sep=sep)
df = df.drop("ID",axis=1)
"""
# 文本量化
df.loc[df["病症"] == "打喷嚏", "病症"] = 0
df.loc[df["病症"] == "头痛", "病症"] = 1
df.loc[df["职业"] == "护士", "职业"] = 0
df.loc[df["职业"] == "农夫", "职业"] = 1
df.loc[df["职业"] == "建筑工人", "职业"] = 2
df.loc[df["职业"] == "教师", "职业"] = 3
df.loc[df["疾病"] == "感冒", "疾病"] = 0
df.loc[df["疾病"] == "过敏", "疾病"] = 1
# df.loc[df["疾病"] == "脑震荡", "疾病"] = 2
df.replace("脑震荡",2,inplace=True)
"""
return df.to_numpy(),list(df.columns)[:-1]
# 1.加载数据集(并做预处理)
def loadData2(dataPath: str) -> tuple:
# 如果有标题可以省略header,names ;sep 为数据分割符
df = pd.read_csv(dataPath, sep=",", header=-1,
names=["sepal_length", "sepal_width", "petal_length", "petal_width", "label"])
# 填充缺失值
df = df.fillna(0)
# 数据量化
# 文本量化
df.replace("Iris-setosa", 0, inplace=True)
df.replace("Iris-versicolor", 1, inplace=True)
df.replace("Iris-virginica", 2, inplace=True)
"""
# 特征值做离散化
df.loc[df["sepal_length"] < df["sepal_length"].median(), "sepal_length"] = 0
df.loc[df["sepal_length"] >= df["sepal_length"].median(), "sepal_length"] = 1
df.loc[df["sepal_width"] < df["sepal_width"].median(), "sepal_width"] = 0
df.loc[df["sepal_width"] >= df["sepal_width"].median(), "sepal_width"] = 1
df.loc[df["petal_length"] < df["petal_length"].median(), "petal_length"] = 0
df.loc[df["petal_length"] >= df["petal_length"].median(), "petal_length"] = 1
df.loc[df["petal_width"] < df["petal_width"].median(), "petal_width"] = 0
df.loc[df["petal_width"] >= df["petal_width"].median(), "petal_width"] = 1
"""
X = df.drop("label", axis=1) # 特征数据
y = df.label # or df["label"] # 标签数据
return (X.to_numpy(), y.to_numpy(),list(X.columns))
class DecisonTreeClassifierSelf(object):
def __init__(self,save_file="./model.ckpt"):
self.save_file = save_file
# 计算经验熵
def __calEmpiricalEntropy(self,dataset):
label = dataset[..., -1]
label_dict = dict(Counter(label))
entropy = 0
for k, v in label_dict.items():
p = v / len(label)
entropy += p * log2(p)
entropy *= -1
return entropy
# 条件熵
def __calConditionalEntropy(self,dataset, feature_index=0):
label = dataset[..., -1]
select_feature = dataset[..., feature_index]
uniqueValue = set(select_feature)
conditionalEntropy = 0
# 根据唯一值划分成子集
for value in uniqueValue:
select_rows = select_feature == value
# subset_feature = select_feature[select_rows]
subset_label = label[select_rows]
conditionalEntropy += len(subset_label) / len(label) * self.__calEmpiricalEntropy(subset_label[..., None])
# conditionalEntropy *= -1 # 计算calEmpiricalEntropy 已乘上了-1
return conditionalEntropy
# 根据信息增益选择最佳的特征进行分裂生长
# 信息增益 = 经验熵-条件熵
def __chooseBestFeatureToSplit(self,dataset):
# 特征个数
numFeatures = dataset.shape[1] - 1 # 有列是label
baseEntropy = self.__calEmpiricalEntropy(dataset)
bestInfoGain = - 9999
bestFeature = -1
for i in range(numFeatures):
infoGain = baseEntropy - self.__calConditionalEntropy(dataset, i)
# print("第%d个特征的增益为%.3f" % (i, infoGain))
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def __majorityCnt(self,classList):
classCount = dict(Counter(classList))
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) # 根据字典的值降序排序
return sortedClassCount[0][0] # 返回classList中出现次数最多的元素
def __splitDataSet(self,dataSet, axis, value):
retDataSet = [] # 创建返回的数据集列表
for featVec in dataSet: # 遍历数据集
if featVec[axis] == value:
reducedFeatVec = featVec[:axis].tolist() # 去掉axis特征
reducedFeatVec.extend(featVec[axis + 1:]) # 将符合条件的添加到返回的数据集
retDataSet.append(reducedFeatVec)
return np.asarray(retDataSet)
# 函数说明:创建决策树
def __createTree(self,dataset, labels, featLabels):
"""
如果完全分成1个类别则为叶结点,停止生长
如果没有完全分成1个类别,但是没有可使用的特征,停止生长,并选择类别个数最多的作为叶结点
"""
classList = dataset[..., -1].tolist()
if classList.count(classList[0]) == len(classList): # 如果类别完全相同则停止继续划分
return classList[0]
if len(dataset[0]) == 1 or len(labels) == 0: # 遍历完所有特征时返回出现次数最多的类标签
return self.__majorityCnt(classList)
bestFeat = self.__chooseBestFeatureToSplit(dataset) # 选择最优特征
bestFeatLabel = labels[bestFeat] # 最优特征的标签
featLabels.append(bestFeatLabel)
myTree = {bestFeatLabel: {}} # 根据最优特征的标签生成树
del (labels[bestFeat]) # 删除已经使用特征标签
featValues = dataset[..., bestFeat] # 得到训练集中所有最优特征的属性值
uniqueVals = set(featValues) # 去掉重复的属性值
for value in uniqueVals: # 遍历特征,创建决策树。
subLabels = labels[:]
myTree[bestFeatLabel][value] = self.__createTree(self.__splitDataSet(dataset, bestFeat, value), subLabels, featLabels)
return myTree
def fit(self,dataset,feature_names):
if not os.path.exists(self.save_file):
featLabels = []
myTree = self.__createTree(dataset, feature_names, featLabels)
data_dict = {}
data_dict["myTree"] = myTree
# data_dict["featLabels"] = featLabels
# data_dict["feature_names"] = feature_names
# sava model
pickle.dump(data_dict,open(self.save_file,"wb"))
self.data_dict = pickle.load(open(self.save_file,"rb"))
# return myTree
def __predict(self, inputTree, featLabels, testVec):
firstStr = next(iter(inputTree)) # 获取决策树结点
secondDict = inputTree[firstStr] # 下一个字典
featIndex = featLabels.index(firstStr)
# classLabel = 0
for key in secondDict.keys():
if testVec[featIndex] != key:
key = testVec[featIndex]
# 找离该值最近的key
keys = list(secondDict.keys())
keys.append(key)
keys = sorted(keys)
index = keys.index(key)
if index ==0:
key = keys[index+1]
elif index == len(keys)-1:
key = keys[index-1]
else:
if abs(keys[index-1]-keys[index])<=abs(keys[index + 1]-keys[index]):
key = keys[index-1]
else:
key = keys[index + 1]
if isinstance(secondDict[key], dict):
classLabel = self.__predict(secondDict[key], featLabels, testVec)
else:
classLabel = secondDict[key]
return classLabel
def predict(self,X:np.array,feature_names):
# featLabels = self.data_dict["featLabels"]
featLabels = feature_names
inputTree = self.data_dict["myTree"]
labels = []
for x in X:
labels.append(self.__predict(inputTree, featLabels, x))
return np.asarray(labels)
def accuracy(self,y_true,y_pred):
return round(np.sum(y_pred==y_true)/len(y_true),5)
if __name__=="__main__":
# dataPath = "../../dataset/medical_record.data"
# dataPath = "../../dataset/loan.data"
# dataset,feature_names = loadData(dataPath,sep="\t")
# clf = DecisonTreeClassifierSelf()
# clf.fit(dataset, feature_names)
# y_pred = clf.predict(dataset[..., :-1], feature_names)
# print(y_pred)
#
# print(clf.accuracy(dataset[..., -1], y_pred))
X,y,feature_names = loadData2("../../dataset/iris.data")
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=40)
clf = DecisonTreeClassifierSelf()
clf.fit(np.hstack((X_train,y_train[...,None])), feature_names.copy())
y_pred = clf.predict(X_test,feature_names)
print(clf.accuracy(y_test, y_pred))
# 0.93333
# for y1,y2 in zip(y_pred,y_test):
# print(y1,"\t",y2)
# sklearn 的 DecisionTreeClassifier
clf = DecisionTreeClassifier()
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
print(accuracy_score(y_test,y_pred))
# 1.0
titanic分类
"""
Author:wucng
Time: 20200113
Summary: 决策树对titanic数据分类
源代码: https://github.com/wucng/MLAndDL
参考:https://cuijiahua.com/blog/2017/11/ml_3_decision_tree_2.html
"""
from math import log2
import numpy as np
import pandas as pd
from collections import Counter
import operator
import pickle,os
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
def loadData(dataPath,sep=","):
df = pd.read_csv(dataPath,sep=sep)
df = df.drop("ID",axis=1)
"""
# 文本量化
df.loc[df["病症"] == "打喷嚏", "病症"] = 0
df.loc[df["病症"] == "头痛", "病症"] = 1
df.loc[df["职业"] == "护士", "职业"] = 0
df.loc[df["职业"] == "农夫", "职业"] = 1
df.loc[df["职业"] == "建筑工人", "职业"] = 2
df.loc[df["职业"] == "教师", "职业"] = 3
df.loc[df["疾病"] == "感冒", "疾病"] = 0
df.loc[df["疾病"] == "过敏", "疾病"] = 1
# df.loc[df["疾病"] == "脑震荡", "疾病"] = 2
df.replace("脑震荡",2,inplace=True)
"""
return df.to_numpy(),list(df.columns)[:-1]
# 1.加载数据集(并做预处理)
def loadData2(dataPath: str) -> tuple:
# 如果有标题可以省略header,names ;sep 为数据分割符
df = pd.read_csv(dataPath, sep=",")
# 填充缺失值
df["Age"] = df["Age"].fillna(df["Age"].median())
df['Embarked'] = df['Embarked'].fillna('S')
# df = df.fillna(0)
# 数据量化
# 文本量化
df.replace("male", 0, inplace=True)
df.replace("female", 1, inplace=True)
df.loc[df["Embarked"] == "S", "Embarked"] = 0
df.loc[df["Embarked"] == "C", "Embarked"] = 1
df.loc[df["Embarked"] == "Q", "Embarked"] = 2
# 划分出特征数据与标签数据
X = df.drop(["PassengerId","Survived","Name","Ticket","Cabin"], axis=1) # 特征数据
y = df.Survived # or df["Survived"] # 标签数据
# 数据归一化
X = (X - np.min(X, axis=0)) / (np.max(X, axis=0) - np.min(X, axis=0))
# 使用sklearn方式
# X = MinMaxScaler().transform(X)
# 查看df信息
# df.info()
# df.describe()
return (X.to_numpy(), y.to_numpy(),list(X.columns))
class DecisonTreeClassifierSelf(object):
def __init__(self,save_file="./model.ckpt"):
self.save_file = save_file
# 计算经验熵
def __calEmpiricalEntropy(self,dataset):
label = dataset[..., -1]
label_dict = dict(Counter(label))
entropy = 0
for k, v in label_dict.items():
p = v / len(label)
entropy += p * log2(p)
entropy *= -1
return entropy
# 条件熵
def __calConditionalEntropy(self,dataset, feature_index=0):
label = dataset[..., -1]
select_feature = dataset[..., feature_index]
uniqueValue = set(select_feature)
conditionalEntropy = 0
# 根据唯一值划分成子集
for value in uniqueValue:
select_rows = select_feature == value
# subset_feature = select_feature[select_rows]
subset_label = label[select_rows]
conditionalEntropy += len(subset_label) / len(label) * self.__calEmpiricalEntropy(subset_label[..., None])
# conditionalEntropy *= -1 # 计算calEmpiricalEntropy 已乘上了-1
return conditionalEntropy
# 根据信息增益选择最佳的特征进行分裂生长
# 信息增益 = 经验熵-条件熵
def __chooseBestFeatureToSplit(self,dataset):
# 特征个数
numFeatures = dataset.shape[1] - 1 # 有列是label
baseEntropy = self.__calEmpiricalEntropy(dataset)
bestInfoGain = - 9999
bestFeature = -1
for i in range(numFeatures):
infoGain = baseEntropy - self.__calConditionalEntropy(dataset, i)
# print("第%d个特征的增益为%.3f" % (i, infoGain))
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def __majorityCnt(self,classList):
classCount = dict(Counter(classList))
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) # 根据字典的值降序排序
return sortedClassCount[0][0] # 返回classList中出现次数最多的元素
def __splitDataSet(self,dataSet, axis, value):
retDataSet = [] # 创建返回的数据集列表
for featVec in dataSet: # 遍历数据集
if featVec[axis] == value:
reducedFeatVec = featVec[:axis].tolist() # 去掉axis特征
reducedFeatVec.extend(featVec[axis + 1:]) # 将符合条件的添加到返回的数据集
retDataSet.append(reducedFeatVec)
return np.asarray(retDataSet)
# 函数说明:创建决策树
def __createTree(self,dataset, labels, featLabels):
"""
如果完全分成1个类别则为叶结点,停止生长
如果没有完全分成1个类别,但是没有可使用的特征,停止生长,并选择类别个数最多的作为叶结点
"""
classList = dataset[..., -1].tolist()
if classList.count(classList[0]) == len(classList): # 如果类别完全相同则停止继续划分
return classList[0]
if len(dataset[0]) == 1 or len(labels) == 0: # 遍历完所有特征时返回出现次数最多的类标签
return self.__majorityCnt(classList)
bestFeat = self.__chooseBestFeatureToSplit(dataset) # 选择最优特征
bestFeatLabel = labels[bestFeat] # 最优特征的标签
featLabels.append(bestFeatLabel)
myTree = {bestFeatLabel: {}} # 根据最优特征的标签生成树
del (labels[bestFeat]) # 删除已经使用特征标签
featValues = dataset[..., bestFeat] # 得到训练集中所有最优特征的属性值
uniqueVals = set(featValues) # 去掉重复的属性值
for value in uniqueVals: # 遍历特征,创建决策树。
subLabels = labels[:]
myTree[bestFeatLabel][value] = self.__createTree(self.__splitDataSet(dataset, bestFeat, value), subLabels, featLabels)
return myTree
def fit(self,dataset,feature_names):
if not os.path.exists(self.save_file):
featLabels = []
myTree = self.__createTree(dataset, feature_names, featLabels)
data_dict = {}
data_dict["myTree"] = myTree
# data_dict["featLabels"] = featLabels
# data_dict["feature_names"] = feature_names
# sava model
pickle.dump(data_dict,open(self.save_file,"wb"))
self.data_dict = pickle.load(open(self.save_file,"rb"))
# return myTree
def __predict(self, inputTree, featLabels, testVec):
firstStr = next(iter(inputTree)) # 获取决策树结点
secondDict = inputTree[firstStr] # 下一个字典
featIndex = featLabels.index(firstStr)
# classLabel = 0
for key in secondDict.keys():
if testVec[featIndex] != key:
key = testVec[featIndex]
# 找离该值最近的key
keys = list(secondDict.keys())
keys.append(key)
keys = sorted(keys)
index = keys.index(key)
if index ==0:
key = keys[index+1]
elif index == len(keys)-1:
key = keys[index-1]
else:
if abs(keys[index-1]-keys[index])<=abs(keys[index + 1]-keys[index]):
key = keys[index-1]
else:
key = keys[index + 1]
if isinstance(secondDict[key], dict):
classLabel = self.__predict(secondDict[key], featLabels, testVec)
else:
classLabel = secondDict[key]
return classLabel
def predict(self,X:np.array,feature_names):
# featLabels = self.data_dict["featLabels"]
featLabels = feature_names
inputTree = self.data_dict["myTree"]
labels = []
for x in X:
labels.append(self.__predict(inputTree, featLabels, x))
return np.asarray(labels)
def accuracy(self,y_true,y_pred):
return round(np.sum(y_pred==y_true)/len(y_true),5)
if __name__=="__main__":
# dataPath = "../../dataset/medical_record.data"
# dataPath = "../../dataset/loan.data"
# dataset,feature_names = loadData(dataPath,sep="\t")
# clf = DecisonTreeClassifierSelf()
# clf.fit(dataset, feature_names)
# y_pred = clf.predict(dataset[..., :-1], feature_names)
# print(y_pred)
#
# print(clf.accuracy(dataset[..., -1], y_pred))
dataPath = "../../dataset/titannic/train.csv"
X,y,feature_names = loadData2(dataPath)
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=40)
clf = DecisonTreeClassifierSelf()
clf.fit(np.hstack((X_train,y_train[...,None])), feature_names.copy())
y_pred = clf.predict(X_test,feature_names)
print(clf.accuracy(y_test, y_pred))
# 0.74444
# for y1,y2 in zip(y_pred,y_test):
# print(y1,"\t",y2)
# sklearn 的 DecisionTreeClassifier
clf = DecisionTreeClassifier()
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
print(accuracy_score(y_test,y_pred))
# 0.77777
