参考:
机器学习实战教程
机器学习实战书籍下载 - - 密码:qi7q
k-近邻算法
公式编辑器
drawio画流程图
百度思维导图

1.算法理论
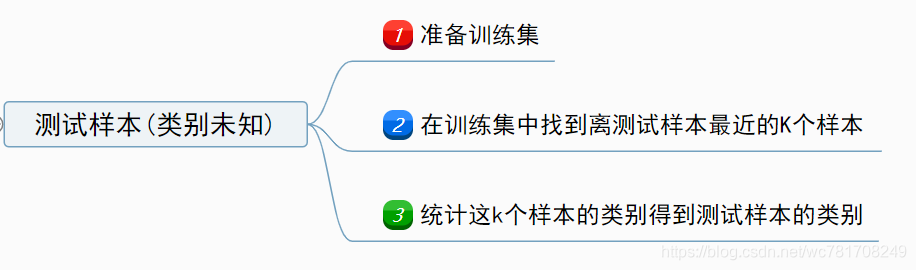
k-近邻算法 是一种特征搜索的方法(相似性搜索):
-
1、准备训练集
- 数据集量化 (将文本数据转成数字)
- 特征做归一化 (训练集与测试集都做)
-
2、每个测试样本与训练集中所有样本计算距离,按距离排序查找k个样本
- 可以使用的距离度量方法有:
欧式距离(常用)- 闵可夫斯基距离
- 曼哈顿距离
- 切比雪夫距离
- 马哈拉洛比斯距离
- 相似度度量
- 向量空间余弦相似度
- 皮尔森相关系数
- 可以使用的距离度量方法有:
-
3、统计这k个样本
- 分类
- 投票机制(少数服从多数)
- 回归
- 距离加权平均(类似于插值方式,
距离越小权重越大)
- 距离加权平均(类似于插值方式,
- 分类
2.实践
1.knn分类
"""
Author:wucng
Time: 20200107
Summary: 使用KNN(K-近领域)对iris数据分类
数据下载:https://archive.ics.uci.edu/ml/datasets.php
源代码: https://github.com/wucng/MLAndDL
"""
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn.neighbors import KNeighborsRegressor,KNeighborsClassifier
from sklearn.metrics import accuracy_score,auc
import pandas as pd
import numpy as np
import os
import time
# 1.加载数据集(并做预处理)
def loadData(dataPath: str) -> tuple:
# 如果有标题可以省略header,names ;sep 为数据分割符
df = pd.read_csv(dataPath, sep=",", header=-1,
names=["sepal_length", "sepal_width", "petal_length", "petal_width", "label"])
# 填充缺失值
df = df.fillna(0)
# 数据量化
# 文本量化
df.replace("Iris-setosa", 0, inplace=True)
df.replace("Iris-versicolor", 1, inplace=True)
df.replace("Iris-virginica", 2, inplace=True)
# 划分出特征数据与标签数据
X = df.drop("label", axis=1) # 特征数据
y = df.label # or df["label"] # 标签数据
# 数据归一化
X = (X - np.min(X, axis=0)) / (np.max(X, axis=0) - np.min(X, axis=0))
# 使用sklearn方式
# X = MinMaxScaler().transform(X)
# 查看df信息
# df.info()
# df.describe()
return (X.to_numpy(), y.to_numpy())
class KNN(object):
"""默认使用欧式距离"""
def __init__(self,X_train:np.asarray,X_test:np.asarray,
y_train:np.asarray,y_test:np.asarray=None,k:int=5):
self.X_train = X_train
self.X_test = X_test
self.y_train = y_train
self.y_test = y_test
self.k = k
self.__calDistance()
# 2.计算每个测试样本到训练样本的距离
def __calDistance(self):
result_dist = np.zeros([len(self.X_test),len(self.X_train)])
for i,data in enumerate(self.X_test):
data = np.tile(data,(len(self.X_train),1))
distance = np.sqrt(np.sum((data-self.X_train)**2,-1))
# result_dist[i] = sorted(distance) # 从小到大排序,先不排序,否则索引位置发生变化与标签对应不上
result_dist[i] = distance
self.result_dist = result_dist
# return result_dist
def __calDistance2(self):
result_dist = np.zeros([len(self.X_test), len(self.X_train)])
for i, data_test in enumerate(self.X_test):
dist = np.zeros((len(self.X_train),))
for j,data in enumerate(self.X_train):
dist[j] = (sum((data_test-data)**2))**0.5
result_dist[i] = dist
self.result_dist = result_dist
# return result_dist
# 3.根据距离确定类别
def predict(self):
"""k:为选取的最近样本点个数"""
# 距离从小到大排序获取索引
result_index = np.argsort(self.result_dist,-1)[:,:self.k]
# 将索引替换成对应的标签
y_pred = self.y_train[result_index]
# 统计每列次数出现最多对应的值即为预测标签
y_pred = [np.bincount(pred).argmax() for pred in y_pred]
self.y_pred = np.asarray(y_pred)
return self.y_pred
# 4.计算精度信息
def accuracy(self):
assert self.y_test is not None,print("error")
assert len(self.y_pred)==len(self.y_test),print("error")
return np.sum(self.y_pred==self.y_test)/len(self.y_test)
if __name__ =="__main__":
dataPath = "../../dataset/iris.data"
X,y = loadData(dataPath)
# print(X.shape,y.shape) # (150, 4) (150,)
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.2, random_state = 42)
start = time.time()
clf = KNN(X_train, X_test, y_train, y_test,3)
y_pred = clf.predict()
# print(y_pred)
print("cost time:%.6f(s) acc:%.3f"%(time.time()-start,clf.accuracy()))
# cost time:0.001994(s) acc:1.000
# ----------------------------------------------------------------------
# 使用sklearn的KNeighborsClassifier方法
start = time.time()
clf = KNeighborsClassifier(n_neighbors=3, weights='distance', algorithm='kd_tree').fit(X_train, y_train)
y_pred = clf.predict(X_test)
acc = accuracy_score(y_test,y_pred)
print("cost time:%.6f(s) error:%.3f" % (time.time() - start, acc))
# cost time:0.001994(s) error:1.000
2.knn回归
"""
Author:wucng
Time: 20200108
Summary: 使用KNN(K-近领域)对boston房价做回归预测
数据下载:https://archive.ics.uci.edu/ml/datasets.php
源代码: https://github.com/wucng/MLAndDL
"""
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn.neighbors import KNeighborsRegressor,KNeighborsClassifier
from sklearn.metrics import accuracy_score,auc
import pandas as pd
import numpy as np
import os
import time
# 1.加载数据集(并做预处理)
def loadData(dataPath: str) -> tuple:
with open(dataPath,"r") as fp:
lines = fp.readlines()
dataset=[]
i = 0
while i<len(lines):
line = lines[i]
i += 1
if line[0].isdigit(): # 数字开头
data1=list(map(float,line.strip().split(" ")))
line = lines[i]
i += 1
data2 = list(map(float, line.strip().split(" ")))
data1.extend(data2)
dataset.append(data1)
else:
continue
dataset = np.asarray(dataset)
# 拆分成训练集与标签
X,y = dataset[...,:-1],dataset[...,-1]
# 数据归一化
X = (X - np.min(X, axis=0)) / (np.max(X, axis=0) - np.min(X, axis=0))
# 使用sklearn方式
# X = MinMaxScaler().transform(X)
return (X,y)
class KNN(object):
"""默认使用欧式距离"""
def __init__(self,X_train:np.asarray,X_test:np.asarray,
y_train:np.asarray,y_test:np.asarray=None,k:int=5):
self.X_train = X_train
self.X_test = X_test
self.y_train = y_train
self.y_test = y_test
self.k = k
self.__calDistance()
# 2.计算每个测试样本到训练样本的距离
def __calDistance(self):
result_dist = np.zeros([len(self.X_test),len(self.X_train)])
for i,data in enumerate(self.X_test):
data = np.tile(data,(len(self.X_train),1))
distance = np.sqrt(np.sum((data-self.X_train)**2,-1))
# result_dist[i] = sorted(distance) # 从小到大排序,先不排序,否则索引位置发生变化与标签对应不上
result_dist[i] = distance
self.result_dist = result_dist
# return result_dist
def __calDistance2(self):
result_dist = np.zeros([len(self.X_test), len(self.X_train)])
for i, data_test in enumerate(self.X_test):
dist = np.zeros((len(self.X_train),))
for j,data in enumerate(self.X_train):
dist[j] = (sum((data_test-data)**2))**0.5
result_dist[i] = dist
self.result_dist = result_dist
# return result_dist
# 3.根据距离确定类别
def predict(self):
"""k:为选取的最近样本点个数"""
# 距离从小到大排序获取索引
result_index = np.argsort(self.result_dist,-1)[:,:self.k]
# 将索引替换成对应的标签
y_pred = self.y_train[result_index]
# 做距离加权平均得到预测值
# 获取对应的距离值
dists = self.result_dist.copy()
dists.sort(-1)
dists =dists[...,:self.k]
# 根据距离做距离加权平均(距离越近权重越大)
preds = []
for pred,dist in zip(y_pred,dists):
dist = np.exp(dist*(-1)) # 使用 e^(-x)
preds.append(np.sum(pred*dist/np.sum(dist)))
# 假设满足正太分布 f(x) = 1/(sqrt(2*pi)*sigma)*e^(-(x-mu)^2/(2*sigma^2))
# 取标准正太分布
# dist = 1/(np.sqrt(2*np.pi))*np.exp(-(dist)**2/2)
# preds.append(np.sum(pred * dist / np.sum(dist)))
self.y_pred = np.asarray(preds)
return self.y_pred
# 4.计算精度信息
def error(self):
assert self.y_test is not None,print("error")
assert len(self.y_pred)==len(self.y_test),print("error")
return np.sum((self.y_pred-self.y_test)**2)/len(self.y_test)
if __name__ =="__main__":
dataPath = "../../dataset/boston.txt"
X,y = loadData(dataPath)
print(X.shape,y.shape) # (506, 13) (506,)
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.2, random_state = 42)
start = time.time()
clf = KNN(X_train, X_test, y_train, y_test,3)
y_pred = clf.predict()
# print(y_pred)
print("cost time:%.6f(s) error:%.3f"%(time.time()-start,clf.error()))
# cost time:0.012968(s) error:19.994
# ----------------------------------------------------------------------
# 使用sklearn的KNeighborsRegressor方法
start = time.time()
clf = KNeighborsRegressor(n_neighbors=3,weights='distance',algorithm='kd_tree').fit(X_train,y_train)
y_pred = clf.predict(X_test)
error = np.sum((y_pred-y_test)**2)/len(y_test)
print("cost time:%.6f(s) error:%.3f"%(time.time()-start,error))
# cost time:0.004056(s) error:18.905
总结
-
1、
KNN分类,如果按距离选出的K个样本中,有一个被噪声污染(类别不对),但是其他K-1是没问题,还是能保证正确类别大于错误类别,因此能够正确分类(KNN分类对噪声点不太很敏感) -
2、
KNN回归,如果按距离选出的K个样本中,有一个被噪声污染(其对应的输出值偏差很大),而且这个噪声离我们要预测的样本距离又很近,那么会造成其占的比重很大,导致最终的预测值偏移过大,因此KNN回归对噪声点很敏感 -
3、如果数据量变大,特征维度变大,那么会导致
KNN搜索变得非常慢扫描二维码关注公众号,回复: 8756832 查看本文章
- 改进方式 :可以使用
kd_tree建立搜索空间
- 改进方式 :可以使用
-
4、KNN分类可以应用于特征比对(优点不需要训练,完全依靠底库(训练样本)的特征)
- 人脸比对,获取一张新人脸图片(要预测的样本)与底库(训练样本)做比对
- 图片搜索等
